728x90
[SQLD] SQL 최적화의 원리
① 옵티마이저(Optimizer)의 실행 계획
옵티마이저(Optimizer)
- SQL의 실행 계획을 수립하고 SQL을 실행하는 데이터베이스 관리 시스템의 소프트웨어
- 동일한 결과가 나오는 SQL도 어떻게 실행하느냐에 따라서 성능이 달라진다.
- 옵티마이저의 실행 계획은 SQL 성능에 아주 중요한 역할을 한다.
옵티마이저 특징
- 옵티마이저는 데이터 딕셔너리(Data Dictionary)에 있는 오브젝트 통계, 시스템 통계 등의 정보를 사용해서 예상되는 비용을 산정한다.
- 옵티마이저는 여러 개의 실행 계획 중에서 최저비용을 가지고 있는 계획을 선택해서 SQL을 실행한다.
옵티마이저의 필요성
- SQL 개발자가 작성한 SQL문을 어떻게 실행하느냐에 따라 성능이 달라진다.
예
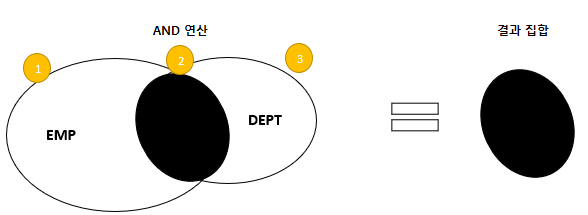
- 먼저 <EMP> 테이블을 실행하고, <EMP> 테이블에서 찾은 행과 동일한 것을 <DEPT> 테이블에서 찾는다. 그리고 최종 결과 집합을 인출한다.
- 건수가 많은 <EMP> 테이블을 먼저 읽고, <DEPT> 테이블을 읽으면 불필요하게 비교 횟수가 증가하게 된다.
- <DEPT> 테이블을 먼저 읽고, <EMP> 테이블을 읽게되면 비교 횟수를 줄일 수 있다.
- 위의 예는 AND 조건이므로, 작은 집합을 먼저 읽어도 큰 집합을 먼저 읽는 것과 동일한 결과가 나오게 된다.
- 옵티마이저는 이러한 실행 계획을 수립하는 것이며, 만약 옵티마이저가 비효율적으로 실행 계획을 수립하면, SQL 개발자는 SQL을 개선해야 한다.
- 이때 옵티마이저에게 실행 계획을 변경하도록 요청할 수 있는데, 이 때 힌트(HINT)를 사용한다.
옵티마이저 실행 계획 확인
- 옵티마이저는 SQL 실행 계획을 PLAN_TABLE에 저장한다.
- 그래서 SQL 개발자는 PLAN_TABLE을 조회해서 실행 계획을 확인할 수 있다.
DESC PLAN_TABLE;
② 옵티마이저 종류
옵티마이저의 실행 방법
- 개발자가 SQL을 실행하면 파싱(Parsing)을 실행해서 SQL의 문법 검사 및 구문 분석을 수행한다.
- 구문 분석이 완료되면, 옵티마이저가 규칙 기반 혹은 비용 기반으로 실행 계획을 수립한다.
- 옵티마이저는 기본적으로 비용 기반 옵티마이저를 사용해서 실행 계획을 수립한다.
- 비용 기반 옵티마이저는 통계 정보를 활용해서 최적의 실행 계획을 수립한다.
- 실행 계획 수립이 완료되면 최종적으로 SQL을 실행하고, 실행이 완료되면 데이터를 인출(Fetch)한다.

옵티마이저 엔진
| 옵티마이저 | 설명 |
| Query Transformer | - SQL문을 효율적으로 실행하기 위해서 옵티마이저가 변환한다. - SQL이 변환되어도 그 결과는 동일하다. |
| Estimator | - 통계 정보를 사용해서 SQL 실행 비용을 계산한다. - 총비용은 최적의 실행 계획을 수립하기 위해서 구한다. |
| Plan Generator | SQL을 실행할 실행 계획을 수립한다. |
규칙 기반 옵티마이저(Rule Base Optimizer)
- 15개의 우선순위를 기준으로 실행 계획을 수립한다.
- 최신 Oracle 버전은 규칙 기반 옵티마이저 보다 비용 기반 옵티마이저를 기본적으로 사용한다.
| 우선순위 | 설명 |
| 1 | ROWID를 사용한 단일 행인 경우 |
| 2 | 클러스터 조인에 의한 단일 행인 경우 |
| 3 | 유일하거나, 기본키(Primary Key)를 가진 해시 클러스터 키에 의한 단일 행인 경우 |
| 4 | 유일하거나 기본키(Primary Key)에 의한 단일 행인 경우 |
| 5 | 클러스터 조인인 경우 |
| 6 | 해시 클러스터 조인인 경우 |
| 7 | 인덱스 클러스터 키인 경우 |
| 8 | 복합 칼럼 인덱스인 경우 |
| 9 | 단일 칼럼 인덱스인 경우 |
| 10 | 인덱스가 구성된 칼럼에서 제한된 범위를 검색하는 경우 |
| 11 | 인덱스가 구성된 칼럼에서 무제한 범위를 검색하는 경우 |
| 12 | 정렬-병합(Sort Merge) 조인인 경우 |
| 13 | 인덱스가 구성된 칼럼에서 MAX 혹은 MIN을 구하는 경우 |
| 14 | 인덱스가 구성된 칼럼에서 ORDER BY를 실행하는 경우 |
| 15 | 전체 테이블을 스캔(FULL TABLE SCAN)하는 경우 |
예제
- 규칙 기반 옵티마이저에서 우선순위 1순위인 ROWID를 사용한 조회를 확인해 보면 다음과 같다.
SELECT /*+ RULE */ * FROM EMP /* 규칙 기반 옵티마이저를 사용하도록 힌트를 사용 */
WHERE ROWID='AAAHYhAABAAALNJAAN'; /* ROWID 값으로 행을 검색 */| TABLE ACCESS BY USER ROWID TABLE TEST.EMP |
- 실행 계획을 확인한 결과 <EMP> 테이블을 ROWID로 조회하였다.
비용 기반 옵티마이저(Cost Base Optimizer)
- 오브젝트 통계 및 시스템 통계를 사용해서 총비용을 계산한다.
- 총비용 : SQL문을 실행하기 위해 예상되는 소요 시간 혹은 자원의 사용량
- 총비용이 적은 쪽으로 실행 계획을 수립한다.
- 단, 비용 기반 옵티마이저에서 통계 정보가 부적절한 경우, 성능 저하가 발생할 수 있다.
③ 인덱스(Index)
인덱스(Index)
- 데이터를 빠르게 검색할 수 있는 방법을 제공한다.
- 인덱스 키(예: EMPNO)로 정렬(SORT)되어 있기 때문에, 원하는 데이터를 빠르게 조회한다.
- 오름차순(ASCENDING) 및 내림차순(DESCENDING) 탐색이 가능하다.
- 하나의 테이블에 여러 개의 인덱스를 생성할 수 있고, 하나의 인덱스는 여러 개의 칼럼으로 구성될 수 있다.
- 테이블을 생성할 때 기본키(Primary Key)는 자동으로 인덱스가 만들어지고 인덱스의 이름은 SYSXXXX이다.
인덱스의 구조
- Root Block
- 인덱스 트리에서 최상위 노드
- Branch Block
- 다음 단계의 주소를 가지고 있는 포인터(Pointer)로 되어 있다.
- Leaf Block
- 인덱스 키와 ROWID로 구성되고, 인덱스 키는 정렬되어서 저장되어 있다.
- 양방향 연결 리스트(Double Linked List) 형태로 되어 있어서 양방향 탐색이 가능하다.
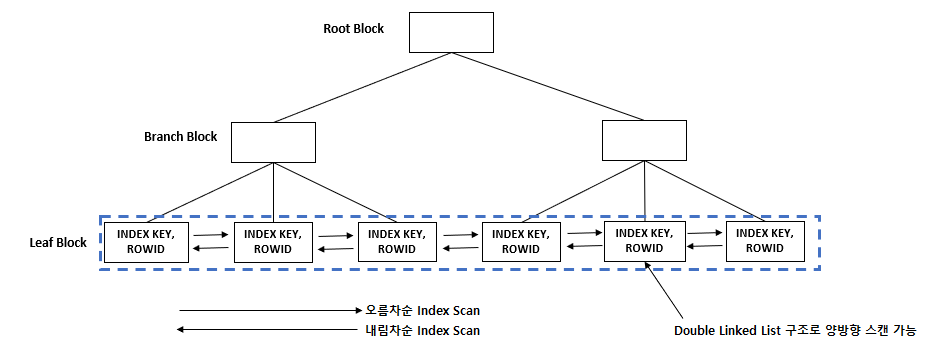
- 인덱스를 사용해서 테이블 스캔(TABLE SCAN)

- Leaf Block에서 인덱스 키를 읽으면 ROWID를 사용해서 <EMP> 테이블의 행을 직접 읽을 수 있다.
인덱스 생성
- 인덱스는 CREATE INDEX 문을 사용해서 생성이 가능하다.
- 인덱스는 1개 이상의 칼럼을 사용해서 생성할 수 있다.
- 인덱스 키는 기본적으로 오름차순(ASC)으로 정렬하고, 'DESC' 구를 포함하면 내림차순으로 정렬한다.
사용 예
CREATE INDEX IND_EMP ON /* IND : 인덱스 이름 */
EMP (ENAME ASC, SAL DESC); /* ENAME은 오름차순, SAL은 내림차순으로 인덱스 생성 */- ENAME의 ASC 구는 생략이 가능하다.
인덱스 스캔(Index Scan)
(1) 인덱스 유일 스캔(Index Unique Scan)
- 인덱스의 키 값이 중복되지 않는 경우, 해당 인덱스를 사용할 때 발생된다.
- 예) EMPNO가 중복되지 않는 경우, 특정 하나의 EMPNO를 조회한다.
사용 예
SELECT *
FROM EMP
WHERE EMPNO=1000; /* EMPNO가 1000인 것을 조회 */| INDEX UNIQUE SCAN INDEX (UNIQUE) TEST.SYS_C007961 |
- EMPNO는 중복되지 않으므로 INDEX UNIQUE SCAN이 발생한다.
(2) 인덱스 범위 스캔(Index Range Scan)
- SELECT 문에서 특정 범위를 조회하는 WHERE 문을 사용할 경우 발생한다.
- 예) LIKE, BETWEEN
- 데이터 양이 적은 경우에는 인덱스 자체를 실행하지 않고, TABLE FULL SCAN이 될 수 있다.
- 인덱스의 Leaf Block의 특정 범위를 스캔하는 것
사용 예
SELECT EMPNO
FROM EMP
WHERE EMPNO >= 1000;| INDEX RANGE SCAN INDEX (UNIQUE) TEST.SYS_C007961 |
- INDEX RANGE SCAN은 인덱스의 특정 범위를 스캔한 것을 의미한다.
(3) 인덱스 전체 스캔(Index Full Scan)
- 인덱스에서 검색되는 인덱스 키가 많은 경우에 Leaf Block의 처음부터 끝까지 전체를 읽어 들인다.
- High Watermark
- 인덱스 전체 스캔은 테이블의 데이터를 모두 읽은 것을 의미한다.
- 테이블을 읽을 때, High Watermark 이하까지만 인덱스 전체 스캔을 수행한다.
- 테이블에 데이터가 저장된 블록에서 최상위 위치를 의미하고, 데이터가 삭제되면 High Watermark가 변경된다.
- 인덱스 전체 스캔은 테이블의 데이터를 모두 읽은 것을 의미한다.
사용 예
SELECT ENAME, SAL
FROM EMP
WHERE ENAME LIKE '%' AND SAL > 0;| INDEX FULL SCAN INDEX EST.IND_EMP |
- INDEX FULL SCAN은 인덱스의 Leaf Block을 처음부터 끝까지 모두 스캔한 것을 의미한다.
④ 실행 계획(Execution Plan)
예
다음은 <EMP> 테이블과 <DEPT> 테이블을 조인하고, <EMP> 테이블의 DEPTNO 번호가 10번인 것을 조회하는 SQL이다.
SELECT *
FROM EMP, DEPT
WHERE EMP.DEPTNO=DEPT.DEPTNO
AND EMP.DEPTNO=10;| SELECT STATEMENT ALL_ROWS // ALL_ROWS : 비용 기반 옵티마이저를 의미 Cost: 3 Bytes: 80 Cardinality: 2 |
| 4 NESTED LOOPS Cost: 3 Bytes: 80 Cardinality: 2 2 ■ TABLE ACCESS BY INDEX ROWID TABLE TEST.DEPT Cost: 1 Bytes: 12 Cardinality: 1 1 ■ INDEX UNIQUE SCAN INDEX (UNIQUE) TEST.SYS_C007959 Cost: 0 Cardinality: 1 3 ■ TABLE ACCESS FULL TABLE TEST.EMP Cost: 2 Bytes: 56 Cardinality: 2 |
- 위의 SQL문의 실행 계획을 읽는 방법은 위에 나와 있는 번호 순서대로 읽으면 된다.
- 1번
- <DEPT> 테이블의 SYS_C007959 인덱스를 유일하게 조회(INDEX UNIQUE SCAN)하였다.
- 2번
- INDEX에서 <DEPT> 테이블 ROWID를 사용해서 조회하였다.
- 3번
- <EMP> 테이블을 전체 스캔(FULL SCAN) 하였다.
- 4번
- <DEPT> 테이블과 <EMP> 테이블을 Nested Loop 방식의 조인을 해서 최종 결과를 만들어 냈다.
- 1번
- Nested Loop 방식의 조인
- <DEPT> 테이블에서 먼저 데이터를 찾고, 그 다음 <EMP> 테이블을 찾는 것을 의미한다.
- 이러한 것을 Random Access 라고 한다.
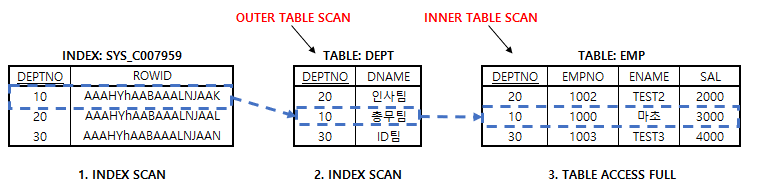
- 위의 SQL 실행 흐름도를 보면, INDEX를 검색하고 ROWID를 사용해서 <DEPT> 테이블을 조회하는 것을 알 수 있다.
- 이때 먼저 조회되는 테이블을, 외부 테이블(Outer Table) 이라고 하고, 그 다음에 조회되는 테이블을 내부 테이블(Inner Table) 이라고 한다.
⑤ 옵티마이저 조인(Optimizer Join)
Nested Loop 조인
- 하나의 테이블에서 데이터를 먼저 찾고 그 다음 테이블을 조인하는 방식으로 실행됨.
- 먼저 조인되는 테이블을 외부 테이블(Outer Table)이라고 하고, 그 다음에 조회되는 테이블을 내부 테이블(Inner Table)이라고 한다.
- 외부 테이블(선행 테이블)의 크기가 작은 것을 먼저 찾는 것이 중요하다.
- 그래야 데이터가 스캔되는 범위를 줄일 수 있기 때문이다.
- RANDOM ACCESS가 발생하는데, RANDOM ACCESS가 많이 발생하면 성능 지연이 발생한다.
- 그러므로 RANDOM ACCESS의 양을 줄여야 성능이 향상된다.
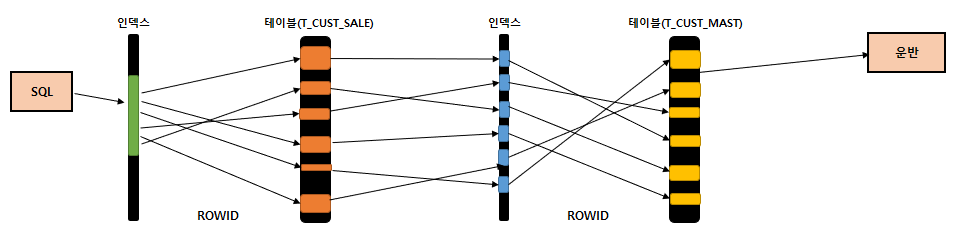
- T_CUST_SALE의 인덱스를 먼저 검색하고, T_CUS_SALE 인덱스에 있는 ROWID를 사용해서 T_CUST_SALE 테이블을 읽는다.
- 그 다음, T_CUST_SALE에서 T_CUST_MAST 테이블의 인덱스를 찾는다.
- 이 부분을 RANDOM ACCESS 라고 한다.
- T_CUST_MAST 인덱스를 사용해서 다시 T_CUST_MAST 테이블에서 데이터를 찾는다.
- 여기까지 실행되면 모든 데이터를 다 찾은 것이다.
- 그 다음은 인출(Fetch)을 실행해서 전송한다.
SELECT /*+ ordered use_nl(b) */ * /* use_nl 힌트 : Nested Loop 조인을 실행 */
FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
AND a.DEPTNO = 10;| SELECT STATEMENT ALL_ROWS Cost: 4 Bytes: 80 Cardinality: 2 |
| 3 NESTED LOOPS Cost: 4 Bytes: 80 Cardinality: 2 1 ■ TABLE ACCESS FULL TABLE TEST.EMP Cost: 2 Bytes: 56 Cardinality: 2 2 ■ TABLE ACCESS FULL TABLE TEST.DEPT Cost: 1 Bytes: 12 Cardinality: 1 |
- use_nl 힌트를 사용해서 의도적으로 Nested Loop 조인을 실행하였다.
- <EMP> 테이블을 먼저 FULL SCAN 하고, 그 다음 <DEPT> 테이블을 FULL SCAN 하여 Nested Loop 조인을 실행하였다.
- ordered 힌트
- FROM 절에 나오는 테이블 순서대로 조인을 하게 하는 것
- 혼자 사용되지 않고 use_nl, use_merge, use_hash 힌트와 함께 사용
Sort Merge 조인
- 2개의 테이블을 SORT_AREA 라는 메모리 공간에 모두 로딩(Loading)하고 정렬(SORT)을 수행한다.
- 2개의 테이블에 대해서 정렬(SORT)이 완료되면, 2개의 테이블을 병합(Merge)한다.
- 정렬(SORT)이 발생하기 때문에 데이터양이 많아지면 성능이 떨어지게 된다.
- 정렬 데이터양이 너무 많으면 정렬은 임시 영역에서 수행된다.
- 임시 영역은 디스크에 있기 때문에 성능이 급격히 떨어진다.
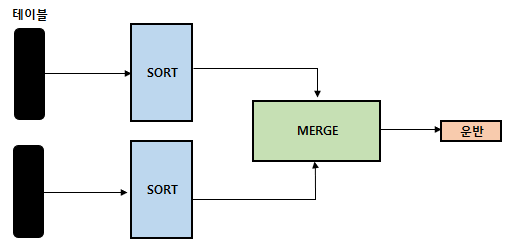
SELECT /*+ ordered use_merge(b) */ * /* 힌트를 사용해서 의도적으로 SORT MERGE 조인 수행 */
FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
AND a.DEPTNO = 10;| SELECT STATEMENT ALL_ROWS Cost: 4 Bytes: 80 Cardinality: 2 |
| 5 MERGE JOIN Cost: 4 Bytes: 80 Cardinality: 2 1 ■ TABLE ACCESS FULL TABLE TEST.EMP Cost: 2 Bytes: 56 Cardinality: 2 4 SORT JOIN Cost: 2 Bytes: 12 Cardinality: 1 3 ■ TABLE ACCESS BY INDEX ROWID TABLE TEST.DEPT Cost: 1 Bytes: 12 Cardinality: 1 2 ■ INDEX UNIQUE SCAN INDEX (UNIQUE) TEST.SYS_C007959 Cost: 0 Cardinality: 1 |
- use_merge 힌트를 사용하여 SORT MERGE 조인을 할 수 있다.
- 단, use_merge 힌트는 ordered 힌트와 같이 사용해야 한다.
Hash 조인
- 2개의 테이블 중에서 작은 테이블을 HASH 메모리에 로딩하고, 2개의 테이블의 조인 키를 사용해서 해시 테이블을 생성한다.
- 해시 함수를 사용해서 주소를 계산하고, 해당 주소를 사용해서 테이블을 조인하기 때문에 CPU 연산을 많이 한다.
- 특히, Hash 조인 시에는 선행 테이블이 충분히 메모리에 로딩되는 크기여야 한다.
SELECT /*+ ordered use_hash(b) */ * /* 힌트를 사용해서 의도적으로 Hash 조인 수행 */
FROM EMP a, DEPT b
WHERE a.DEPTNO = b.DEPTNO
AND a.DEPTNO = 10;| SELECT STATEMENT ALL_ROWS Cost: 4 Bytes: 80 Cardinality: 2 |
| 4 HASH JOIN Cost: 4 Bytes: 80 Cardinality: 2 1 ■ TABLE ACCESS FULL TABLE TEST.EMP Cost: 2 Bytes: 56 Cardinality: 2 3 ■ TABLE ACCESS BY INDEX ROWID TABLE TEST.DEPT Cost: 1 Bytes: 12 Cardinality: 1 2 ■ INDEX UNIQUE SCAN INDEX (UNIQUE) TEST.SYS_C007959 Cost: 0 Cardinality: 1 |
728x90
'Certificate > SQLD' 카테고리의 다른 글
| [SQLD] 실전 문제 : SQL 기본 ② (0) | 2022.06.25 |
|---|---|
| [SQLD] 실전 문제 : SQL 기본 ① (1) | 2022.06.25 |
| [SQLD] 실전 문제 : 데이터 모델과 성능 (0) | 2022.06.23 |
| [SQLD] 실전 문제 : 데이터 모델링의 이해 (0) | 2022.06.21 |
| [SQLD] SQL 활용 (0) | 2022.01.19 |
| [SQLD] SQL 기본 (0) | 2022.01.18 |
| [SQLD] 데이터 모델과 성능 (0) | 2022.01.17 |
| [SQLD] 데이터 모델링(Data Modeling) (0) | 2022.01.14 |

