728x90
[SQLD] 데이터 모델과 성능
① 정규화
정규화(Normalization)
- 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법이며, 데이터를 분해하는 과정
- 데이터 중복을 제거하고 데이터 모델의 독립성을 확보하기 위한 방법
- 정규화를 수행하면 비즈니스에 변화가 발생하여도 데이터 모델의 변경을 최소화할 수 있다.
- 정규화는 제1정규화부터 제5정규화까지 있지만, 실질적으로는 제3정규화까지만 수행한다.
예) 정규화를 하지 않아 이상현상이 존재하는 모델
- 위의 테이블은 정규화를 수행하지 않은 것으로, <부서> 테이블과 <직원> 테이블을 하나로 합쳐둔 것이다.
- 새로운 직원이 추가 되는 경우
- <부서> 정보가 없으면 부서코드를 임의의 값으로 넣어야 한다.
- 불필요한 정보가 함께 추가됨.
- <부서> 정보가 없으면 부서코드를 임의의 값으로 넣어야 한다.
- 새로운 '총무부'가 추가 되어야 할 경우
- 사원 정보가 없기 때문에 임의의 값으로 사원번호를 입력하거나 추가할 수 없게 된다.
- 새로운 직원이 추가 되는 경우
- 이러한 문제를 이상현상(Anomaly)이라고 한다.

- 정규화된 모델은 테이블이 분해된다.
- 테이블이 분해되면, <직원> 테이블과 <부서> 테이블 간에 부서코드로 조인(Join)을 수행하여 하나의 합집합으로 만들 수도 있다.
- 정규화를 수행하면, 불필요한 데이터를 입력하지 않아도 되기 때문에 중복 데이터가 제거된다.
정규화 절차
| 정규화 절차 | 설명 |
| 제1정규화 | - 속성(Attribute)의 원자성을 확보한다. - 기본키(Primary Key)를 설정한다. |
| 제2정규화 | 기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거(분해)한다. |
| 제3정규화 | - 기본키를 제외한 칼럼 간에 종속성을 제거한다. - 즉, 이행 함수 종속성을 제거한다. |
| BCNF | 기본키를 제외하고 후보키가 있는 경우, 후보키가 기본키를 종속시키면 분해한다. |
| 제4정규화 | 여러 칼럼들이 하나의 칼럼을 종속시키는 경우, 분해하여 다중값 종속성을 제거한다. |
| 제5정규화 | 조인에 의해서 종속성이 발생하는 경우 분해한다. |
함수적 종속성(Functional Dependency)
(1) 제1정규화
- 정규화는 함수적 종속성을 근거로 한다.
- 함수적 종속성 : X→Y이면 Y는 X에 함수적으로 종속됨.
- 함수적 종속성은 X가 변화하면 Y도 변화하는지 확인한다.
- 예) 회원ID가 변화하면 이름도 변경됨.
- 회원ID : 기본키
- 회원ID가 이름을 함수적으로 종속함.
- 예) 회원ID가 변화하면 이름도 변경됨.
- 함수적 종속성은 X가 변화하면 Y도 변화하는지 확인한다.
- 함수적 종속성 : X→Y이면 Y는 X에 함수적으로 종속됨.
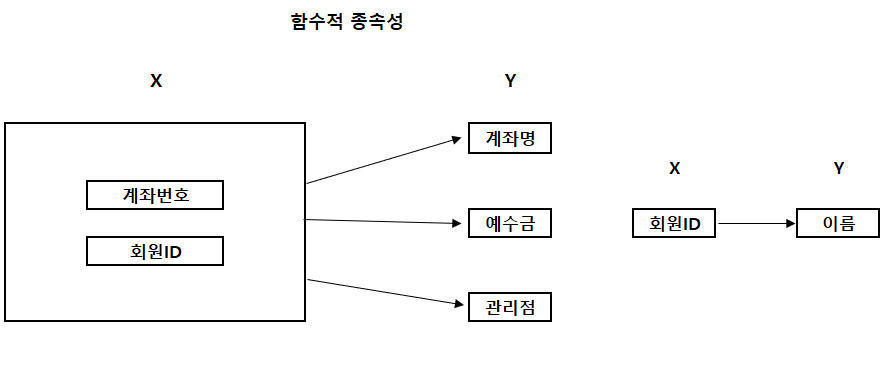
예) 완전 함수 종속성

- <계좌> 테이블 <X>가 <Y>의 칼럼들을 함수적으로 종속하고 있다.
- <X>는 계좌번호 하나만으로는 유일성을 만족하지 못한다고 가정한 것이다.
- 그래서 계좌번호와 회원ID를 기본키로 잡은 것이다.
- 이처럼 기본키를 잡는 것이 제1정규화이다.
- <X>는 계좌번호 하나만으로는 유일성을 만족하지 못한다고 가정한 것이다.
(2) 제2정규화
- 부분 함수 종속성은 기본키가 2개 이상의 칼럼으로 이루어진 경우에 발생한다.
- 기본키가 하나의 컬럼으로 이루어지면 제2정규화는 생략한다.
예) 제2정규화 대상

- 기본키에 있는 회원ID가 변경되면 이름이 변경된다.
- 회원ID가 이름을 함수적으로 종속하고 있다.
- 바로 이러한 경우를 부분 함수 종속성이라고 한다.
- 부분 함수 종속성이 발생하면 분해를 해야한다.
- 부분 함수 종속성을 제거하면 위와 같다.
- 새로운 테이블이 도출되고, 회원ID가 기본키가 된다.
(3) 제3정규화
- 제3정규화는 이행 함수 종속성을 제거한다.
- 이행 함수 종속성 : 기본키를 제외하고 칼럼 간에 종속성이 발생하는 것
- 제3정규화는 제1정규화와 제2정규화를 수행한 다음에 해야 한다.
예) 이행 함수 종속성
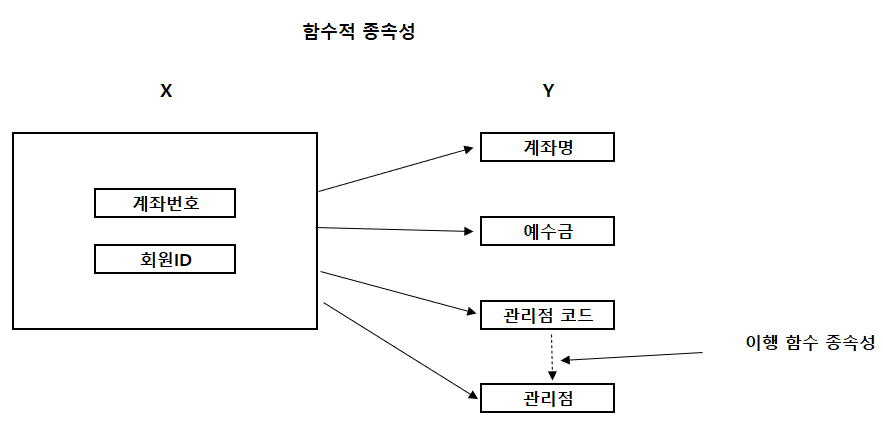
- 위처럼 관리점이 관리점 코드에 종속되는 것을 이행 함수 종속성이다.
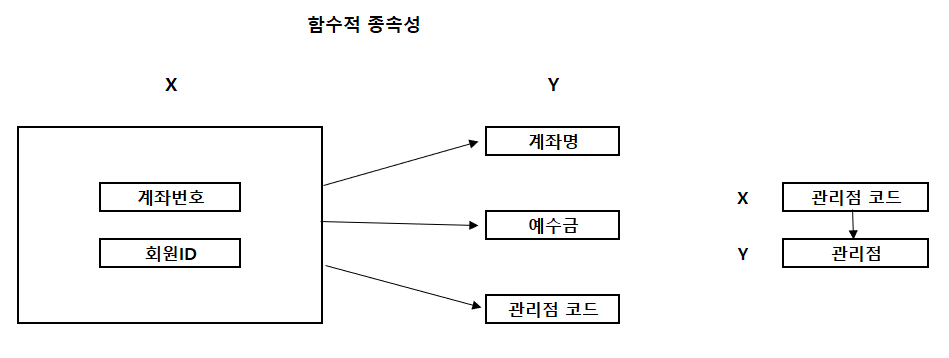
- 제3정규화를 수행하면 위처럼 <관리점> 테이블이 도출되고, 관리점 코드가 기본키가 된다.
(4) BCNF(Boyce-Codd Normal Form)
- BCNF는 복수의 후보키가 있고, 후보키들이 복합 속성이어야 하며, 서로 중첩되어야 한다.
예) BCNF 대상
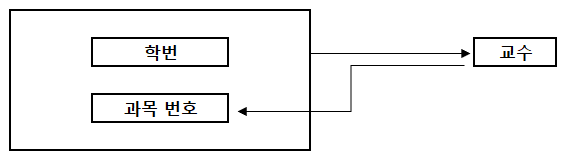
- 기본키(학번, 과목 번호)가 교수를 함수적으로 종속하고 있다.
- 이때 교수가 후보키(최소성과 유일성을 만족)이고, 교수가 과목 번호를 함수적으로 종속하는 경우 분해가 일어난다.
- 즉, 위와 같은 경우 <교수> 테이블을 새롭게 만들고, 기본키는 교수로 하고 칼럼은 과목 번호가 된다.
- 이러한 작업을 BCNF 라고 한다.
- 즉, 위와 같은 경우 <교수> 테이블을 새롭게 만들고, 기본키는 교수로 하고 칼럼은 과목 번호가 된다.
- 이때 교수가 후보키(최소성과 유일성을 만족)이고, 교수가 과목 번호를 함수적으로 종속하는 경우 분해가 일어난다.
정규화 예제
| 제품번호 | 제품명 | 재고수량 | 주문번호 | 수출 여부 | 고객 번호 | 사업자 번호 |
우선순위 | 주문 수량 |
| 1001 | 모니터 | 1,990 | AB345 | X | 4520 | 398201 | 1 | 150 |
| 1001 | 모니터 | 1,990 | AD347 | Y | 2341 | - | 3 | 600 |
| 1007 | 마우스 | 9,702 | CA210 | X | 3280 | 200212 | 8 | 1200 |
| 1007 | 마우스 | 9,702 | AB345 | X | 4520 | 398201 | 1 | 300 |
| 1007 | 마우스 | 9,702 | CB230 | X | 2341 | 563892 | 3 | 390 |
| 1201 | 스피커 | 2,108 | CB231 | Y | 8320 | - | 2 | 80 |
(1) 제1정규화
- 속성을 보고 1개의 속성으로 유일성을 만족할 수 있는지 확인한다.
- 제품번호는 1001, 1007 등이 2번 이상 나오므로 중복되고, 주문번호 또한 AB345 가 2번 나와서 중복된다.
- 결과적으로 1개의 속성으로는 유일성을 만족할 수 없다.
- 그러므로 2개의 조합으로 유일성을 만족할 수 있는지 확인해 보아야 한다.
- 결과적으로 1개의 속성으로는 유일성을 만족할 수 없다.
- 제품번호 + 주문번호가 식별자가 되면 엔티티의 유일성을 만족하게 된다.
- 제1정규화는 이러한 식별자를 찾는 과정이며 여기까지 수행하면 된다.
예) 제1정규화 결과
| 제품번호 | 제품명 | 재고수량 | 주문번호 | 수출 여부 | 고객 번호 | 사업자 번호 |
우선순위 | 주문 수량 |
| 1001 | 모니터 | 1,990 | AB345 | X | 4520 | 398201 | 1 | 150 |
| 1001 | 모니터 | 1,990 | AD347 | Y | 2341 | - | 3 | 600 |
| 1007 | 마우스 | 9,702 | CA210 | X | 3280 | 200212 | 8 | 1200 |
| 1007 | 마우스 | 9,702 | AB345 | X | 4520 | 398201 | 1 | 300 |
| 1007 | 마우스 | 9,702 | CB230 | X | 2341 | 563892 | 3 | 390 |
| 1201 | 스피커 | 2,108 | CB231 | Y | 8320 | - | 2 | 80 |
(2) 제2정규화
- 제2정규화는 기본키가 2개 이상인 경우 대상이 된다.
- 기본키가 제품 번호 + 주문번호이므로 제2정규화 대상이다.
- 제2정규화는 모든 속성(제품명, 재고 수량, 수출 여부 등)이 식별자에 종속해야 하며, 그렇지 않은 경우에는 분해한다.
- 확인 방법 : 제1정규화와 마찬가지로 중복 확인
예) 제2정규화 확인 (1)
| 제품번호 | 제품명 | 재고 수량 |
| 1001 | 모니터 | 1,990 |
| 1001 | 모니터 | 1,990 |
- 1001, 모니터 가 중복되는 것을 확인할 수 있다.
- 이러한 경우에는 엔티티를 분해하는 것이 제2정규화이다.
예) 제2정규화 확인 (2)
| 주문번호 | 수출 여부 | 고객 번호 | 사업자 번호 | 우선순위 |
| AB345 | X | 4520 | 398201 | 1 |
| AD347 | Y | 2341 | - | 3 |
| CA210 | X | 3280 | 200212 | 8 |
| AB345 | X | 4520 | 398201 | 1 |
- 위의 경우도 AB345 주문번호에 중복이 발생한다.
- 이러한 경우에는 분해를 해야 한다.
예) 엔티티명 : 제품
| 제품번호 | 제품명 | 재고 수량 |
예) 엔티티명 : 제품
| 주문번호 | 수출 여부 | 고객 번호 | 사업자 번호 | 우선순위 |
예) 엔티티명 : 주문
| 제품번호 | 주문번호 | 재고 수량 |
- 결과적으로 최종 엔티티는 위와 같이 3개가 도출된다.
② 정규화와 성능
정규화의 문제점
- 정규화는 테이블을 분해해서 데이터 중복을 제거하기 때문에 데이터 모델의 유연성을 높인다.
- 정규화는 데이터 조회(SELECT) 시에 조인(Join)을 유발하기 때문에 CPU와 메모리를 많이 사용한다.
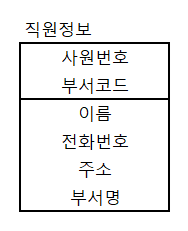
예) 정규화된 테이블
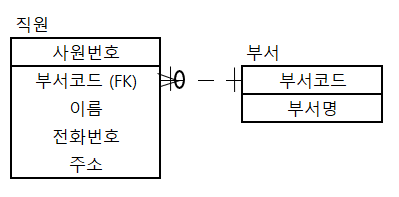
- 이와 같이 2개의 테이블로 이루어진 경우 "사원번호, 부서코드, 부서명, 이름, 전화번호, 주소"를 조회하려면 조인을 해야 한다.
SELECT 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소
FROM 직원, 부서
WHERE 직원.부서코드 = 부서.부서코드;// ANSI Join 으로 작성할 경우
SELECT 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소
FROM 직원 INNER JOIN 부서
ON 직원.부서코드 = 부서.부서코드;
- 위의 테이블은 <직원>과 <부서> 테이블에서 부서코드가 같은 것을 찾는 것이다.
- 이것을 프로그램화 한다면 중첩된 루프(Nested Loop)를 사용해야 한다.
for (i = 0; i < N; i = i + 1)
for (j = 0; j < M; j = j + 1)
if (직원_부서코드[i] == 부서_부서코드[j]) { }
// N : 직원 테이블의 건수
// M : 부서 테이블의 건수- 결과적으로 이중으로 for문을 사용해서 비교하는 기능을 만들어야 조인을 할 수 있다.
- 이러한 구조는 데이터양이 증가하면 비교해야 하는 건수도 증가한다.
- 물론, 실제로 위와 같은 비효율이 발생하지 않는다.
- 이러한 문제를 해결하기 위해서 인덱스와 옵티마이저(Optimizer)가 사용된다.
- 결론적으로 조인이 부하를 유발하는 것은 분명하다.
- 정규화의 문제점을 해결하기 위해서 반정규화를 하여 하나의 테이블에 저장한다면 조인을 통한 성능 저하는 해결될 것이다.
정규화를 사용한 성능 튜닝
- 조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결할 수 있다.
- 하지만, 반정규화는 데이터를 중복시키기 때문에 또 다른 문제점을 발생시킨다.
예) <계좌마스터> 테이블

- 위의 예처럼 <계좌마스터>의 칼럼이 계속적으로 증가하면 조인이 최소화되기 때문에 조회를 빠르게 할 수 있을 것이다.
- 하지만, 너무 많은 칼럼이 추가되면 1개 행의 크기가 데이터베이스 관리 시스템의 입출력 단위인 블록의 크기(Block Size)를 넘어서게 된다.
- 그렇게 되면 1개의 행을 읽기 위해 여러 개의 블록을 읽어야 한다.
- 디스크 입출력이 증가하기 때문에 성능이 떨어지게 된다.
- 반정규화의 문제점
- 디스크 입출력이 증가하기 때문에 성능이 떨어지게 된다.
- 그렇게 되면 1개의 행을 읽기 위해 여러 개의 블록을 읽어야 한다.
- 하지만, 너무 많은 칼럼이 추가되면 1개 행의 크기가 데이터베이스 관리 시스템의 입출력 단위인 블록의 크기(Block Size)를 넘어서게 된다.
- 위와 같은 문제가 발생하면 테이블을 분해하는 방법밖에 없다.
- 따라서 정규화는 입출력 데이터의 양을 줄여서 성능을 향상시킬 수 있는 것이다.
③ 반정규화(De-Normalization)
반정규화(De-Normalization)
- 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
- 반정규화는 조회(SELECT) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
반정규화를 수행하는 경우
- 정규화에 충실하면 종속성, 활용성은 향상되지만 수행 속도가 느려지는 경우
- 다량의 범위를 자주 처리해야 하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
반정규화 절차
| 반정규화 절차 | 설명 |
| 대상 조사 및 검토 | 데이터 처리 범위, 통계성 등을 확인해서 반정규화 대상을 조사한다. |
| 다른 방법 검토 | - 반정규화를 수행하기 전에 다른 방법이 있는지 검토한다. - 예) 클러스터링, 뷰, 인덱스 튜닝, 응용 프로그램, 파티션 등을 검토 |
| 반정규화 수행 | 테이블, 속성, 관계 등을 반정규화 한다. |
클러스터링(Clustering)
- 클러스터링 인덱스 : 인덱스 정보를 저장할 때 물리적으로 정렬해서 저장하는 방법
- 따라서 조회 시에 인접 블록을 연속적으로 읽기 때문에 성능이 향상된다.
반정규화 기법
(1) 계산된 칼럼 추가
- 배치 프로그램으로 총판매액, 평균잔고, 계좌평가 등을 미리 계산하고, 그 결과를 특정 칼럼에 추가한다.
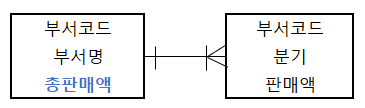
(2) 테이블 수직 분할
- 하나의 테이블을 2개 이상의 테이블로 분할한다.
- 칼럼을 분할하여 새로운 테이블을 만든다.

(3) 테이블 수평 분할
- 하나의 테이블에 있는 값을 기준으로 테이블을 분할하는 방법이다.
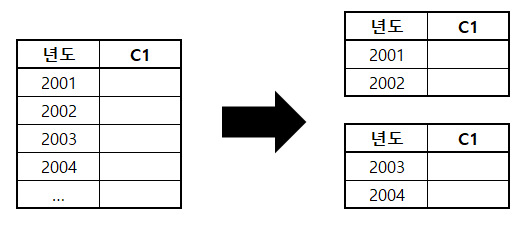
- 파티션(Partition) 기법
- 데이터베이스에서 파티션을 사용하여 테이블을 분할할 수 있다.
- 파티션을 사용하면 논리적으로는 하나의 테이블이지만, 여러 개의 데이터 파일에 분산되어서 저장된다.
- 종류
- Range Partition : 데이터 값의 범위를 기준으로 파티션을 수행한다.
- List Partition : 특정한 값을 지정하여 파티션을 수행한다.
- Hash Partition : 해시 함수를 적용하여 파티션을 수행한다.
- Composite Partition : 범위와 해시를 사용하여 파티션을 수행한다.
- 장점
- 데이터 조회 시에 액세스(Access) 범위가 줄어들기 때문에 성능이 향상된다.
- 데이터가 분할되어 있기 때문에 I/O(Input/Output)의 성능이 향상된다.
- 각 파티션을 독립적으로 백업 및 복구가 가능하다.
(4) 테이블 병합
- 1대1 관계의 테이블을 하나의 테이블로 병합해서 성능을 향상시킨다.
- 1대N 관계의 테이블을 병합하여 성능을 향상시킨다.
- 하지만, 많은 양의 데이터 중복이 발생한다.
- 슈퍼 타입(Super Type)과 서브 타입(Sub Type) 관계가 발생하면 테이블을 통합하여 성능을 향상시킨다.
- 예) <고객> 엔티티는 <개인고객>과 <법인고객>으로 분류된다.
- <고객> : 슈퍼 타입 (부모)
- <개인고객>, <법인고객> : 서브 타입 (자식)
- 관계 종류
- 베타적 관계
- <고객>이 <개인고객>이거나 <법인고객>인 경우
- 포괄적 관계
- <고객>이 <개인고객>이 될 수도 있고 <법인고객>일 수도 있는 경우
- 베타적 관계
- 예) <고객> 엔티티는 <개인고객>과 <법인고객>으로 분류된다.
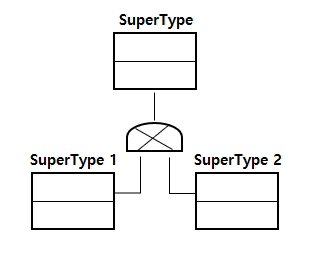
- 슈퍼 타입 및 서브 타입 변환 방법
| 변환 방법 | 설명 |
| OneToOne Type | - 슈퍼 타입과 서브 타입을 개별 테이블로 도출한다. - 테이블의 수가 많아서 조인이 많이 발생하고 관리가 어렵다. |
| Plus Type | - 슈퍼 타입과 서브 타입 테이블로 도출한다. - 조인이 발생하고 관리가 어렵다. |
| Single Type | - 슈퍼 타입과 서브 타입을 하나의 테이블로 도출한다. - 조인 성능이 좋고 관리가 편리하지만, 입출력 성능이 나쁘다. |
④ 분산 데이터베이스
분산 데이터베이스
- 중앙 집중형 데이터베이스 : 데이터베이스 시스템 구축 시, 1대의 물리적 시스템에 데이터베이스 관리 시스템을 설치하고 여러 명의 사용자가 데이터베이스 관리 시스템에 접속하여 데이터베이스를 사용하는 구조
- 분산 데이터베이스 : 물리적으로 떨어진 데이터베이스에 네트워크로 연결하여 단일 데이터베이스 이미지를 보여주고, 분산된 작업 처리를 수행하는 데이터베이스
- 분산 데이터베이스를 사용하는 고객은 시스템이 네트워크로 분산되어 있는지의 여부를 인식하지 못하면서, 자신만의 데이터베이스를 사용하는 것처럼 사용할 수 있다.
- 이처럼 데이터베이스는 투명성을 제공해야 한다.
- 분산 데이터베이스를 사용하는 고객은 시스템이 네트워크로 분산되어 있는지의 여부를 인식하지 못하면서, 자신만의 데이터베이스를 사용하는 것처럼 사용할 수 있다.
분산 데이터베이스의 투명성 종류
| 투명성 | 설명 |
| 분할 투명성 | 고객은 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 시스템에 저장되어 있음을 인식할 필요가 없다. |
| 위치 투명성 | - 고객이 사용하려는 데이터의 저장 장소를 명시할 필요가 없다. - 고객은 데이터가 어느 위치에 있더라도 동일한 명령을 사용하여 데이터에 접근할 수 있어야 한다. |
| 지역 사상 투명성 | 지역 DBMS에서 물적 데이터베이스 사이의 사상이 보장됨에 따라 각 지역 시스템 이름과 무관한 이름이 사용 가능하다. |
| 중복 투명성 | 데이터베이스 객체가 여러 시스템에 중복되어 존재함에도 고객과는 무관하게 데이터의 일관성이 유지된다. |
| 장애 투명성 | 데이터베이스가 분산되어 있는 각 지역의 시스템이나 통신망에 이상이 발생해도, 데이터의 무결성은 보장된다. |
| 병행 투명성 | 여러 고객의 응용 프로그램이 동시에 분산 데이터베이스에 대한 트랜잭션을 수행하는 경우에도 결과에 이상이 없다. |
분산 데이터베이스 설계 방식
(1) 상향식 설계 방식
- 지역 스키마 작성 후 향후 전역 스키마를 작성하여 분산 데이터베이스를 구축한다.
(2) 하향식 설계 방식
- 전역 스키마 작성 후 해당 지역 사상 스키마를 작성하여 분산 데이터베이스를 구축한다.
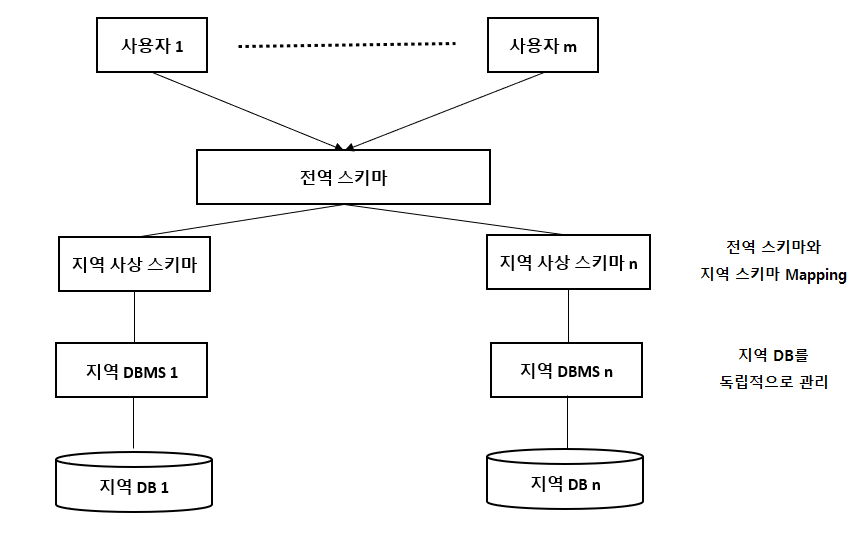
- 분산 데이터베이스를 구축할 경우
- 하향식 접근 방식
- 기업 전체의 전사 데이터 모델을 수렴하여 전역 스키마를 생성하고, 각 지역별로 지역 스키마를 생성하여 구축
- 상향식 접근 방식
- 지역별로 데이터베이스를 구축한 후에 전역 스키마로 통합하여 구축
- 하향식 접근 방식
- 분산 데이터베이스를 구축하거나 운영할 때, 동일한 데이터베이스 관리 시스템으로 분산 데이터베이스를 구축하는 것은 크게 어렵지 않다.
- 하지만, 기업에 여러 종류의 데이터베이스 관리 시스템이 있으면 이기종 데이터베이스 관리 시스템으로 연동해야 한다.
- 이기종 데이터베이스 시스템으로 연동하기 위해서는 데이터베이스 미들웨어(ODBC, JDBC)를 사용해야 한다.
- 하지만, 기업에 여러 종류의 데이터베이스 관리 시스템이 있으면 이기종 데이터베이스 관리 시스템으로 연동해야 한다.
- 분산 데이터베이스의 장점과 단점
| 장점 | 단점 |
| - 데이터베이스의 신뢰성과 가용성이 높다. - 분산 데이터베이스가 병렬 처리를 수행하기 때문에 빠른 응답이 가능하다. - 분산 데이터베이스를 추가하여 시스템 용량 확장이 쉽다. |
- 데이터베이스가 여러 네트워크를 통해서 분리되어 있기 때문에 관리와 통제가 어렵다. - 보안관리가 어렵다. - 데이터 무결성 관리가 어렵다. - 데이터베이스 설계가 복잡하다. |
728x90
'Certificate > SQLD' 카테고리의 다른 글
| [SQLD] 실전 문제 : 데이터 모델과 성능 (0) | 2022.06.23 |
|---|---|
| [SQLD] 실전 문제 : 데이터 모델링의 이해 (0) | 2022.06.21 |
| [SQLD] SQL 최적화의 원리 (0) | 2022.01.20 |
| [SQLD] SQL 활용 (0) | 2022.01.19 |
| [SQLD] SQL 기본 (0) | 2022.01.18 |
| [SQLD] 데이터 모델링(Data Modeling) (0) | 2022.01.14 |
| [SQLD] SQLD 소개 (0) | 2022.01.13 |
| 국가공인 SQL 개발자(SQLD) 자격증 시험 개요 (0) | 2022.01.13 |

