728x90
[SQLD] SQL 활용
① 조인(Join)
EQUI(등가) 조인 (교집합)
(1) EQUI(등가) 조인
- 조인 : 여러 개의 릴레이션을 사용해서 새로운 릴레이션을 만드는 과정
- 조인의 가장 기본은 교집합을 만드는 것이다.
- 2개의 테이블 간에 일치하는 것을 조인한다.
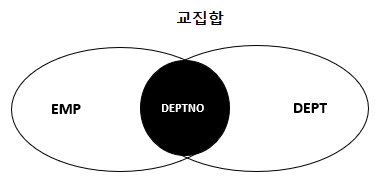
- EQUI 조인은 <EMP> 테이블과 <DEPT> 테이블에서 DEPTNO 칼럼을 사용하여 같은 것을 조인한다.

사용 예
SELECT *
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO;
- EQUI 조인은 '='을 사용해서 2개의 테이블을 연결한다.
SELECT *
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
AND EMP.ENAME LIKE '임%' /* 조인문에 추가 조건 및 정렬을 할 수 있음. */
ORDER BY ENAME;
(2) INNER JOIN
- EQUI 조인과 마찬가지로 ISO 표준 SQL이다.
- INNER JOIN은 ON 문을 사용해서 테이블을 연결한다.
사용 예
SELECT *
FROM EMP INNER JOIN DEPT /* INNER JOIN 구로 테이블 정의 */
ON EMP.DEPTNO = DEPT.DEPTNO; /* ON 구를 사용해서 조인의 조건을 넣음. */- 조인문에 추가 조건 및 정렬을 할 수 있다.
SELECT *
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO
AND EMP.ENAME LIKE '임%'
ORDER BY ENAME;- EQUI 조인을 한 후에 실행 계획을 확인해서 내부적으로 2개의 테이블을 어떻게 연결했는지 확인할 수 있다.
- <DEPT> 테이블과 <EMP> 테이블 전체를 읽은 다음에(TABLE ACCESS FULL) 해시 함수를 사용해서 2개의 테이블을 연결하였다.
- 해시 조인(Hash Join)
- 테이블을 해시 메모리에 적재한 후에 해시 함수로써 연결하는 방법
- EQUI 조인만 사용 가능한 방법
- 과정
- 먼저 선행 테이블을 결정하고 선행 테이블에서 주어진 조건(WHERE 구)에 해당하는 행을 선택한다.
- 해당 행이 선택되면 조인 키(Join Key)를 기준으로 해시 함수를 사용해서 해시 테이블을 메인 메모리(Main Memory)에 생성하고, 후행 테이블에서 주어진 조건에 만족하는 행을 찾는다.
- 후행 테이블의 조인 키를 사용해서 해시 함수를 적용하여 해당 버킷을 검색한다.
- 해시 조인(Hash Join)
- <DEPT> 테이블과 <EMP> 테이블 전체를 읽은 다음에(TABLE ACCESS FULL) 해시 함수를 사용해서 2개의 테이블을 연결하였다.
(3) INTERSECT 연산
- 2개의 테이블에서 교집합을 조회한다.
- 2개의 테이블에서 공통된 값을 조회한다.
사용 예
SELECT DEPTNO FROM EMP
INTERSECT /* 2개의 테이블에서 교집합을 조회 */
SELECT DEPTNO FROM DEPT;
Non-EQUI(비등가) 조인
- 2개의 테이블 간에 조인하는 경우, '='을 사용하지 않고 '>', '<', '>=', '<=' 등을 사용한다.
- 정확하게 일치하지 않는 것을 조인하는 것이다.
OUTER JOIN
- 2개의 테이블 간에 교집합(EQUI JOIN)을 조회하고, 한쪽 테이블에만 있는 데이터도 포함시켜 조회한다.
- 예) <DEPT> 테이블과 <EMP> 테이블을 OUTER JOIN 할 경우
- DEPTNO가 같은 것을 조회하고, <DEPT> 테이블에만 있는 DEPTNO도 포함시킨다.
- 왼쪽 테이블에만 있는 행을 포함하면 LEFT OUTER JOIN, 오른쪽 테이블의 행만 포함시키면 RIGHT OUTER JOIN 이라고 한다.
- DEPTNO가 같은 것을 조회하고, <DEPT> 테이블에만 있는 DEPTNO도 포함시킨다.
- FULL OUTER JOIN 은 LEFT OUTER JOIN 과 RIGHT OUTER JOIN 모두를 하는 것이다.
- Oracle 데이터베이스에서는 OUTER JOIN을 "(+)" 기호를 사용해서 할 수 있다.
사용 예
SELECT *
FROM DEPT, EMP
WHERE EMP.DEPTNO (+)= DEPT.DEPTNO; /* Oracle 데이터베이스의 OUTER JOIN 방법 */
(1) LEFT OUTER JOIN 과 RIGHT OUTER JOIN
- LEFT OUTER JOIN
- 2개의 테이블에서 같은 것을 조회하고, 왼쪽 테이블에만 있는 것을 포함해서 조회한다.

SELECT *
FROM DEPT LEFT OUTER JOIN EMP
ON EMP.DEPTNO = DEPT.DEPTNO;| 부서명 | 부서코드 | 부서코드_1 | 이름 |
| 인사팀 | 10 | 10 | 유비 |
| 총무팀 | 20 | 20 | 조조 |
| IT팀 | 30 | 30 | 관우 |
| 운영팀 | 40 |
- RIGHT OUTER JOIN
- 2개의 테이블에서 같은 것을 조회하고, 오른쪽 테이블에만 있는 것을 포함해서 조회한다.

SELECT *
FROM DEPT RIGHT OUTER JOIN EMP
ON EMP.DEPTNO = DEPT.DEPTNO;| 관리자명 | 관리자 | 사원번호 | 이름 |
| 유비 | 1000 | 1000 | 마초 |
| 주유 | 1001 | 1001 | 조조 |
| 1002 | 관우 | ||
| 1003 | 장비 |
CROSS JOIN
- 조인 조건구 없이 2개의 테이블을 하나로 조인한다.
- 조인구가 없기 때문에 카타시안 곱(Cartesian Product)이 발생한다.
- 예) 14개의 행이 있는 테이블과 4개의 행이 있는 테이블을 조인하면 56개의 행이 조회된다.
- CROSS JOIN은 FROM 절에 CROSS JOIN 구를 사용하면 된다.
사용 예
SELECT *
FROM EMP CROSS JOIN DEPT;
UNION을 사용한 합집합 구현
(1) UNION
- 2개의 테이블을 하나로 만드는 연산
- 2개의 테이블 칼럼 수, 칼럼의 데이터 형식 모두가 일치해야 한다.
- 그렇지 않을 경우 오류가 발생한다.

- UNION 연산은 2개의 테이블을 하나로 합치면서 중복된 데이터를 제거한다.
- 그래서 UNION은 정렬(SORT) 과정을 발생시킨다.
사용 예
SELECT DEPTNO FROM EMP
UNION /* UNION은 중복된 데이터를 제거하면서 테이블을 합침. */
SELECT DEPTNO FROM EMP;
(2) UNION ALL
- 2개의 테이블을 하나로 합치는 것
- UNION 처럼 중복을 제거하거나, 정렬을 유발하지는 않는다.
사용 예
SELECT DEPTNO FROM EMP
UNION ALL /* 중복을 제거하지 않고 테이블을 합침. */
SELECT DEPTNO FROM EMP;
차집합을 만드는 MINUS
- MINUS 연산은 2개의 테이블에서 차집합을 조회한다.
- 먼저 쓴 SELECT 문에는 있고 뒤에 쓰는 SELECT 문에는 없는 집합을 조회한다.
- MS-SQL에서는 MINUS와 동일한 연산으로 EXCEPT 가 사용된다.

사용 예
SELECT DEPTNO FROM DEPT /* DEPT : {10, 20, 30, 40} */
MINUS
SELECT DEPTNO FROM EMP; /* EMP : {10, 20, 30} */| DEPTNO |
| 40 |
- <DEPT> 테이블에만 존재하는 40이 조회되는 것을 확인할 수 있다.
② 계층형 조회(CONNECT BY)
- Oracle 데이터베이스에서 지원하며, 계층형으로 데이터를 조회할 수 있다.
- 역방향 조회도 가능하다.
- 예) 부장에서 차장, 차장에서 과장, 과장에서 대리, 대리에서 사원 순으로 트리 형태의 구조를 위에서 아래로 탐색하면서 조회
사용 예
- 계층형 조회 테스트 데이터 입력
CREATE TABLE EMP(
EMPNO NUMBER(10) PRIMARY KEY,
ENAME VARCHAR2(20),
DEPTNO NUMBER(10),
MGR NUMBER(10),
JOB VARCHAR2(20),
SAL NUMBER(10)
);
INSERT INTO EMP VALUES(1000, 'TEST1', 20, NULL, 'CLERK', 800);
INSERT INTO EMP VALUES(1001, 'TEST2', 30, 1000, 'SALESMAN', 1600);
INSERT INTO EMP VALUES(1002, 'TEST3', 30, 1000, 'SALESMAN', 1250);
INSERT INTO EMP VALUES(1003, 'TEST4', 20, 1000, 'MANAGER', 2975);
INSERT INTO EMP VALUES(1004, 'TEST5', 30, 1000, 'SALESMAN', 1250);
INSERT INTO EMP VALUES(1005, 'TEST6', 30, 1001, 'MANAGER', 2850);
INSERT INTO EMP VALUES(1006, 'TEST7', 10, 1001, 'MANAGER', 2450);
INSERT INTO EMP VALUES(1007, 'TEST8', 20, 1006, 'ANALYST', 3000);
INSERT INTO EMP VALUES(1008, 'TEST9', 30, 1006, 'PRESIDENT', 5000);
INSERT INTO EMP VALUES(1009, 'TEST10', 30, 1002, 'SALESMAN', 1500);
INSERT INTO EMP VALUES(1010, 'TEST11', 20, 1002, 'CLERK', 1100);
INSERT INTO EMP VALUES(1011, 'TEST12', 30, 1001, 'CLERK', 950);
INSERT INTO EMP VALUES(1012, 'TEST13', 20, 1000, 'ANALYST', 3000);
INSERT INTO EMP VALUES(1013, 'TEST14', 10, 1000, 'CLERK', 1300);
COMMITSELECT MAX(LEVEL) /* LEVEL은 계층값을 가지고 있다. */
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;| MAX(LEVEL) |
| 4 |
- 트리의 최대 깊이 : 4
- CONNECT BY : 트리(Tree) 형태의 구조로 질의를 수행하는 것
- START WITH 구 : 시작 조건
- CONNECT BY PRIOR 구 : 조인 조건
- 루트 노드로부터 하위 노드의 질의를 실행한다.
- 계층형 조회에서 MAX(LEVEL)을 사용하여 최대 계층 수를 구할 수 있다.
- 계층형 구조에서 마지막 리프 노드(Leaf Node)의 계층값을 구한다.
SELECT LEVEL, EMPNO, MGR, ENAME
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;| LEVEL | EMPNO | MGR | ENAME | 비고 |
| 1 | 1000 | - | TEST1 | ROOT(최상위) |
| 2 | 1001 | 1000 | TEST2 | |
| 3 | 1005 | 1001 | TEST6 | |
| 3 | 1006 | 1001 | TEST7 | |
| 4 | 1007 | 1006 | TEST8 | |
| 4 | 1008 | 1006 | TEST9 | |
| 3 | 1011 | 1001 | TEST12 | |
| 2 | 1002 | 1000 | TEST3 | EMPNO 1001번과 1002번의 관리자는 EMPNO 1000번 |
| 3 | 1009 | 1002 | TEST10 |  |
| 3 | 1010 | 1002 | TEST11 | |
| 2 | 1003 | 1000 | TEST4 | |
| 2 | 1004 | 1000 | TEST5 | |
| 2 | 1012 | 1000 | TEST13 | |
| 2 | 1013 | 1000 | TEST14 |
- 계층형 조회 결과를 명확히 보기 위해서 LPAD 함수를 사용할 수 있다.
- 4 * (LEVEL - 1)
- LEVEL 값이 루트(Root)이면 1이 된다. 따라서 4 * (1 - 1) = 0 이 된다.
- LAPD(' ', 0)이므로 아무런 의미가 없다.
- LEVEL 값이 2이면 4 * (2 - 1) = 4가 된다.
- LPAD(' ', 4)이므로 왼쪽 공백 4칸을 화면에 출력한다.
- LEVEL 값이 루트(Root)이면 1이 된다. 따라서 4 * (1 - 1) = 0 이 된다.
- 4 * (LEVEL - 1)
SELECT LEVEL, LPAD(' ', 4 * (LEVEL - 1)) || EMPNO, MGR, CONNECT_BY_ISLEAF, ENAME
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;
CONNECT BY 키워드
| 키워드 | 설명 |
| LEVEL | - 검색 항목의 깊이를 의미한다. - 계층 구조에서 최상위 레벨이 1이 된다. |
| CONNECT_BY_ROOT | 계층 구조에서 가장 최상위 값을 표시한다. |
| CONNECT_BY_ISLEAF | 계층 구조에서 가장 최하위 값을 표시한다. |
| SYS_CONNECT_BY_PATH | 계층 구조에서 전체 전개 경로를 표시한다. |
| NOCYCLE | 순환 구조가 발생 지점까지만 전개된다. |
| CONNECT_BY_ISCYCLE | 순환구조 발생 지점을 표시한다. |
③ 서브쿼리(Subquery)
메인 쿼리(Main Query)와 서브쿼리(Subquery)
- 서브쿼리(Subquery)
- SELECT 문 내에 다시 SELECT 문을 사용하는 SQL문
- 형태
- 인라인 뷰(Inline View) : FROM 구에 SELECT 문 사용
- 스칼라 서브쿼리(Scala Subquery) : SELECT 문에 서브쿼리(Subqery) 사용
- WHERE 구에 SELECT 문 사용
사용 예
SELECT *
FROM EMP
WHERE DEPTNO = (SELECT DEPTNO /* 서브쿼리 */
FROM DEPT
WHERE DEPTNO=10);- 서브쿼리 밖에 있는 SELECT 문은 메인 쿼리(Main Query) 이다.
SELECT *
FROM (SELECT ROWNUM NUM, ENAME /* 인라인 뷰(Inline View) */
FROM EMP) a
WHERE NUM < 5;- FROM 구에 SELECT 문을 사용하여 가상의 테이블을 만드는 효과를 얻을 수 있다.
단일 행 서브쿼리와 다중 행 서브쿼리
- 서브쿼리(Subquery)는 반환하는 행의 개수에 따라 다음과 같이 분류된다.
- 단일 행 서브쿼리
- 멀티 행 서브쿼리
| 서브쿼리 종류 | 설명 |
| 단일 행 서브쿼리 (Single Row Subquery) |
- 서브쿼리를 실행하면 그 결과는 반드시 한 행만 조회된다. - 비교 연산자인 =, <, <=, >, >=, <> 를 사용한다. |
| 다중 행 서브쿼리 (Multi Row Subquery) |
- 서브쿼리를 실행하면 그 결과는 여러 개의 행이 조회된다. - 다중 행 비교 연산자인 IN, ANY, ALL, EXISTS 를 사용한다. |
다중 행 서브쿼리(Multi Row Subquery)
- 서브쿼리 결과가 여러 개의 행을 반환하는 것
- 다중 행 연산자를 사용해야 한다.
다중 행 비교 연산자
| 연산자 | 설명 |
| IN(Subquery) | 메인 쿼리의 비교 조건이 서브쿼리의 결과 중 하나만 동일하면 참이 된다. (OR 조건) |
| ALL(Subquery) | - 메인 쿼리와 서브쿼리의 결과가 모두 동일하면 참이 된다. - < ALL : 최솟값을 반환한다. - > ALL : 최댓값을 반환한다. |
| ANY(Subquery) | - 메인 쿼리의 비교조건이 서브쿼리의 결과 중 하나 이상 동일하면 참이 된다. - < ANY : 하나라도 크게 되면 참이 된다. - > ANY : 하나라도 작게 되면 참이 된다. |
| EXISTS(Subquery) | 메인 쿼리와 서브쿼리의 결과가 하나라도 존재하면 참이 된다. |
(1) IN
- 반환되는 여러 개의 행 중에서 하나만 참이 되어도 참이 되는 연산
사용 예
SELECT ENAME, DNAME, SAL
FROM EMP, DEPT
WHERE EMP.DEPTNO=DEPT.DEPTNO
AND EMP.EMPNO
IN (SELECT EMPNO
FROM EMP
WHERE SAL > 2000); /* 급여(SAL)가 2000 보다 큰 사원번호를 조회한 후, EMP.EMPNO 조회 */- <EMP> 테이블에서 SAL이 2000 이상인 사원번호를 반환하고, 반환된 사원번호와 메인 쿼리에 있는 사원번호와 비교해서 같은 것을 조회한다.
(2) ALL
- 메인 쿼리와 서브쿼리의 결과가 모두 동일하면 참이 되는 연산
사용 예
SELECT *
FOM EMP
WHERE DEPTNO <= ALL (20, 30) /* DEPTNO가 20, 30보다 작거나 같은 것을 조회 */
(3) EXISTS
- 서브쿼리로 어떤 데이터의 존재 여부를 확인하는 것
- 결과로 참 또는 거짓이 반환된다.
사용 예
SELECT ENAME, DNAME, SAL
FROM EMP, DEPT
WHERE EMP.DEPTNO=DEPT.DEPTNO
AND EXISTS (SELECT 1
FROM EMP
WHERE SAL > 2000); /* 급여(SAL)가 2000 보다 큰 사원이 있으면 TRUE가 조회됨. */
스칼라 서브쿼리(Scala Subquery)
- 반드시 한 행과 한 컬럼만 반환하는 서브쿼리
- 여러 행이 반환되면 오류가 발생한다.
사용 예
SELECT ENAME AS "이름"
SAL AS "급여"
(SELECT AVG(SAL) FROM EMP) AS "평균급여" /* 스칼라 서브쿼리, 1개의 행만 조회되어야 함. */
FROM EMP
WHERE EMPNO=1000;- 직원 급여를 조회할 때, 평균 급여를 같이 계산하여 조회한다.
연관 서브쿼리(Correlated Subquery)
- 서브쿼리 내에서 메인 쿼리 내의 칼럼을 사용하는 것
사용 예
SELECT *
FROM EMP a /* a : 연관 서브쿼리 */
WHERE a.DEPTNO = (SELECT DEPTNO
FROM DEPT b
WHERE b.DEPTNO = a.DEPTNO); /* 메인 쿼리에서 데이터를 받아서 서브쿼리를 실행 */
④ 그룹 함수(Group Function)
ROLLUP
- GROUP BY 의 칼럼에 대해서 소계(Subtotal)를 만들어 준다.
- ROLLUP 을 할 때, GROUP BY 구에 칼럼이 2개 이상 오면 순서에 따라서 결과가 달라진다.
사용 예
SELECT DECODE(DEPTNO, NULL, '전체합계', DEPTNO), SUM(SAL) /* DEPTNO가 NULL이면 '전체합계' 문자 출력 */
FROM EMP
GROUP BY ROLLUP(DEPTNO); /* ROLLUP을 사용하면 부서별 합계 및 전체합계가 계산됨. */| DECODE(DEPTNO, NULL, '전체합계', DEPTNO) | SUM(SAL) |
| 10 | 3750 |
| 20 | 10875 |
| 30 | 14400 |
| 전체합계 | 29025 |
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB); /* 부서별, 직업별 합계를 구함. ROLLUP은 소계를 구함. */| DEPTNO | JOB | SUM(SAL) | 비고 |
| 10 | CLERK | 1300 | |
| 10 | MANAGER | 2450 | |
| 10 | 3750 | 부서별 합계 | |
| 20 | CLERK | 1900 | |
| 20 | ANALYST | 6000 | |
| 20 | MANAGER | 2975 | |
| 20 | 10875 | 부서별, 직업별 합계 | |
| 30 | CLERK | 950 | |
| 30 | MANAGER | 2850 | |
| 30 | SALESMAN | 5600 | |
| 30 | PRESIDENT | 5000 | |
| 30 | 14400 | 전체 합계 | |
| 29025 |
- 부서별 합계, 직업별 합계, 전체 합계가 모두 조회된다.
- ROLLUP 으로 실행되는 칼럼별로 소계(Subtotal)을 만들어 준다.
GROUPING 함수
- ROLLUP, CUBE, GROUPING SETS 에서 생성되는 합계값을 구분하기 위해 만들어진 함수
- 예를 들어, 소계, 합계 등이 계산되면 GROUPING 함수는 1을 반환하고, 그렇지 않으면 0을 반환해서 합계값을 식별할 수 있다.
사용 예
SELECT DEPTNO, GROUPING(DEPTNO), JOB, GROUPING(JOB), SUM(SAL) /* GROUPING SETS으로 계산된 합계는 '1'로 표시 */
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);| DEPTNO | GROUPING(DEPTNO) | JOB | GROUPING(JOB) | SUM(SAL) | 비고 |
| 10 | 0 | CLERK | 0 | 1300 | |
| 10 | 0 | MANAGER | 0 | 2450 | |
| 10 | 0 | 1 | 3750 | ||
| 20 | 0 | CLERK | 0 | 1900 | |
| 20 | 0 | ANALYST | 0 | 6000 | |
| 20 | 0 | MANAGER | 0 | 2975 | |
| 20 | 0 | 1 | 10875 | ||
| 30 | 0 | CLERK | 0 | 950 | |
| 30 | 0 | MANAGER | 0 | 2850 | |
| 30 | 0 | SALESMAN | 0 | 5600 | |
| 30 | 0 | PRESIDENT | 0 | 5000 | |
| 30 | 0 | 1 | 14400 | '1'의 값으로 소계와 전체 합계를 개발자가 구분할 수 있게 된다. | |
| 1 | 1 | 29025 |
- 소계와 합계가 계산된 데이터는 GROUPING 함수에서 '1'이 출력된 것을 확인할 수 있다.
- GROUPING 함수는 반환값을 DECODE 혹은 CASE 문으로 식별해서 SELECT 문으로 '소계', '합계'를 구분해준다.
SELECT DEPTNO,
DECODE(GROUPING(DEPTNO), 1, '전체합계') TOT, /* DECODE를 사용해서 전체 합계와 부서 합계를 구함. */
JOB, DECODE(GROUPING(JOB), 1, '부서합계') T_DEPT,
SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);| DEPTNO | TOT | JOB | T_DEPT | SUM(SAL) | 비고 |
| 10 | CLERK | 1300 | |||
| 10 | MANAGER | 2450 | |||
| 10 | 부서합계 | 3750 | |||
| 20 | CLERK | 1900 | |||
| 20 | ANALYST | 6000 | |||
| 20 | MANAGER | 2975 | |||
| 20 | 부서합계 | 10875 | |||
| 30 | CLERK | 950 | |||
| 30 | MANAGER | 2850 | |||
| 30 | SALESMAN | 5600 | |||
| 30 | PRESIDENT | 5000 | |||
| 30 | 부서합계 | 14400 | |||
| 전체합계 | 부서합계 | 29025 |
- GROUPING 함수를 사용하면 사용자가 필요로 하는 데이터를 SELECT 문으로 작성하여 제공할 수 있다.
GROUPING SETS 함수
- GROUP BY에 나오는 칼럼의 순서와 관계없이 다양한 소계(Subtotal)를 만들 수 있다.
- GROUP BY에 나오는 칼럼의 순서와 관계없이 개별적으로 모두 처리한다.
사용 예
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY GROUPING SETS(DEPTNO, JOB); /* DEPTNO와 JOB을 각각 그룹으로 합계를 계산함 */
/* DEPTNO와 JOB의 순서가 바뀌어도 결과는 같음. */| DEPTNO | JOB | SUM(SAL) | 비고 |
| CLERK | 4150 | 직업별 합계 | |
| SALESMAN | 5600 | ||
| PRESIDENT | 5000 | ||
| MANAGER | 8275 | ||
| ANALYST | 6000 | ||
| 30 | 14400 | 부서별 합계 | |
| 20 | 10875 | ||
| 10 | 3750 |
CUBE 함수
- CUBE 함수에 제시한 칼럼에 대해서 결합 가능한 모든 집계를 계산한다.
- 조합할 수 있는 경우의 수가 모두 조합된다.
- 다차원 집계를 제공하여 다양하게 데이터를 분석할 수 있게 한다.
- 예) 부서와 직업을 CUBE로 사용할 경우, 조회되는 것
- 부서별 합계
- 직업별 합계
- 부서별 직업별 합계
- 전체 합계
사용 예
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB); /* 모든 합계를 모두 계산하는 다차원 분석 수행 */| DEPTNO | JOB | SUM(SAL) | 비고 |
| 29025 | 전체 합계 | ||
| CLERK | 4150 | 직업별 합계 | |
| ANALYST | 6000 | ||
| MANAGER | 8275 | ||
| SALESMAN | 5600 | ||
| PRESIDENT | 5000 | ||
| 10 | 3750 | 부서별 합계 | |
| 10 | CLERK | 1300 | |
| 10 | MANAGER | 2450 | |
| 20 | 10875 | 부서별 합계 | |
| 20 | CLERK | 1900 | |
| 20 | ANALYST | 6000 | |
| 20 | MANAGER | 2975 | |
| 30 | 14400 | 부서별 합계 | |
| 30 | CLERK | 950 | 부서별, 직업별 합계 |
| 30 | MANAGER | 2850 | |
| 30 | SALESMAN | 5600 | |
| 30 | PRESIDENT | 5000 |
⑤ 윈도우 함수(Window Function)
윈도우 함수
- 행과 행 간의 관계를 정의하기 위해서 제공되는 함수
- 윈도우 함수를 사용해서 순위, 합계, 평균, 행 위치 등을 조작할 수 있다.
SELECT WINDOW_FUNCTION(ARGUMENTS)
OVER (PARTITION BY 칼럼
ORDER BY WINDOWING절)
FROM 테이블명;
- 윈도우 함수의 구조
| 구조 | 설명 |
| ARGUMENTS(인수) | 윈도우 함수에 따라서 0 ~ N개의 인수를 설정한다. |
| PARTITION BY | 전체 집합을 기준에 의해 소그룹으로 나눈다. |
| ORDER BY | 어떤 항목에 대해서 정렬한다. |
| WINDOWING | - 행 기준의 범위를 정한다. - ROWS : 물리적 결과의 행 수 - RANGE : 논리적인 값에 의한 범위 |
- WINDOWING
| 구조 | 설명 |
| ROWS | 부분집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정한다. |
| RANGE | 논리적인 주소에 의해 행 집합을 지정한다. |
| BETWEEN ~ AND | 윈도우의 시작과 끝의 위치를 지정한다. |
| UNBOUNDED PRECEDING | 윈도우의 시작 위치가 첫 번째 행임을 의미한다. |
| UNBOUNDED FOLLOWING | 윈도우 마지막 위치가 마지막 행임을 의미한다. |
| CURRENT ROW | 윈도우 시작 위치가 현재 행임을 의미한다. |
사용 예
SELECT EMPNO, ENAME, SAL,
SUM(SAL) OVER(ORDER BY SAL
ROWS BETWEEN UNBOUNDED PRECEDING /* 첫 번째 행 */
AND UNBOUNDED FOLLOWING) TOTSAL /* 마지막 행 */
FROM EMP;| EMPNO | ENAME | SAL | TOTSAL | 비고 |
| 1000 | TEST1 | 800 | 29025 | SAL의 전체 합계를 조회한다. |
| 1011 | TEST12 | 950 | 29025 | |
| 1010 | TEST11 | 1100 | 29025 | |
| 1002 | TEST3 | 1250 | 29025 | |
| 1004 | TEST5 | 1250 | 29025 | |
| 1013 | TEST14 | 1300 | 29025 | |
| 1009 | TEST10 | 1500 | 29025 | |
| 1001 | TEST2 | 1600 | 29025 | |
| 1006 | TEST7 | 2450 | 29025 | |
| 1005 | TEST6 | 2850 | 29025 | |
| 1003 | TEST4 | 2975 | 29025 | |
| 1007 | TEST8 | 3000 | 29025 | |
| 1012 | TEST13 | 3000 | 29025 | |
| 1008 | TEST9 | 5000 | 29025 |
SELECT EMPNO, ENAME, SAL,
SUM(SAL) OVER(ORDER BY SAL
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) TOTSAL /* 첫 번째 행부터 현재 행까지의 합계(누적합)를 구함. */
FROM EMP;| EMPNO | ENAME | SAL | TOTSAL | 비고 |
| 1000 | TEST1 | 800 | 800 | 행 별로 누적 합계를 구한다. |
| 1011 | TEST12 | 950 | 1750 | |
| 1010 | TEST11 | 1100 | 2850 | |
| 1002 | TEST3 | 1250 | 4100 | |
| 1004 | TEST5 | 1250 | 5350 | |
| 1013 | TEST14 | 1300 | 6650 | |
| 1009 | TEST10 | 1500 | 8150 | |
| 1001 | TEST2 | 1600 | 9750 | |
| 1006 | TEST7 | 2450 | 12200 | |
| 1005 | TEST6 | 2850 | 15050 | |
| 1003 | TEST4 | 2975 | 18025 | |
| 1007 | TEST8 | 3000 | 21025 | |
| 1012 | TEST13 | 3000 | 24025 | |
| 1008 | TEST9 | 5000 | 29025 |
- CURRENT ROW : 데이터가 인출된 현재 행
SELECT EMPNO, ENAME, SAL,
SUM(SAL) OVER(ORDER BY SAL
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) TOTSAL /* 현재 행부터 마지막 행까지의 합계(누적합)를 구함. */
FROM EMP;| EMPNO | ENAME | SAL | TOTSAL | 비고 |
| 1000 | TEST1 | 800 | 29025 | 현재 행부터 마지막 행까지의 합계 |
| 1011 | TEST12 | 950 | 28225 | |
| 1010 | TEST11 | 1100 | 27275 | |
| 1002 | TEST3 | 1250 | 26175 | |
| 1004 | TEST5 | 1250 | 24925 | |
| 1013 | TEST14 | 1300 | 23675 | |
| 1009 | TEST10 | 1500 | 22375 | |
| 1001 | TEST2 | 1600 | 20875 | |
| 1006 | TEST7 | 2450 | 19275 |
|
| 1005 | TEST6 | 2850 | 16825 |
|
| 1003 | TEST4 | 2975 | 13975 | |
| 1007 | TEST8 | 3000 | 11000 | |
| 1012 | TEST13 | 3000 | 8000 | |
| 1008 | TEST9 | 5000 | 5000 |
순위 함수(RANK Function)
- 윈도우 함수는 특정 항목과 파티션에 대해서 순위를 계산할 수 있는 함수를 제공한다.
순위(RANK) 관련 함수
| 함수 | 설명 |
| RANK | - 특정 항목 및 파티션에 대해서 순위를 계산한다. - 동일한 순위는 동일한 값이 부여된다. |
| DENSE_RANK | 동일한 순위를 하나의 건수로 계산한다. |
| ROW_NUMBER | 동일한 순위에 대해서 고유의 순위를 부여한다. |
사용 예
SELECT EMPNO, ENAME, SAL,
RANK() OVER(ORDER BY SAL DESC) ALL_RANK, /* SAL 로 등수를 계산 (내림차순) */
RANK() OVER(PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK /* JOB으로 파티션을 만들고, JOB별 순위를 조회 */
FROM EMP;| EMPNO | ENAME | SAL | ALL_RANK | JOB_RANK |
| 1008 | TEST9 | 5000 | 1 | 1 |
| 1012 | TEST13 | 3000 | 2 | 1 |
| 1007 | TEST8 | 3000 | 2 | 1 |
| 1003 | TEST4 | 2975 | 4 | 1 |
| 1005 | TEST6 | 2850 | 5 | 2 |
| 1006 | TEST7 | 2450 | 6 | 3 |
| 1001 | TEST2 | 1600 | 7 | 1 |
| 1009 | TEST10 | 1500 | 8 | 2 |
| 1013 | TEST14 | 1300 | 9 | 1 |
| 1002 | TEST3 | 1250 | 10 | 3 |
| 1004 | TEST5 | 1250 | 10 | 3 |
| 1010 | TEST11 | 1100 | 12 | 2 |
| 1011 | TEST12 | 950 | 13 | 3 |
| 1000 | TEST1 | 800 | 14 | 4 |
- RANK 함수는 순위를 계산하며, 동일한 순위에는 같은 순위가 부여된다.
SELECT ENAME, SAL,
RANK() OVER(ORDER BY SAL DESC) ALL_RANK,
DENSE_RANK() OVER(ORDER BY SAL DESC) DENSE_RANK /* 동일한 순위를 하나의 건수로 계산 */
FROM EMP;
| ENAME | SAL | ALL_RANK | DENSE_RANK | 비고 |
| TEST9 | 5000 | 1 | 1 | 2등이 2명이면 3등이 없지만, DENSE_RANK()는 건수로 인식하기 때문에 3등이 있게 된다. |
| TEST13 | 3000 | 2 | 2 | |
| TEST8 | 3000 | 2 | 2 | |
| TEST4 | 2975 | 4 | 3 | |
| TEST6 | 2850 | 5 | 4 | |
| TEST7 | 2450 | 6 | 5 | |
| TEST2 | 1600 | 7 | 6 | |
| TEST10 | 1500 | 8 | 7 | |
| TEST14 | 1300 | 9 | 8 | |
| TEST3 | 1250 | 10 | 9 | |
| TEST5 | 1250 | 10 | 9 | |
| TEST11 | 1100 | 12 | 10 | |
| TEST12 | 950 | 13 | 11 | |
| TEST1 | 800 | 14 | 12 |
- DENSE_RANK 함수는 동일한 순위를 하나의 건수로 인식해서 조회한다.
SELECT ENAME, SAL,
RANK() OVER(ORDER BY SAL DESC) ALL_RANK,
ROW_NUMBER() OVER(ORDER BY SAL DESC) ROW_NUM /* 동일한 순위에 다른 고유한 순위를 부여 */
FROM EMP;| ENAME | SAL | ALL_RANK | ROW_NUM |
| TEST9 | 5000 | 1 | 1 |
| TEST13 | 3000 | 2 | 2 |
| TEST8 | 3000 | 2 | 3 |
| TEST4 | 2975 | 4 | 4 |
| TEST6 | 2850 | 5 | 5 |
| TEST7 | 2450 | 6 | 6 |
| TEST2 | 1600 | 7 | 7 |
| TEST10 | 1500 | 8 | 8 |
| TEST14 | 1300 | 9 | 9 |
| TEST3 | 1250 | 10 | 10 |
| TEST5 | 1250 | 10 | 11 |
| TEST11 | 1100 | 12 | 12 |
| TEST12 | 950 | 13 | 13 |
| TEST1 | 800 | 14 | 14 |
- ROW_NUMBER 함수는 동일한 순위에 대해서 고유한 순위를 부여한다.
집계 함수(AGGREGATE Function)
집계(AGGREGATE) 관련 윈도우 함수
| 함수 | 설명 |
| SUM | 파티션 별로 합계를 계산한다. |
| AVG | 파티션 별로 평균을 계산한다. |
| COUNT | 파티션 별로 행 수를 계산한다. |
| MAX, MIN | 파티션 별로 최댓값과 최솟값을 계산한다. |
사용 예
SELECT ENAME, SAL,
SUM(SAL) OVER(PARTITION BY MGR) SUM_MGR /* 같은 관리자(MGR)에 파티션을 만들고 합계(SUM)를 계산 */
FROM EMP;
| ENAME | SAL | SUM_MGR | 비고 |
| TEST14 | 1300 | 11375 | 같은 관리자의 급여 합계를 보여준다. |
| TEST2 | 1600 | 11375 | |
| TEST3 | 1250 | 11375 | |
| TEST4 | 2975 | 11375 | |
| TEST5 | 1250 | 11375 | |
| TEST13 | 3000 | 11375 | |
| TEST6 | 2850 | 6250 | |
| TEST7 | 2450 | 6250 | |
| TEST12 | 950 | 6250 | |
| TEST10 | 1500 | 2600 | |
| TEST11 | 1100 | 2600 | |
| TEST9 | 5000 | 8000 | |
| TEST8 | 3000 | 8000 | |
| TEST1 | 800 | 800 |
행 순서 관련 함수
- 상위 행의 값을 하위 행에 출력하거나 하위 행의 값을 상위 행에 출력할 수 있다.
- 특정 위치의 행을 출력할 수 있다.
행 순서 관련 윈도우 함수
| 함수 | 설명 |
| FIRST_VALUE | - 파티션에서 가장 처음에 나오는 값을 구한다. - MIN 함수를 사용해서 같은 결과를 구할 수 있다. |
| LAST_VALUE | - 파티션에서 가장 나중에 나오는 값을 구한다. - MAX 함수를 사용해서 같은 결과를 구할 수 있다. |
| LAG | 이전 행을 가지고 온다. |
| LEAD | - 윈도우에서 특정 위치의 행을 가지고 온다. - 기본값 : 1 |
사용 예
SELECT DEPTNO, ENAME, SAL,
FIRST_VALUE(ENAME) OVER(PARTITION BY DEPTNO /* 첫 번째 행을 가지고 옴, 부서 파티션을 만듦. */
ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) AS DEPT_A
FROM EMP;
| DEPTNO | ENAME | SAL | DEPT_A | 비고 |
| 10 | TEST7 | 2450 | TEST7 | 10번 부서 TEST7과 TEST14가 있고, 이 중에서 TEST7의 급여가 많다. |
| 10 | TEST14 | 1300 | TEST7 | |
| 20 | TEST8 | 3000 | TEST8 | |
| 20 | TEST13 | 3000 | TEST8 | |
| 20 | TEST4 | 2975 | TEST8 | |
| 20 | TEST11 | 1100 | TEST8 | |
| 20 | TEST1 | 800 | TEST8 | |
| 30 | TEST9 | 5000 | TEST9 | |
| 30 | TEST6 | 2850 | TEST9 | |
| 30 | TEST2 | 1600 | TEST9 | |
| 30 | TEST10 | 1500 | TEST9 | |
| 30 | TEST3 | 1250 | TEST9 | |
| 30 | TEST5 | 1250 | TEST9 | |
| 30 | TEST12 | 950 | TEST9 |
- FIRST_VALUE 함수는 파티션에서 조회된 행 중에서 첫 번째 행의 값을 가지고 온다.
SELECT DEPTNO, ENAME, SAL,
LAST_VALUE(ENAME) OVER(PARTITION BY DEPTNO /* 마지막 행을 가지고 옴, 부서 파티션을 만듦. */
ORDER BY SAL DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DEPT_A
FROM EMP;| DEPTNO | ENAME | SAL | DEPT_A | 비고 |
| 10 | TEST7 | 2450 | TEST14 | 10번 부서 TEST7과 TEST14가 있고, 이중에서 TEST14의 급여가 적다. |
| 10 | TEST14 | 1300 | TEST14 | |
| 20 | TEST8 | 3000 | TEST1 | |
| 20 | TEST13 | 3000 | TEST1 | |
| 20 | TEST4 | 2975 | TEST1 | |
| 20 | TEST11 | 1100 | TEST1 | |
| 20 | TEST1 | 800 | TEST1 | |
| 30 | TEST9 | 5000 | TEST12 | |
| 30 | TEST6 | 2850 | TEST12 | |
| 30 | TEST2 | 1600 | TEST12 | |
| 30 | TEST10 | 1500 | TEST12 | |
| 30 | TEST3 | 1250 | TEST12 | |
| 30 | TEST5 | 1250 | TEST12 | |
| 30 | TEST12 | 950 | TEST12 |
- LAST_VALUE 함수는 파티션에서 조회된 행 중에서 마지막 행의 값을 가지고 온다.
SELECT DEPTNO, ENAME, SAL,
LAG(SAL) OVER(ORDER BY SAL DESC) AS PRE_SAL
FROM EMP;
| DEPTNO | ENAME | SAL | PRE_SAL |
| 30 | TEST9 | 5000 | - |
| 20 | TEST13 | 3000 | 5000 |
| 20 | TEST8 | 3000 | 3000 |
| 20 | TEST4 | 2975 | 3000 |
| 30 | TEST6 | 2850 | 2975 |
| 10 | TEST7 | 2450 | 2850 |
| 30 | TEST2 | 1600 | 2450 |
| 30 | TEST10 | 1500 | 1600 |
| 10 | TEST14 | 1300 | 1500 |
| 30 | TEST3 | 1250 | 1300 |
| 30 | TEST5 | 1250 | 1250 |
| 20 | TEST11 | 1100 | 1250 |
| 30 | TEST12 | 950 | 1100 |
| 20 | TEST1 | 800 | 950 |
- LAG 함수는 이전의 값을 가지고 온다.
SELECT DEPTNO, ENAME, SAL,
LEAD(SAL, 2) OVER(ORDER BY SAL DESC) AS PRE_SAL
FROM EMP;| DEPTNO | ENAME | SAL | PRE_SAL |
| 30 | TEST9 | 5000 | 3000 |
| 20 | TEST13 | 3000 | 2975 |
| 20 | TEST8 | 3000 | 2850 |
| 20 | TEST4 | 2975 | 2450 |
| 30 | TEST6 | 2850 | 1600 |
| 10 | TEST7 | 2450 | 1500 |
| 30 | TEST2 | 1600 | 1300 |
| 30 | TEST10 | 1500 | 1250 |
| 10 | TEST14 | 1300 | 1250 |
| 30 | TEST3 | 1250 | 1100 |
| 30 | TEST5 | 1250 | 950 |
| 20 | TEST11 | 1100 | 800 |
| 30 | TEST12 | 950 | - |
| 20 | TEST1 | 800 | - |
- LEAD 함수는 지정된 위치의 행을 가지고 온다.
- 기본값은 1이며, 첫 번째 행의 값을 가지고 오는 것이다.
비율 관련 함수
- 누적 백분율, 순서별 백분율, 파티션을 N분으로 분할한 결과 등을 조회할 수 있다.
비율 관련 윈도우 함수
| 함수 | 설명 |
| CUME_DIST | - 파티션 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 조회한다. - 누적 분포상의 위치는 0~1 사이의 값을 가진다. |
| PERCENT_RANK | 파티션에서 제일 먼저 나온 것을 0으로, 제일 늦게 나온 것을 1로 하여 값이 아닌 행의 순서별 백분율을 조회한다. |
| NTILE | 파티션별로 전체 건수를 ARGUMENT 값으로 N 등분한 결과를 조회한다. |
| RATIO_TO_REPORT | 파티션 내에 전체 SUM(칼럼)에 대한 행 별 칼럼값의 백분율을 소수점까지 조회한다. |
사용 예
SELECT DEPTNO, ENAME, SAL,
PERCENT_RANK() OVER(PARTITION BY DEPTNO
ORDER BY SAL DESC) AS PERCENT_SAL /* 부서 내의 등수를 백분율로 구함. */
FROM EMP;| DEPTNO | ENAME | SAL | PERCENT_SAL | 비고 |
| 10 | TEST7 | 2450 | 0 | 같은 부서에서 자신의 급여 퍼센트(등수)를 구한다. |
| 10 | TEST14 | 1300 | 1 | |
| 20 | TEST8 | 3000 | 0 | |
| 20 | TEST13 | 3000 | 0 | |
| 20 | TEST4 | 2975 | .5 | |
| 20 | TEST11 | 1100 | .75 | |
| 20 | TEST1 | 800 | 1 | |
| 30 | TEST9 | 5000 | 0 | |
| 30 | TEST6 | 2850 | .1666666666666666666666666666666666666667 | |
| 30 | TEST2 | 1600 | .3333333333333333333333333333333333333333 | |
| 30 | TEST10 | 1500 | .5 | |
| 30 | TEST3 | 1250 | .6666666666666666666666666666666666666667 | |
| 30 | TEST5 | 1250 | .6666666666666666666666666666666666666667 | |
| 30 | TEST12 | 950 | 1 |
- PERCENT_RANK 함수는 파티션에서 등수의 퍼센트를 구한다.
SELECT DEPTNO, ENAME, SAL,
NTILE(4) OVER(ORDER BY SAL DESC) AS N_TILE /* 4개로 등분하여 분류 */
FROM EMP;| DEPTNO | ENAME | SAL | N_TILE | 비고 |
| 30 | TEST9 | 5000 | 1 | 급여가 높은 순으로 4개로 등분한다. |
| 20 | TEST13 | 3000 | 1 | |
| 20 | TEST8 | 3000 | 1 | |
| 20 | TEST4 | 2975 | 1 | |
| 30 | TEST6 | 2850 | 2 | |
| 10 | TEST7 | 2450 | 2 | |
| 30 | TEST2 | 1600 | 2 | |
| 30 | TEST10 | 1500 | 2 | |
| 10 | TEST14 | 1300 | 3 | |
| 30 | TEST3 | 1250 | 3 | |
| 30 | TEST5 | 1250 | 3 | |
| 20 | TEST11 | 1100 | 4 | |
| 30 | TEST12 | 950 | 4 | |
| 20 | TEST1 | 800 | 4 |
- NTILE(4) 는 4등분으로 분할하라는 의미로, 위의 예에서는 급여가 높은 순으로 1~4 등분으로 분할한다.
⑥ 테이블 파티션(Table Partition)
파티션 기능
- 파티션은 대용량의 테이블을 여러 개의 데이터 파일에 분리해서 저장한다.
- 테이블의 데이터가 물리적으로 분리된 데이터 파일에 저장되면 입력, 수정, 삭제, 조회 성능이 향상된다.
- 파티션은 각각의 파티션 별로 독립적으로 관리될 수 있다.
- 파티션 별로 백업하고 복구가 가능하면 파티션 전용 인덱스 생성도 가능하다.
- 파티션은 Oracle 데이터베이스의 논리적 관리 단위인 테이블 스페이스 간에 이동이 가능하다.
- 데이터를 조회할 때 데이터의 범위를 줄여서 성능을 향상시킨다.
Range Partition
- 테이블의 칼럼 중에서 값의 범위를 기준으로 여러 개의 파티션으로 데이터를 나누어 저장하는 것

List Partition
- 특정 값을 기준으로 분할하는 방법

Hash Partition
- 데이터베이스 관리 시스템이 내부적으로 해시 함수를 사용해서 데이터를 분할한다.
- 결과적으로 데이터베이스 관리 시스템이 알아서 분할하고 관리하는 것이다.

Composite Partition
- 여러 개의 파티션 기법을 조합해서 사용하는 것
파티션 인덱스
- 4가지 유형의 인덱스를 제공한다.
- Oracle 데이터베이스는 Global Non-Prefixed 를 지원하지 않는다.
| 구분 | 주요 내용 |
| Global Index | 여러 개의 파티션에서 하나의 인덱스를 사용한다. |
| Local Index | 해당 파티션 별로 각자의 인덱스를 사용한다. |
| Prefixed Index | 파티션 키와 인덱스 키가 동일한다. |
| Non Prefixed Index | 파티션 키와 인덱스 키가 다르다. |
728x90
'Certificate > SQLD' 카테고리의 다른 글
| [SQLD] 실전 문제 : SQL 기본 ① (1) | 2022.06.25 |
|---|---|
| [SQLD] 실전 문제 : 데이터 모델과 성능 (0) | 2022.06.23 |
| [SQLD] 실전 문제 : 데이터 모델링의 이해 (0) | 2022.06.21 |
| [SQLD] SQL 최적화의 원리 (0) | 2022.01.20 |
| [SQLD] SQL 기본 (0) | 2022.01.18 |
| [SQLD] 데이터 모델과 성능 (0) | 2022.01.17 |
| [SQLD] 데이터 모델링(Data Modeling) (0) | 2022.01.14 |
| [SQLD] SQLD 소개 (0) | 2022.01.13 |

