728x90
[SQLD] SQL 기본
① 관계형 데이터베이스(Relation Database)
관계형 데이터베이스(Relation Database)
(1) 관계형 데이터베이스의 등장
- 관계형 데이터베이스는 1970년대 E. F. Codd 박사의 논문에서 처음으로 소개된 데이터베이스이다.
- 관계형 데이터베이스는 릴레이션(Relation)과 릴레이션의 조인 연산을 통해서 합집합, 교집합, 차집합 등을 만들 수 있다.
- 현재 기업에서 가장 많이 사용하는 데이터베이스 관리 시스템
- Oracle, MS-SQL, MySQL, Sybase 등
(2) 데이터베이스와 데이터베이스 관리 시스템의 차이점
- 데이터베이스는 데이터를 어떠한 형태의 자료 구조(Data Structure)로 사용하느냐에 따라 나누어진다.
- 데이터베이스의 종류
- 계층형
- 트리(Tree) 형태의 자료구조에 데이터를 저장하고 관리
- 1대N 관계 표현
-

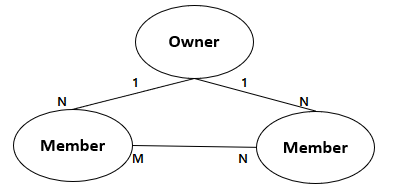
- 네트워크형
- 오너(Owner)와 멤버(Member) 형태로 데이터 저장
- 1대N과 함께 M대N 표현도 가능
- 관계형
- 릴레이션에 데이터를 저장하고 관리
- 릴레이션을 사용해서 집합 연산과 관계 연산을 할 수 있음.
- 계층형
- 데이터베이스 관리 시스템(DBMS; DataBase Management System)
- 계층형/네트워크/관계형 데이터베이스 등을 관리하기 위한 소프트웨어
- 종류
- Oracle, MS-SQL, MySQL, Sybase 등
- 모두 관계형 데이터베이스를 지원
- Oracle, MS-SQL, MySQL, Sybase 등
(3) 관계형 데이터베이스 집합 연산과 관계 연산
- 관계형 데이터베이스의 특징
- 릴레이션을 사용해서 집합 연산과 관계 연산을 할 수 있다.
| 집합 연산 | 설명 |
| 합집합(Union) | - 2개의 릴레이션을 하나로 합하는 것 - 중복된 행(튜플)은 한 번만 조회됨. |
| 차집합(Difference) | 본래 릴레이션에는 존재하고 다른 릴레이션에는 존재하지 않는 것을 조회함. |
| 교집합(Intersection) | 2개의 릴레이션 간에 공통된 것을 조회함. |
| 곱집합(Cartesian Product) | 각 릴레이션에 존재하는 모든 데이터를 조합하여 연산함. |
| 관계 연산 | 설명 |
| 선택 연산(Selection) | 릴레이션에서 조건에 맞는 행(튜플)만 조회 |
| 투영 연산(Projection) | 릴레이션에서 조건에 맞는 속성만 조회 |
| 결합 연산(Join) | 여러 릴레이션의 공통된 속성을 사용해서 새로운 릴레이션을 만들어냄. |
| 나누기 연산(Division) | 기준 릴레이션에서 나누는 릴레이션이 가지고 있는 속성과 동일한 값을 가지는 행(튜플)을 추출하고, 나누는 릴레이션의 속성을 삭제한 후 중복된 행을 제거하는 연산 |
테이블의 구조
- 관계형 데이터베이스는 릴레이션에 데이터를 저장하고, 릴레이션을 사용해서 집합 연산 및 관계 연산을 지원하여 다양한 형태로 데이터를 조회할 수 있다.
- 릴레이션은 최종으로 데이터베이스 관리 시스템에서 테이블(Table)로 만들어진다.
예) 테이블의 구조

- 기본키(Primary Key) : 하나의 테이블에서 유일성(Unique)과 최소성, Not Null을 만족하면서 해당 테이블을 대표하는 것
- <EMP> 테이블에서 사원번호
- 테이블은 행(Row)과 칼럼(Column)으로 구분된다.
- 행(Row) : 하나의 테이블에 저장되는 값으로, 튜플(Tuple)이라고 한다.
- 칼럼(Column) : 어떤 데이터를 저장하기 위한 필드(Field)로, 속성(Attribute)이라고도 한다.
- 외래키(Foreign Key) : 다른 테이블의 기본키를 참조(조인)하는 칼럼
- <EMP> 테이블의 부서코드는 <DEPT> 테이블의 기본키인 부서코드를 참조한다.
- 외래키는 관계 연산 중에서 결합 연산(조인 : Join)을 하기 위해서 사용한다.
② SQL(Structured Query Language) 종류
SQL(Structued Query Language)
- 관계형 데이터베이스에 대해서 데이터 구조를 정의, 데이터 조작, 데이터 제어 등을 할 수 있는 절차형 언어
- 관계형 데이터베이스는 데이터베이스를 연결하고 SQL문을 사용하여 데이터베이스를 누구나 쉽게 사용할 수 있도록 한다.
- SQL은 ANSI/ISO 표준을 준수하기 때문에 데이터베이스 관리 시스템이 변경되어도 그대로 사용할 수 있다.
- SQL 표준
- ANSI/ISO SQL 표준
- INNER JOIN, NATURAL JOIN, USING 조건, ON 조건절 사용
- ANSI/ISO SQL 3 표준
- DBMS 벤더별로 차이가 있었던 SQL을 표준화하여 제정
- ANSI/ISO SQL 표준
- SQL 표준
SQL 종류
| 종류 | 설명 |
| DDL (Data Defintion Language) |
- 관계형 데이터베이스의 구조를 정의하는 명령어 - CREATE, ALTER, DROP, RENAME 등 |
| DML (Data Manipulation Language) |
- 테이블에서 데이터를 입력, 수정, 삭제, 조회하는 명령어 - INSERT, UPDATE, DELETE, SELECT 등 |
| DCL (Data Control Language) |
- 데이터베이스 사용자에게 권한을 부여하거나 회수하는 명령어 - GRANT, REVOKE, TRUNCATE 등 |
| TCL (Transaction Control Language) |
- 트랜잭션을 제어하는 명령어 - COMMIT, ROLLBACK, SAVEPOINT 등 |
- DDL문
- 데이터베이스 테이블을 생성하거나 변경, 삭제하는 것
- 데이터를 저장할 구조를 정의하는 언어
- DML문
- 데이터 구조가 DDL로 정의되면 해당 데이터 구조에 데이터를 입력하거나 수정, 삭제, 조회할 수 있다.
- DCL문
- DDL로 정의된 구조에 어떤 사용자가 접근할 수 있는지 권한을 부여하는 것이다.

- 작업의 순서
- 데이터베이스의 사용자에게 권한을 부여한다.
- 권한이 부여되면 사용자는 DDL로 데이터 구조를 정의한다.
- 데이터 구조가 정의되면 사용자는 데이터를 입력한다.
- 개발자 및 사용자가 입력한 데이터를 조회한다.
- 트랜잭션의 특성
- 트랜잭션(Transaction) : 데이터베이스 작업을 처리하는 단위
| 트랜잭션 특성 | 설명 |
| 원자성(Atomicity) | - 트랜잭션은 데이터베이스 연산의 전부가 실행되거나 전혀 실행되지 않아야 한다. (ALL OR NOTHING.) - 즉, 트랜잭션의 처리가 완전히 끝나지 않았을 경우는 실행되지 않은 상태와 같아야 한다. |
| 일관성(Consistency) | - 트랜잭션 실행 결과로 데이터베이스의 상태가 모순되지 않아야 한다. - 트랜잭션 실행 후에도 일관성이 유지되어야 한다. |
| 고립성(Isolation) | - 트랜잭션 실행 중에 생성하는 연산의 중간 결과는 다른 트랜잭션이 접근할 수 없다. - 즉, 부분적인 실행 결과를 다른 트랜잭션이 볼 수 없다. |
| 영속성(Durability) | 트랜잭션이 그 실행을 성공적으로 완료하면 그 결과는 영구적 보장이 되어야 한다. |
SQL문의 실행 순서
- 개발자가 작성한 SQL문(DDL, DML, DCL 등)은 3단계를 걸쳐서 실행된다.
- SQL문의 문법을 검사하고 구문 분석을 한다.
- 구문 분석 이후에 SQL을 실행한다.
- SQL이 실행되면 데이터를 인출하게 된다.
| SQL 실행 순서 | 설명 |
| 파싱(Parsing) | - SQL문의 문법을 확인하고 구문 분석한다. - 구문 분석한 SQL문은 Library Cache에 저장한다. |
| 실행(Execution) | 옵티마이저(Optimizer)가 수립한 실행 계획에 따라 SQL을 실행한다. |
| 인출(Fetch) | 데이터를 읽어서 전송한다. |
③ DDL(Data Definition Language)
테이블 생성
- 데이터베이스를 사용하기 위해서는 테이블을 먼저 생성해야 한다.
- 관련 명령문
| SQL문 | 설명 |
| CREATE TABLE | - 새로운 테이블 생성 - 테이블을 생성할 때 기본키, 외래키, 제약사항 등을 설정할 수 있음. |
| ALTER TABLE | - 생성된 테이블 변경 - 칼럼을 추가하거나 변경, 삭제할 수 있음. - 기본키를 설정하거나, 외래키를 설정할 수 있음. |
| DROP TABLE | - 해당 테이블 삭제 - 테이블의 데이터 구조뿐만 아니라 저장된 데이터도 모두 삭제됨. |
(1) 기본적인 테이블 생성
예) 간단한 <EMP> 테이블 생성
CREATE TABLE EMP (
empno NUMBER(10) PRIMARY KEY, /* PRIMARY KEY : 기본키 */
ename VARCHAR2(20), /* VARCHAR2 : 가변 길이 문자 */
sal NUMBER(6) /* NUMBER : 숫자 */
);
- CREATE TABLE 문의 구조
| CREATE TABLE 문 | 설명 |
| CREATE TABLE | - 'CREATE TABLE EMP'는 'EMP' 테이블을 생성하라는 의미 - '( )' 사이에 칼럼을 쓰고 마지막은 세미콜론(;)으로 끝남. |
| 칼럼 정보 | - 테이블에 생성되는 칼럼 이름과 데이터 타입을 입력 - 칼럼 이름은 영문, 한글, 숫자 모두 가능 |
| 데이터 타입 | - NUMBER는 칼럼의 데이터 타입을 숫자형 타입으로, VARCHAR2는 가변 길이 문자열로 지정할 때 사용 - CHAR는 칼럼의 데이터 타입을 고정된 크기의 문자로 지정할 때, DATE는 날짜형 타입으로 지정할 때 사용 |
| 기본키 | 기본키를 지정할 떄 칼럼 옆에 PRIMARY KEY를 입력 |
- 테이블 구조 확인
- DESC : 테이블 구조를 확인할 때 사용
- CREATE TABLE로 생성된 테이블의 구조를 보고 싶을 때 사용
- DESC : 테이블 구조를 확인할 때 사용
(2) 제약 조건 사용
- 기본키, 외래키, 기본값, Not Null 등은 테이블을 생성할 때 지정할 수 있다.
사용 예
CREATE TABLE EMP (
empno NUMBER(10),
ename VARCHAR2(20),
sal NUMBER(10, 2) DEFAULT 0, /* 기본값 지정, 소수 둘째 자리까지 저장 */
deptno VARCHAR2(4) NOT NULL,
createdate DATE DEFAULT SYSDATE, /* 기본값 : SYSDATE(오늘 날짜 시분초) */
CONSTRAINT emppk PRIMARY KEY(empno) /* 기본키 이름 : emppk, 제약조건(Constraint)을 사용해서 기본키 지정 */
);- 만약 위의 예에서 2개의 기본키를 지정하고자 하면 다음과 같이 지정하면 된다.
CREATE TABLE EMP(
/* ... */
CONSTRAINT emppk PRIMARY KEY(empno, ename)
);- Oracle 데이터베이스에서 'SYSDATE'는 오늘의 날짜를 조회한다.
- 외래키(Foreign Key)를 지정하려면, 먼저 마스터 테이블이 생성되어야 한다.
- 예) <사원>과 <부서>테이블
- <부서> 테이블 : 마스터 테이블
- <사원> 테이블이 <부서> 테이블의 deptno를 참조해야 한다.
- <부서> 테이블 : 마스터 테이블
- 예) <사원>과 <부서>테이블
- <EMP> 테이블을 생성할 때 CONSTRAINT를 사용하여 외래키 이름인 'deptfk'를 입력 후 외래키를 생성한다.
/* 마스터 테이블 생성 */
CREATE TABLE DEPT(
deptno VARCHAR2(4) PRIMARY KEY,
deptname VARCHAR2(20)
);
CREATE TABLE EMP (
empno NUMBER(10),
ename VARCHAR2(20),
sal NUMBER(10, 2) DEFAULT 0,
deptno VARCHAR2(4) NOT NULL,
createdate DATE DEFAULT SYSDATE,
CONSTRAINT emppk PRIMARY KEY(empno),
CONSTRAINT deptfk FOREIGN KEY(deptno) /* 외래키 이름 : deptfk, 외래키가 기본키를 참조 */
REFERENCES DEPT(deptno) /* DEPT 테이블의 deptno 칼럼에 대해서 외래키를 생성 */
);
(3) 테이블 생성 시 CASCADE 사용
- 테이블을 생성할 때 CASCADE 옵션을 사용할 수 있다.
- CASCADE 옵션 : 참조 관계(기본키와 외래키 관계)가 있을 경우, 참조되는 데이터를 자동으로 반영할 수 있게하는 옵션
사용 예
/* 마스터 테이블 생성 */
CREATE TABLE DEPT(
deptno VARCHAR2(4) PRIMARY KEY,
deptname VARCHAR2(20)
);
/* DEPT 테이블을 생성하고 2개의 데이터를 입력 */
INSERT INTO DEPT VALUES('1000', '인사팀');
INSERT INTO DEPT VALUES('1001', '총무팀');
CREATE TABLE EMP (
empno NUMBER(10),
ename VARCHAR2(20),
sal NUMBER(10, 2) DEFAULT 0,
deptno VARCHAR2(4) NOT NULL,
createdate DATE DEFAULT SYSDATE,
CONSTRAINT emppk PRIMARY KEY(empno),
CONSTRAINT deptfk FOREIGN KEY(deptno)
REFERENCES DEPT(deptno)
ON DELETE CASCADE /* CASCADE 옵션 사용 */
);
/* 2개의 데이터 입력 */
INSERT INTO EMP VALUES(100, "세종대왕", 1000, '1000', SYSDATE);
INSERT INTO EMP VALUES(101, "을지문덕", 2000, '1001', SYSDATE);
- 그리고 다음과 같이 <DEPT> 테이블에서 deptno가 '1000'번인 '인사팀'을 삭제하면, <EMP> 테이블에서 deptno가 '1000'번이었던 '세종대왕' 데이터가 자동으로 삭제된다.
DELETE FROM DEPT WHERE DEPTNO = '1000'; /* DEPT 테이블에서 '1000'번인 인사팀 삭제 */
SELECT * FROM EMP; /* EMP 테이블 조회 */
- ON DELETE CASCADE 옵션
- 자신이 참조하고 있는 테이블(<DEPT>)의 데이터가 삭제되면 자동으로 자신(<EMP>)도 삭제되는 옵션
- 이 옵션을 사용할 경우 참조 무결성을 준수할 수 있다.
- 마스터 테이블(<DEPT>)에는 해당 부서번호(deptno)가 없는데, 슬레이브 테이블(<EMP>)에는 해당 부서번호가 있는 경우를 참조 무결성 위배로 볼 수 있다.
테이블 변경
- ALTER TABLE 문을 통해 테이블을 변경할 수 있다.
- 테이블명 변경, 칼럼 추가, 변경, 삭제 등을 할 수 있다.
(1) 테이블명 변경
- 테이블명 변경은 ALTER TABLE ~ RENAME TO 문을 사용하면 된다.
ALTER TABLE EMP
RENAME TO NEW_EMP; /* EMP 테이블을 NEW_EMP 테이블로 변경한다. */
(2) 칼럼 추가
- 생성된 <EMP> 테이블에 ALTER TABLE ~ ADD 문을 사용해서 칼럼을 추가한다.
ALTER TABLE EMP
ADD (age NUMBER(2) DEFAULT 1); /* EMP 테이블에 age 칼럼 추가 */
(3) 칼럼 변경
- 칼럼의 변경은 ALTER TABLE ~ MODIFY 문을 사용하면 된다.
- 칼럼 변경을 통해 데이터 타입을 변경하거나 데이터의 길이를 변경할 수 있다.
- 칼럼을 변경할 때 제약조건을 설정할 수도 있다.
- 칼럼의 데이터 타입을 변경할 때, 기존 데이터가 있는 경우 에러가 발생한다.
- 예) 숫자 타입이고 숫자 데이터가 저장되어 있는데 문자형 데이터 타입으로 변경할 경우
ALTER TABLE EMP
MODIFY (ename VARCHAR2(40) NOT NULL);
/* EMP 테이블에 ename 칼럼의 길이를 20에서 40으로 변경하고 NOT NULL 조건을 설정 */
(4) 칼럼 삭제
- 칼럼 삭제는 ALTER TABLE ~ DROP COLUMN 문을 사용하면 된다.
ALTER TABLE EMP
DROP COLUMN age; /* EMP 테이블의 age 칼럼을 삭제 */
(5) 칼럼명 변경
- 칼럼명 변경은 ALTER TABLE ~ RENAME COLUMN ~ TO 문을 사용하면 된다.
ALTER TABLE EMP
RENAME COLUMN ename TO new_ename; /* EMP 테이블의 ename 칼럼명을 new_ename으로 변경 */
테이블 삭제
- 테이블 삭제는 DROP TABLE 문을 사용해서 할 수 있다.
- DROP TABLE은 테이블의 구조와 데이터를 모두 삭제한다.
DROP TABLE EMP; /* EMP 테이블의 데이터와 테이블의 구조를 모두 삭제 */
- DROP TABLE에서 CASCADE CONSTRAINT 옵션을 사용할 수 있다.
- CASCADE CONSTRAINT 옵션 : 해당 테이블의 데이터를 외래키로 참조한 슬레이브 테이블과 관련된 제약사항도 삭제할 때 사용하는 옵션
DROP TABLE EMP CASCADE CONSTRAINT; /* 참조된 제약사항까지도 모두 삭제 */
뷰(View) 생성과 삭제
- 뷰(View) : 테이블로부터 유도된 가상의 테이블
- 실제 데이터를 가지고 있지 않고, 테이블을 참조해서 원하는 칼럼만을 조회할 수 있게 한다.
- 뷰는 데이터 딕셔너리(Data Dictionary)에 SQL문 형태로 저장하되, 실행 시에 참조된다.
뷰의 특징
- 참조한 테이블이 변경되면 뷰도 변경된다.
- 뷰의 검색은 참조한 테이블과 동일하게 할 수 있지만, 뷰에 대한 입력, 수정, 삭제에는 제약이 있다.
- 특정 칼럼만 조회시켜서 보안성을 향상시킨다.
- 한번 생성한 뷰는 변경할 수 없고, 변경을 원하면 삭제 후 재생성해야 한다.
- ALTER 문을 사용해서 뷰를 변경할 수 없다.
뷰의 장점과 단점
| 장점 | 단점 |
| - 특정 칼럼만 조회할 수 있기 때문에 보안 기능이 있다. - 데이터 관리가 간단하다. - SELECT 문이 간단해진다. - 하나의 테이블에 여러 개의 뷰를 생성할 수 있다. |
- 뷰는 독자적인 인덱스를 만들 수 없다. - 삽입, 수정, 삭제 연산이 제약된다. - 데이터 구조를 변경할 수는 없다. |
사용 예
- 뷰를 생성할 떄 CREATE VIEW 문을 사용하며, 참조할 테이블은 SELECT 문으로 지정한다.
CREATE VIEW T_EMP AS
SELECT * FROM EMP; /* EMP 테이블을 조회해서 그 결과로 T_EMP라는 뷰(View)를 생성 */- 뷰의 조회는 SELECT 문을 사용해서 일반 테이블처럼 조회한다.
SELECT * FROM T_EMP; /* 뷰를 조회 */
- 뷰의 삭제는 DROP VIEW 문을 사용한다.
- 뷰를 삭제했다고 해서 참조했던 테이블이 삭제되지는 않는다.
DROP VIEW T_EMP; /* 뷰를 삭제 */
④ DML(Data Manipulation Language)
INSERT 문
(1) INSERT 문
- 테이블에 데이터를 입력하는 DML 문
INSERT INTO table(column1, column2, ...) VALUES(expression1, expression2, ...);- <EMP> 테이블에 데이터를 삽입하려면 테이블명, 칼럼명, 데이터 순으로 입력하면 된다.
INSERT INTO EMP(empno, ename) VALUES(1000, '세종대왕'); /* 문자열을 사용하는 경우 ' '를 사용해야 함. */- 데이터를 입력할 때, 문자열을 입력하는 경우에는 작은따옴표(' ')를 사용해야 한다.
- 만약 특정 테이블의 모든 칼럼에 대한 데이터를 삽입하는 경우에는 칼럼명을 생략할 수 있다.
INSERT INTO EMP VALUES(1000, '세종대왕'); /* 모든 칼럼에 데이터 입력 (칼럼명 생략) */
/* 단, EMP 테이블의 칼럼은 숫자형 데이터 타입 1개와 문자형 타입 1개의 컬럼만 있어야 함. */- 주의 사항
- INSERT 문을 실행했다고 데이터 파일에 저장되는 것은 아니다.
- 최종적으로 데이터를 저장하려면 TCL문인 COMMIT을 실행해야 한다.
- 만약 Auto Commit(SET AUTO COMMIT ON)으로 설정된 경우에는 COMMIT 을 실행하지 않아도 된다.
(2) SELECT문으로 입력
- SELECT 문을 사용하여 데이터를 조회해서 해당 테이블에 바로 삽입할 수 있다.
- 단, 입력되는 테이블은 사전에 생성되어 있어야 한다.
INSERT INTO DEPT_TEST
SELECT * FROM DEPT; /* DEPT 테이블의 모든 데이터를 조회해서 DEPT_TEST 테이블에 입력 */
(3) NOLOGGING 사용
- 데이터베이스에 데이터를 입력하면 로그 파일(Log File)에 그 정보를 기록한다.
- Check Point 라는 이벤트가 발생하면, 로그 파일의 데이터를 데이터 파일에 저장한다.
- NOLOGGING 옵션
- 로그 파일의 기록을 최소화시켜서 입력 시 성능을 향상시키는 방법
- 버퍼 캐시(Buffer Cache)라는 메모리 영역을 생략하고 기록한다.
ALTER TABLE DEPT NOLOGGING; /* 로그 파일의 기록을 최소화하여 입력 성능을 향상시킴. */
UPDATE 문
- 입력된 데이터의 값을 수정하려면, UPDATE 문을 사용한다.
- UPDATE 문을 사용하여 원하는 조건으로 데이터를 검색해서 해당 데이터를 수정할 수 있다.
- 만약, UPDATE 문에 조건문을 입력하지 않으면 모든 데이터가 수정되므로 유의해야 한다.
UPDATE EMP
SET ename='조조' /* ename 칼럼의 값을 '조조'로 변경 */
WHERE empno=100; /* EMP 테이블에서 empno가 100번인 직원 수정 */
- 주의 사항
- 데이터를 수정할 때 조건절에서 검색되는 행 수만큼 수정된다.
- 위의 예에서 empno가 100번인 직원이 2명이라면, 2명의 ename은 모두 '조조'로 수정된다.
- 데이터를 수정할 때 조건절에서 검색되는 행 수만큼 수정된다.
DELETE 문
- 원하는 조건을 검색해서 해당되는 행을 삭제한다.
- DELETE 문에 조건문을 입력하지 않으면 모든 데이터가 삭제된다.
- 테이블에 있는 모든 데이터가 삭제된다.
- DELETE 문으로 데이터를 삭제한다고 해서 테이블의 용량이 초기화되지는 않는다.
- Oracle 데이터베이스는 저장 공간을 할당할 때 Extent 단위로 할당한다.
- 테이블에 데이터가 입력되면 Extent에 저장된다.
- 만약, Extent의 크기가 MAX_EXTENTS 를 넘어서게 되면 용량 초과 오류가 발생하게 된다.
- 즉, Extent는 최대로 저장할 수 있는 공간의 의미를 가지고 있다.
- DELETE 문으로 데이터를 삭제하면 용량이 감소할 것으로 생각되는데, DELETE 문은 삭제 여부만 표시하고 용량은 초기화되지 않는다.
- Oracle 데이터베이스는 저장 공간을 할당할 때 Extent 단위로 할당한다.
DELETE FROM EMP
WHERE empno=100; /* EMP 테이블에서 empno가 100번인 직원을 삭제 */- 만약 위의 예에서 WHERE 절(조건)을 입력하지 않으면 <EMP> 테이블의 모든 데이터가 삭제된다.
테이블의 모든 데이터 삭제
| DELETE FROM 테이블명; | TRUNCATE TABLE 테이블명; |
| - 테이블의 모든 데이터를 삭제한다. - 데이터가 삭제되어도 테이블의 용량은 감소하지 않는다. |
- 테이블의 모든 데이터를 삭제한다. - 데이터가 삭제되면 테이블의 용량은 초기화된다. |
SELECT 문
(1) SELECT 문 사용
- 테이블에 입력된 데이터를 조회하기 위해서 SELECT 문을 사용한다.
- SELECT 문은 특정 칼럼이나 특정 행만을 조회할 수 있다.
SELECT * /* 조회를 원하는 칼럼(Column) 선택 : 모든 칼럼(*) */
FROM EMP /* 조회를 원하는 테이블명 지정 */
WHERE 사원번호=1000; /* 조회를 원하는 데이터의 조건 지정 */- 단, WHERE 절에 있는 조건문에 있는 행만 조회한다.
| SELECT 문 문법 | 설명 |
| SELECT * | - 모든 칼럼 출력 - * : 모든 칼럼 |
| FROM EMP | - FROM 절에는 테이블명을 쓴다. - 즉, <EMP> 테이블을 지정했다. |
| WHERE 사원번호=1000 | - <EMP> 테이블에서 사원번호가 1000번인 행을 조회한다. - 즉, 조건문을 지정한다. |
- SELECT 칼럼 지정
| 사용 예제 | 설명 |
| SELECT empno, ename FROM EMP; | <EMP> 테이블의 모든 행에서 empno와 ename 칼럼만을 출력한다. |
| SELECT * FROM EMP; | <EMP> 테이블의 모든 칼럼과 모든 행을 조회한다. |
| SELECT ename || '님' FROM EMP; | - <EMP> 테이블의 모든 행에서 ename 칼럼을 조회한다. - 단, ename 컬럼 뒤에 '님'이라는 문자를 결합한다. - 예) 세종대왕 님 |
(2) ORDER BY를 사용한 정렬
- SELECT 문을 사용할 때 ORDER BY 를 같이 사용할 수 있다.
- ORDER BY
- 데이터를 오름차순(Ascending) 또는 내림차순(Descending)으로 출력
- 정렬 시점
- 모든 실행이 끝난 후, 데이터 출력 바로 전
- 정렬을 하기 때문에 데이터베이스 메모리를 많이 사용하게 된다.
- 대량의 데이터를 정렬하게 되면 정렬로 인한 성능 저하가 발생한다.
- ORDER BY
- Oracle 데이터베이스는 정렬을 위해서 메모리 내부에 할당된 SORT_AREA_SIZE를 사용한다.
- 만약, SORT_AREA_SIZE가 너무 작으면 성능 저하가 발생한다.
- 정렬을 회피하기 위해서 인덱스(INDEX)를 생성할 때 사용자가 원하는 형태로 오름차순 혹은 내림차순으로 생성해야 한다.
- 특별한 지정이 없으면 ORDER BY는 오름차순으로 정렬한다.
SELECT * FROM EMP
ORDER BY ename, sal DESC; /* ename으로 오름차순 정렬하고, sal로 내림차순 정렬 */- 오름차순으로 정렬하고 싶을 때는 ASC(또는 생략), 내림차순으로 정렬하고 싶을 때는 DESC 를 사용한다.
(3) INDEX를 사용한 정렬 회피
- 정렬은 Oracle 데이터베이스에 부하를 주므로, 인덱스(INDEX)를 사용해서 ORDER BY 를 회피할 수 있다.
사용 예
CREATE TABLE EMP(
empno NUMBER(10) PRIMARY KEY,
ename VARCHAR2(20),
sal NUMBER(10)
);
INSERT INTO EMP VALUES(1000, '세종대왕', 20000);
INSERT INTO EMP VALUES(1001, '을지문덕', 20000);
INSERT INTO EMP VALUES(1002, '김유신', 20000);- 위와 같이 데이터를 입력하고 SELECT 문을 실행하면 empno로 오름차순 정렬되어서 조회된다.
- empno가 기본키이기 때문에 자동으로 오름차순 인덱스가 생성되기 때문이다.
- 다음과 같이 힌트를 사용하여, <EMP> 테이블에 생성된 인덱스를 내림차순으로 읽게 지정할 수 있다.
- SELECT 문에 ORDER BY empno DESC 를 사용하지 않아도 된다.
SELECT /*+ INDEX_DESC(A) */ /* empno로 생성된 인덱스를 내림차순으로 읽게 지정함. */
FROM EMP A;

- 위의 예처럼 SQL문을 사용하면 empno 인덱스를 내림차순으로 읽는다.
- 인덱스를 스캔한 후에 해당 empno의 값을 가지고 테이블의 데이터를 읽는다.
- 테이블에서 해당 행을 찾으면 인출하여 사용자 화면에 조회된다.
(4) DISTINCT와 ALIAS
- DISTINCT 문
- 칼럼명 앞에 지정하여 중복된 데이터를 한 번에 조회하게 한다.
SELECT DISTINCT deptno /* 중복된 데이터를 제거하여 조회 */
FROM EMP
ORDER BY DEPTNO;
- ALIAS 문
- ALIAS(별칭)은 테이블명이나 칼럼명이 너무 길어서 간략하게 할 때 사용한다.
SELECT ename AS "이름" /* 칼럼명을 '이름'으로 출력되게 함. */
FROM EMP a /* EMP 테이블명 대신에 'a' 사용 */
WHERE a.empno=1000; /* 'a'를 테이블명 처럼 사용 */
⑤ WHERE 문 사용
WHERE 문이 사용하는 연산자
비교 연산자
| 연산자 | 설명 |
| = | 같은 것을 조회한다. |
| < | 작은 것을 조회한다. |
| <= | 작거나 같은 것을 조회한다. |
| > | 큰 것을 조회한다. |
| >= | 크거나 같은 것을 조회한다. |
부정 비교 연산자
| 연산자 | 설명 |
| != | 같지 않은 것을 조회한다. |
| ^= | 같지 않은 것을 조회한다. |
| <> | 같지 않은 것을 조회한다. |
| NOT 칼럼명 = | 같지 않은 것을 조회한다. |
| NOT 칼럼명 > | 크지 않은 것을 조회한다. |
논리 연산자
| 연산자 | 설명 |
| AND | 조건을 모두 만족해야 참(True)이 된다. |
| OR | 조건 중 하나만 만족해도 참(True)이 된다. |
| NOT | 참이면 거짓(False)으로 바꾸고, 거짓이면 참(True)으로 바꾼다. |
SQL 연산자
| 연산자 | 설명 |
| LIKE '%비교 문자열%' | 비교 문자열을 조회한다. '%' : 모든 값 |
| BETWEEN A AND B | A와 B 사이의 값을 조회한다. ( A <= X <= B ) |
| IN (list) | OR를 의미하며, list 값 중에 하나만 일치해도 조회된다. |
| IS NULL | NULL 값을 조회한다. |
부정 SQL 연산자
| 연산자 | 설명 |
| NOT BETWEEN A AND B | A와 B 사이에 해당되지 않는 값을 조회한다. |
| NOT IN (list) | list와 불일치한 것을 조회한다. |
| IS NOT NULL | NULL 값이 아닌 것을 조회한다. |
사용 예
SELECT * FROM EMP
WHERE empno=1001 AND sal>=1000;
LIKE 문 사용
- LIKE 문과 와일드카드를 사용해서 데이터를 조회할 수 있다.
| 와일드카드 | 설명 |
| % | - 어떤 문자를 포함한 모든 것을 조회한다. - 예) '조%' : '조'로 시작하는 모든 문자 조회 |
| _ (Underscore) | - 1개인 단일 문자를 의미한다. |
사용 예
/* 사용 예 1 */
SELECT * FROM EMP
WHERE ename LIKE 'test%'; /* ename이 'test'로 시작하는 모든 데이터를 조회 */
/* 사용 예 2 */
SELECT * FROM EMP
WHERE ename LIKE '%1'; /* ename의 마지막이 '1'로 끝나는 모든 데이터 조회 */
/* 사용 예 3 */
SELECT * FROM EMP
WHERE ename LIKE '%est%'; /* ename의 중간에 'est'가 있는 모든 데이터 조회 */
/* 사용 예 4 */
SELECT * FROM EMP
WHERE ename LIKE 'test1'; /* LIKE 문에 와일드카드를 사용하지 않으면 '='와 같음. */
/* 사용 예 5 */
SELECT * FROM EMP
WHERE ename LIKE 'test_'; /* ename 칼럼에서 'test'로 시작하고 하나의 글자만 더 있는 데이터 조회 */
BETWEEN 문 사용
- BETWEEN 문은 지정된 범위에 있는 값을 조회한다.
- 예) BETWEEN 100 AND 200
- 1000과 2000을 포함하고, 1000과 2000 사이의 값 조회
사용 예
/* 사용 예 1 */
SELECT * FROM EMP
WHERE sal BETWEEN 1000 AND 2000; /* sal이 1000 이상 2000 이하인 데이터 조회 */
/* 사용 예 2 */
SELECT * FROM EMP
WHERE sal NOT BETWEEN 1000 AND 2000; /* sal이 1000 미만 2000 초과인 데이터 조회 */
IN 문 사용
- IN 문은 "OR"의 의미를 가지고 있어서 하나의 조건만 만족해도 조회가 된다.
- 예) JOB IN ('CLERK', 'MANAGER')
- JOB이 "CLERK" 이거나 "MANAGER" 인 값 조회
사용 예
/* 사용 예 1 */
SELECT * FROM EMP
WHERE job IN ('CLERK', 'MANAGER'); /* job 칼럼이 'CLERK' 이거나 'MANAGER'인 레코드 조회 */
/* 사용 예 2 */
SELECT * FROM EMP
WHERE (job, ename)
IN (('CLERK', 'test1'), ('MANAGER', 'test4')); /* IN 조건에 2개의 칼럼 지정 */- 괄호( () )를 사용하여 원하는 데이터를 칼럼명에 대응되도록 입력함으로써, IN 문으로 여러 개의 칼럼에 대한 조건을 지정할 수 있다.
NULL 값 조회
(1) NULL의 특징
- NULL은 모르는 값을 의미한다.
- NULL은 값의 부재를 의미한다.
- NULL과 숫자 혹은 날짜 를 더하면 NULL이 된다.
- NULL과 어떤 값을 비교할 때, '알 수 없음'이 반환된다.
(2) NULL 값 조회
- NULL을 조회할 경우는 IS NULL 을 사용하고, NULL 값이 아닌 것을 조회할 경우에는 IS NOT NULL 을 사용한다.
사용 예
/* 사용 예 1 */
SELECT * FROM EMP
WHERE mgr IS NULL; /* mgr 칼럼이 NULL인 데이터 조회 */
/* 사용 예 2 */
SELECT * FROM EMP
WHERE mgr IS NOT NULL; /* mgr 칼럼이 NULL이 아닌 데이터 조회 */
(3) NULL 관련 함수
| 함수 | 설명 |
| NVL | - NULL이 되면 다른 값으로 바꾸는 함수 - 예) NVL(mgr, 0) : mgr 칼럼이 NULL 이면 0으로 바꿈. |
| NVL2 | - NVL 함수와 DECODE 함수를 하나로 만든 것 - 예) NVL2(msg, 1, 0) : mgr 칼럼이 NULL이 아니면 1을, NULL이면 0을 반환 |
| NULLIF | - 2개의 값이 같으면 NULL을, 같지 않으면 첫 번째 값을 반환하는 함수 - 예) NULLIF(exp1, exp2) : exp1과 exp2가 같으면 NULL을, 같지 않으면 exp1을 반환 |
| COALESCE | - NULL이 아닌 최초의 인자 값을 반환하는 함수 - 예) COALESCE(exp1, exp2, exp3, ...) : exp1이 NULL이 아니면 exp1의 값을, 그렇지 않으면 그 뒤의 값의 NULL 여부를 판단하여 값을 반환 |
⑥ GROUP 연산
GROUP BY 문
- GROUP BY 문
- 테이블에서 소규모 행을 그룹화하여 합계, 평균, 최댓값, 최솟값 등을 계산할 수 있다.
- HAVING 구에 조건문을 사용한다.
- ORDER BY 를 사용해서 정렬을 할 수 있다.
SELECT deptno.SUM(sal)
FROM EMP
GROUP BY deptno;
- 위의 예는 부서별 합계를 계산한다.
HAVING 문 사용
- GROUP BY 에 조건절을 사용하려면 HAVING을 사용해야 한다.
- WHERE 절에 조건문을 사용하면, 조건을 충족하지 못하는 데이터들은 GROUP BY 대상에서 제외된다.
SELECT deptno, SUM(sal)
FROM EMP
GROUP BY deptno
HAVING SUM(sal) >= 10000; /* GROUP BY 결과에서 급여 합계가 10000 이상인 데이터만 조회 */
집계 함수의 종류
| 함수 | 설명 |
| COUNT() | 행 수를 조회한다. |
| SUM() | 합계를 계산한다. |
| AVG() | 평균을 계산한다.. |
| MAX()와 MIN() | 최댓값과 최솟값을 계산한다. |
| STDDEV() | 표준편차를 계산한다. |
| VARIAN() | 분산을 계산한다. |
COUNT 함수
- COUNT() 함수 : 행 수를 계산하는 함수
- COUNT(*)는 NULL 값을 포함한 모든 행 수를 계산한다.
- 하지만 COUNT(컬럼명)은 NULL 값을 제외한 행 수를 계산한다.
/* 사용 예 1 */
SELECT COUNT(*) /* NULL을 포함한 전체 행 수를 계산 */
FROM EMP;
/* 사용 예 2 */
SELECT COUNT(mgr) /* NULL을 제외한 전체 행 수를 계산 */
FROM EMP;
GROUP BY 사용 예제
(1) 부서별(deptno), 관리자별(mgr) 급여 평균 계산
SELECT deptno, mgr, AVG(sal) /* 급여 평균 계산 */
FROM EMP
GROUP BY deptno, mgr; /* 부서별, 관리자별 소그룹을 만듦. */
(2) 직업별(job) 급여 합계 중에 급여(sal) 합계가 1000 이상인 직업
SELECT job, SUM(sal)
FROM EMP
GROUP BY job
HAVING SUM(sal) >= 1000; /* 직업별 그룹 합계 중에서 급여가 1000 이상인 직업 조회 */
(3) 사원번호 1000~1003번의 부서별 급여 합계
SELECT deptno, SUM(sal)
FROM EMP
WHERE empno BETWEEN 1000 AND 1003 /* 사원번호 별 조회 조건은 WHERE 절에 넣어야 함. */
GROUP BY deptno;
⑦ SELECT 문 실행 순서
- SQL의 실행 순서는 결과로 조회된 데이터를 이해하는 데 아주 중요한 요소이다.
- SELECT 문은 다음의 순서로 실행된다.
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
SELECT ename /* (5) */
FROM EMP /* (1) */
WHERE empno=10 /* (2) */
GROUP BY ename /* (3) */
HAVING COUNT(*) >= 1 /* (4) */
ORDER BY ename; /* (6) */
⑧ 명시적(Explicit) 형변환과 암시적(Implicit) 형변환
- 형변환
- 2개의 데이터의 데이터 타입(형)이 일치하도록 변환하는 것
- 예) 숫자와 문자열의 비교, 문자열과 날짜형의 비교 (데이터 타입이 불일치할 때 발생)
- 구분
- 명시적(Explicit) 형변환
- 형변환 함수를 사용해서 데이터 타입을 일치시키는 것
- 개발자가 SQL을 사용할 때 형변환 함수를 사용해야 한다.
- 암시적(Implicit) 형변환
- 개발자가 형변환을 하지 않은 경우, 데이터베이스 관리 시스템이 자동으로 형변환을 수행하는 것
- 명시적(Explicit) 형변환
- 형변환 함수
| 형변환 함수 | 설명 |
| TO_NUMBER(문자열) | 문자열을 숫자로 변환한다. |
| TO_CHAR(숫자 혹은 날짜, [FORMAT]) | - 숫자 혹은 날짜를 지정된 FORMAT의 문자로 변환한다. - 형변환 함수 중에서 가장 많이 사용된다. |
| TO_DATE(문자열, FORMAT) | 문자열을 지정된 FORMAT의 날짜형으로 변환한다. |
- 인덱스 칼럼에 형변환을 수행하면 인덱스를 사용하지 못한다.
- 인덱스는 데이터를 빠르게 조회하기 위해서 인덱스 키를 기준으로 정렬해 놓은 데이터이다.
- 그런데 인덱스는 기본적으로 변형이라는 것이 발생하면 인덱스를 사용할 수 없다.
- 물론 예외적인 것도 있다.
- 따라서 인덱스가 있어도 인덱스 칼럼에 형변환이 발생하면 인덱스를 사용할 수 없다.
SELECT *
FROM EMP
WHERE empno='100'; /* 문자형 데이터 타입 '100'이다. 따라서 암시적 형변환이 발생한다. */
/* empno : EMP 테이블을 생성할 때 숫자형 데이터 타입으로 생성했다. */- empno 칼럼은 숫자형 타입이고, 기본키이므로 자동으로 인덱스가 있다.
- 하지만 암시적 형변환으로 empno가 TO_CHAR(empno)로 변환되므로 인덱스를 사용할 수 없다.
- 이와 같은 문제는 명시적 형변환을 사용하면 된다.
- WHERE empno=TO_NUMBER('100') 으로 하면 empno 칼럼이 변환되지 않아서 인덱스를 사용할 수 있다.
⑨ 내장형 함수(BUILT-IN Function)
내장형 함수
- 모든 데이터베이스는 SQL에서 사용할 수 있는 내장형 함수를 가지고 있다.
- 내장형 함수는 데이터베이스 관리 시스템 벤더별로 약간의 차이가 있지만, 거의 비슷한 방법으로 사용이 가능하다.
- 종류
- 형변환 함수
- 문자열 및 숫자형 함수
- 날짜형 함수
DUAL 테이블
- Oracle 데이터베이스에 의해서 자동으로 생성되는 테이블
- Oracle 데이터베이스 사용자가 임시로 사용할 수 있는 테이블로, 내장형 함수를 실행할 때도 사용할 수 있다.
- Oracle 데이터베이스의 모든 사용자가 사용할 수 있다.
DESC DUAL; /* Oracle은 기본적으로 DUAL 테이블이라는 Dummy 테이블이 존재한다. */
내장형 함수의 종류
- 함수를 중첩해서 사용해도 된다.
- 예) LENGTH(LTRIM(' ABC'))
- DUAL 테이블에 문자형 내장형 함수를 사용하면 다음과 같다.
SELECT ASCII('a'), SUBSTR('ABC', 1, 2), LENGTH('A BC'), LTRIM(' ABC'), LENGTH(LTRIM(' ABC'))
FROM DUAL| ASCII('A') | SUBSTR('ABC', 1, 2) | LENGTH('A BC') | LTRIM('ABC') | LENGTH(LTRIM('ABC')) |
| 97 | AB | 4 | ABC | 3 |
문자열 함수
| 함수 | 설명 |
| ASCII(문자) | 문자 혹은 숫자를 ASCII 코드값으로 변환한다. |
| CHAR(ASCII 코드값) | ASCII 코드값을 문자로 변환한다. |
| SUBSTR(문자열, m, n) | 문자열에서 m번째 위치부터 n개를 자른다. |
| CONCAT(문자열1, 문자열2) | - 문자열1 과 문자열2 를 결합한다. - Oracle은 '||', MS-SQL은 '+'를 사용할 수 있다. |
| LOWER(문자열) | 영문자를 소문자로 변환한다. |
| UPPER(문자열) | 영문자를 대문자로 변환한다. |
| LENGTH(문자열) 혹은 LEN(문자열) | 공백을 포함해서 문자열의 길이를 알려준다. |
| LTRIM(문자열, 지정문자) | - 왼쪽에서 지정된 문자를 삭제한다. - 지정된 문자를 생략하면 공백을 삭제한다. |
| RTRIM(문자열, 지정문자) | - 오른쪽에서 지정된 문자를 삭제한다. - 지정된 문자를 생략하면 공백을 삭제한다. |
| TRIM(문자열, 지정문자) | - 왼쪽 및 오른쪽에서 지정된 문자를 삭제한다. - 지정된 문자를 생략하면 공백을 삭제한다. |
날짜형 함수
| 함수 | 설명 |
| SYSDATE | 오늘의 날짜를 날짜 타입으로 알려준다. |
| EXTRACT('YEAR' | 'MONTH' | 'DAY' from dual) | 날짜에서 년, 월, 일을 조회한다. |
SELECT SYSDATE, EXTRACT(YEAR FROM SYSDATE), TO_CHAR(SYSDATE, 'YYYYMMDD')
FROM DUAL;
숫자형 함수
| 함수 | 설명 |
| ABS(숫자) | 절댓값을 돌려준다. |
| SIGN(숫자) | 양수, 음수, 0을 구별한다. |
| MOD(숫자1, 숫자2) | - 숫자1을 숫자2로 나누어 나머지를 계산한다. - %를 사용해도 된다. (숫자1 % 숫자2) |
| CEIL(숫자) / CEILING(숫자) | 숫자보다 크거나 같은 최소의 정수를 돌려준다. (올림) |
| FLOOR(숫자) | 숫자보다 작거나 같은 최대의 정수를 돌려준다. (내림) |
| ROUND(숫자, m) | - 소수점 m 자리에서 반올림한다. - m의 기본값(Default Value)은 0이다. |
| TRUNC(숫자, m) | - 소수점 m 자리에서 절삭한다. - m의 기본값(Default Value)은 0이다. |
SELECT ABS(-1), SIGN(10), MOD(4, 2), CEIL(10.9), FLOOR(10.1), ROUND(10.222, 1)
FROM DUAL;
⑩ DECODE와 CASE 문
DECODE 문
- DECODE 문으로 IF 문을 구현할 수 있다.
- 특정 조건이 참이면 A, 거짓이면 B로 응답한다.
DECODE(empno, 1000, 'TRUE', 'FALSE') /* 비교문으로, empno=1000과 같으면 TRUE를, 같지 않으면 FALSE를 응답 */
사용 예
SELECT DECODE(empno, 1000, 'TRUE', 'FALSE')
FROM EMP;
CASE 문
- IF ~ THEN ~ ELSE ~ END 의 프로그래밍 언어처럼 조건문을 사용할 수 있다.
- 조건을 WHEN 구에 사용하고, THEN 은 해당 조건이 참이면 실행되고 거짓이면 ELSE 구가 실행된다.
CASE [ expression ]
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
...
WHEN condition_n THEN result_n
ELSE result
END
사용 예
SELECT CASE
WHEN empno = 1000 THEN 'A'
WHEN empno = 1001 THEN 'B'
ELSE 'C'
END
FROM EMP;
⑪ ROWNUM과 ROWID
ROWNUM
- Oracle 데이터베이스의 SELECT 문 결과에 대해서 논리적인 일련번호를 부여한다.
- 조회되는 행 수를 제한할 때 많이 사용된다.
- 화면에 데이터를 출력할 때 부여되는 논리적 순번이다.
- 만약 ROWNUM을 사용해서 페이지 단위 출력을 하기 위해서는 인라인 뷰(Inline View)를 사용해야 한다.
- 인라인 뷰(Inline View)
- SELECT 문에서 FROM 절에 사용되는 서브쿼리(Sub Query)
- FROM 에 SELECT 문을 사용하면 인라인 뷰라고 한다.
SELECT * FROM /* Main Query */ (SELECT * FROM EMP) a; /* Sub Query (Inline View) */
- FROM 에 SELECT 문을 사용하면 인라인 뷰라고 한다.
- 1, 2, 3, 4, 5, 6, ... 같이 순차적으로 증가하는 ROWNUM 데이터를 얻고 싶을 때 인라인 뷰를 사용한다.
- SELECT 문에서 FROM 절에 사용되는 서브쿼리(Sub Query)
- 인라인 뷰(Inline View)
- 만약 ROWNUM을 사용해서 페이지 단위 출력을 하기 위해서는 인라인 뷰(Inline View)를 사용해야 한다.
- Oracle은 ROWNUM을 사용하지만, SQL Server는 TOP 문을 사용하고 MySQL은 LIMIT 구를 사용한다.
/* 10명만 인출(Fetch)하고자 할 경우 */
/* (1) SQL Server */
SELECT TOP(10)
FROM EMP;
/* (2) MySQL */
SELECT *
FROM EMP
LIMIT 10;
사용 예
SELECT *
FROM EMP
WHERE ROWNUM <= 1; /* 한 행을 조회 */- 여러 행을 조회하기 위해서는 인라인 뷰를 사용하고 ROWNUM에 별칭(Alias)을 사용해야 한다.
SELECT *
FROM (SELECT ROWNUM list, ename FROM EMP) /* ROWNUM에 별칭(list)을 사용 */
WHERE list <= 5; /* 5건의 행을 조회 */- ROWNUM 과 BETWEEN 구를 사용해서 웹 페이지 조회를 구현할 수 있다.
SELECT *
FROM (SELECT ROWNUM list, ename FROM EMP) /* 웹 게시판에서 많이 사용되는 SELECT 문 */
WHERE list BETWEEN 5 AND 10; /* 특정 행만 조회 */
ROWID
- Oracle 데이터베이스 내에서 데이터를 구분할 수 있는 유일한 값
- ROWID 는 "SELECT ROWID, empno, FROM EMP"와 같은 SELECT 문으로 확인할 수 있다.
- ROWID를 통해서 데이터가 어떤 데이터 파일, 어느 블록에 저장되어 있는지 알 수 있다.
ROWID 구조
| 구조 | 길이 | 설명 |
| 오브젝트 번호 | 1~6 | 오브젝트(Object) 별로 유일한 값을 가지고 있으며, 해당 오브젝트가 속해 있는 값이다. |
| 상대 파일 번호 | 7~9 | 테이블스페이스(Tablespace)에 속해 있는 데이터 파일에 대한 상대 파일 번호이다. |
| 블록 번호 | 10~15 | 데이터 파일 내부에서 어느 블록에 데이터가 있는지 알려준다. |
| 데이터 번호 | 16~18 | 데이터 블록에 데이터가 저장되어 있는 순서를 의미한다. |
SELECT ROWID, winetypename /* ROWID를 조회 */
FROM WINETYPE;
⑫ WITH 구문
- 서브 쿼리(Sub Query)를 사용해서 임시 테이블이나 뷰처럼 사용할 수 있는 구문
- 서브 쿼리 블록에 별칭(Alias)를 지정할 수 있다.
- 옵티마이저는 SQL을 인라인 뷰나 임시 테이블로 판단한다.
/* 사용 예 1 */
WITH viewData AS
(SELECT * FROM EMP
UNION ALL
SELECT * FROM EMP) /* 서브 쿼리를 사용해서 임시 테이블을 만듦. */
SELECT * FROM viewData WHERE empno=1000;
/* 사용 예 2 */
/* EMP 테이블에서 WITH 구문을 사용해서 부서번호(deptno)가 30인 것의 임시 테이블을 만들고 조회하기 */
WITH W_EMP AS
(SELECT * FROM EMP WHERE deptno=30)
SELECT * FROM W_EMP;
⑬ DCL(Data Control Language)
GRANT
- GRANT 문은 데이터베이스 사용자에게 권한을 부여한다.
- 데이터베이스 사용을 위해서는 권한이 필요하며 연결, 입력, 수정, 삭제, 조회를 할 수 있다.
GRANT privileges ON object TO user;
/* privileges : 권한, object : 테이블명, user : Oracle 데이터베이스 사용자 */
권한
| 권한 | 설명 |
| SELECT | 지정된 테이블에 대해서 SELECT 권한을 부여한다. |
| INSERT | 지정된 테이블에 대해서 INSERT 권한을 부여한다. |
| UPDATE | 지정된 테이블에 대해서 UPDATE 권한을 부여한다. |
| DELETE | 지정된 테이블에 대해서 DELETE 권한을 부여한다. |
| REFERENCES | 지정된 테이블을 참조하는 제약조건을 생성하는 권한을 부여한다. |
| ALTER | 지정된 테이블에 대해서 수정할 수 있는 권한을 부여한다. |
| INDEX | 지정된 테이블에 대해서 인덱스를 생성할 수 있는 권한을 부여한다. |
| ALL | 테이블에 대한 모든 권한을 부여한다. |
GRANT SELECT, INSERT, UPDATE, DELETE
ON EMP
TO STARRYKSS
/* STARRYKSS 사용자에게 EMP 테이블에 대해서 SELECT, UPDATE, DELETE 권한을 부여함. */
WITH GRANT OPTION
| GRANT 옵션 | 설명 |
| WITH GRANT OPTION | - 특정 사용자에게 권한을 부여할 수 있는 권한을 부여한다. - 권한을 A 사용자가 B에 부여하고, B가 다시 C를 부여한 후에 권한을 취소(REVOKE)하면 모든 권한이 회수된다. |
| WITH ADMIN OPTION | - 테이블에 대한 모든 권한을 부여한다. - 권한을 A 사용자가 B에 부여하고, B가 다시 C에게 부여한 후에 권한을 취소(REVOKE)하면 B사용자 권한만 취소된다. |
GRANT SELECT, INSERT, UPDATE, DELETE
ON EMP
TO STARRYKSS WITH GRANT OPTION
/* STARRYKSS 사용자에게 권한을 부여할 수 있는 권한을 부여함. */
REVOKE
- REVOKE 문은 데이터베이스 사용자에게 부여된 권한을 회수한다.
REVOKE privileges ON object FROM user;
⑭ TCL(Transaction Control Language)
COMMIT
- COMMIT은 INSERT, UPDATE, DELETE 문으로 변경한 데이터를 데이터베이스에 반영한다.
- 변경 전 이전 데이터는 잃어버린다.
- A 값을 B로 변경하고 COMMIT을 하면 A 값은 읽어버리고 B 값을 반영한다.
- 다른 모든 데이터베이스 사용자는 변경된 데이터를 볼 수 있다.
- COMMIT이 완료되면 데이터베이스 변경으로 인한 LOCK이 해제(UNLOCK)된다.
- COMMIT이 완료되면 다른 모든 데이터베이스 사용자는 변경된 데이터를 조작할 수 있다.
- COMMIT을 실행하면 하나의 트랜잭션 과정을 종료한다.

- Oracle 데이터베이스는 암시적 트랜잭션 관리를 한다.
- Oracle 데이터베이스로 트랜잭션을 시작하고, 트랜잭션의 종료는 Oracle 데이터베이스 사용자가 COMMIT 혹은 ROLLBACK으로 처리해야 한다.
Auto Commit
- SQL*PLUS 프로그램을 정상적으로 종료하는 경우 자동 COMMIT 된다.
- DDL 및 DCL을 사용하는 경우 자동 COMMIT 된다.
- "SET AUTOCOMMIT ON;" 을 SQL*PLUS에서 실행하면 자동 COMMIT 된다.
사용 예
> COMMIT;
ROLLBACK
- ROLLBACK 을 실행하면 데이터에 대한 변경 사용을 모두 취소하고 트랜잭션을 종료한다.
- INSERT, UPDATE, DELETE 문의 작업을 모두 취소한다.
- 단, 이전에 COMMIT 한 곳까지만 복구한다.
- ROLLBACK 을 실행하면 LOCK이 해제되고, 다른 사용자도 데이터베이스 행을 조작할 수 있다.
사용 예
> ROLLBACK;
SAVEPOINT (저장점)
- SAVEPOINT 는 트랜잭션을 작게 분할하여 관리하는 것으로, SAVEPOINT를 사용하면 지정된 위치 이후의 트랜잭션만 ROLLBACK 할 수 있다.
- SAVEPOINT의 지정 : SAVEPOINT <SAVEPOINT명> 실행
- 지정된 SAVEPOINT까지만 데이터 변경을 취소하고 싶을 경우 : ROLLBACK TO <SAVEPOINT명> 실행
- ROLLBACK 을 실행하면 SAVEPOINT와 관계 없이 데이터의 모든 변경사항을 저장하지 않는다.
사용 예
SAVEPOINT t1; /* SAVEPOINT t1 지정 */
INSERT INTO EMP VALUES(10, 20);
SAVEPOINT t2; /* SAVEPOINT t2 지정 */
INSERT INTO EMP VALUES(20, 30);
ROLLBACK TO t2; /* SAVEPOINT t2까지 변경된 것을 취소 */
COMMIT;
SELECT * FROM EMP; /* EMPNO : 10, DEPTNO : 20 */
728x90
'Certificate > SQLD' 카테고리의 다른 글
| [SQLD] 실전 문제 : 데이터 모델과 성능 (0) | 2022.06.23 |
|---|---|
| [SQLD] 실전 문제 : 데이터 모델링의 이해 (0) | 2022.06.21 |
| [SQLD] SQL 최적화의 원리 (0) | 2022.01.20 |
| [SQLD] SQL 활용 (0) | 2022.01.19 |
| [SQLD] 데이터 모델과 성능 (0) | 2022.01.17 |
| [SQLD] 데이터 모델링(Data Modeling) (0) | 2022.01.14 |
| [SQLD] SQLD 소개 (0) | 2022.01.13 |
| 국가공인 SQL 개발자(SQLD) 자격증 시험 개요 (0) | 2022.01.13 |

