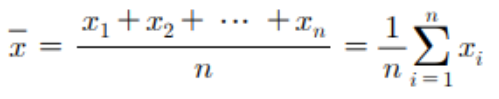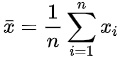- 잘 정의된 연구목적과 이와 연계된 명확한 연구대상 (데이터 전체 집합) - 예) 대통령 후보의 지지율 - 유권자
모수
- 모집단의 특성을 나타내는 수치들 - 모집단의 평균(𝝁), 분산(𝝈²) 같은 수치들을 모수(Parameter)라고 함.
표본
- 모집단의 개체 수가 많아 전부 조사하기 힘들 때 모집단에서 추출(sampling) 한 것 - 추출(Sampling)한 표본으로 모집단의 특성을 추론(inference) 함. (오차 발생) - 예) 각종 여론조사에 참여한 유권자
통계량
- 표본의 특성을 나타내는 수치들 - 표본의 평균(`\bar{x}`), 분산(`s^{2}`) 같은 수치를 통계량(Statistic)이라고 함.
표본 추출
확률적 표본추출법의 종류
종류
설명
단순 무작위 추출 (Simple Random Sampling)
- 모집단의 각 개체가 표본으로 선택될 확률이 동일하게 추출되는 경우 - 모집단의 개체 수 `N`, 표본 수 `n` 일 때 개별 개체가 선택될 확률은 `n/N` 임.
계통 추출 (Systematic Sampling)
- 모집단 개체에 1, 2,…,N 이라는 일련번호를 부여한 후, 첫 번째 표본을 임의로 선택하고 일정 간격으로 다음 표본을 선택함. - 1 ~ 100 번호 부여 후, 10개 선택한다면, [1, 11, 21, 31, ... , 91] 선택
층화 추출 (Stratified Sampling)
- 모집단을 서로 겹치지 않게 몇 개의 집단 또는 층(Strata)으로 나누고, 각 집단 내에서 원하는 크기의 표본을 단순 무작위추출법으로 추출함. - 층 : 성별, 나이대, 지역 등 차이가 존재하는 그룹
군집 추출 (Clustering Sampling)
▪ 모집단을 차이가 없는 여러 개의 집단(Cluster)로 나눔. - (예) 경상대학 내에 경영학과 경제학과 - 이들 집단 중 몇 개를 선택 한 후, 선택된 집단 내에서 필요한 만큼의 표본을 임으로 선택함.
비확률 표본 추출법은 특정 표본이 선정될 확률을 알 수 없어 통계학에서 사용할 수 없음.
척도의 종류
척도
설명
명목 척도 (Nominal Scale)
- 단순히 측정 대상의 특성을 분류하거나 확인하기 위한 목적 - 숫자로 바꾸어도 그 값이 크고 작음을 나타내지 않고 범주를 표시함. - 성별, 혈액형, 출생지 등
서열(순위) 척도 (Ordinal Scale)
- 대소 또는 높고 낮음 등의 순위만 제공할 뿐 양적인 비교는 할 수 없음. - 항목들 간에 서열이나 순위가 존재 - 금,은,동메달, 선호도, 만족도(Likert 척도) 등
등간 척도(구간 척도) (Interval Scale)
- 순위를 부여하되 순위 사이의 간격이 동일하여 양적인 비교가 가능함. - 절대 0점이 존재하지 않음. - 온도계 수치, 물가지수 등
비율 척도 (Ratio Scale)
- 절대 0점이 존재하여 측정값 사이의 비율 계산이 가능한 척도 - 몸무게, 나이, 형제의 수, 직장까지 거리
※ 절대 0점 : '없음'을 의미함. (無) - 온도의 0은 상대 0점으로 없음이 아니라 영상, 영하의 중간 지점을 나타냄.
집중화 경향 측정
집중화 경향(Central Tendency) 측정에 사용되는 값들
값
설명
평균(Mean)
값 들의 무게 중심이 어디인지를 나타내는 값, 산술 평균
중앙값(Median)
자료를 크기 순서대로 배열했을 때, 중앙에 위치하게 되는 값
최빈값(Mode)
어떤 값이 가장 많이 관찰되는지 나타낸 값
평균은 양 꼬리 값의 크기가 변할 때 영향을 크게 받지만, 중앙값은 그러한 변화에 영향을 거의 받지 않음.
데이터의 퍼짐 정도 측정
데이터 집합이 얼마나 퍼져 있는지를 알아보는데 사용하는 값들
값
설명
산포도 (Dispersion)
- 자료의 변량들이 흩어져 있는 정도를 하나의 수로 나타낸 값 - 산포도가 크면 변량들이 평균으로부터 멀리 흩어져 있음, 변동성이 커짐. - 산포도가 작으면 변량들이 평균 주위에 밀집, 변동성이 작아짐. - 범위, 사분위수 범위, 분산, 표준 편차, 절대 편차, 변동 계수
편차 (Deviation)
- 어떤 자료의 변량에서 평균을 뺀 값(편차 = 변량 – 평균) - 편차의 총합은 항상 0 - 편차의 절댓값이 클수록 그 변량은 평균에서 멀리 떨어져 있고, 편차의 절댓값이 작을수록 평균에 가까이 있음.
분산(`s^{2}`) (Variance)
- 편차의 제곱의 합을 `n-1`로 나눈 것 - 데이터 집합이 얼마나 퍼져 있는지 알아볼 수 있는 수치 - 평균이 같아도 분산은 다를 수 있음.
표준편차(`s`) (Standard Deviation)
- 자료의 산포도를 나타내는 수치 - 분산의 양의 제곱근 - 평균으로부터 각 데이터의 관찰 값까지의 평균거리
분산(Variance)의 중요성
평균은 같지만 분산은 다른 두 확률 분포
- 빨간색 분포 : 100의 평균값과 100의 분산 값 - 파란색 분포 : 100의 평균값과 2500의 분산 값 - SD : 표준편차 - 분산이 클수록 '집단의 평균값의 차이'가 무의미해짐. - 집단 내 분산이 작아질수록 평균의 차이가 분명해짐.
분산, 표준편차
분산, 표준편차의 이해
- 특정도시의 10가구를 표본으로 추출해 자녀수를 조사한 결과가 0, 0, 0, 1, 1, 2, 2, 3, 3, 3 일 때, - 표본 평균 : 1.5, 표본 분산 : 1.61, 표본 표준편차 : 1.27이 나옴. - 특정도시의 각 가구는 평균 1.5명의 자녀를 가지고, 각 가구는 약 1.27명의 자녀를 더하거나 뺀 범위 안에 있을 것으로 예상
변동 계수(CV, Coefficient of Variation)
단위가 다른 두 그룹 또는 단위는 같지만 평균차이가 클 때의 산포 비교에 사용함.
- A학생이 평균 3시간 공부하고 표준편차는 0.4이었고, B학생은 평균 6시간 공부하고 표준편차가 0.9 이었다면 어떤 학생이 꾸준하게 공부했을까? - `CV = \frac{S}{\bar{x}}` `A = 0.4/3 = 0.133, B = 0.9/6 = 0.15` 이므로 변동계수가 작은 A가 더 꾸준히 공부함. - 이때, B학생의 표준편차가 0.8 이라면 A, B 학생의 변동계수가 같아짐. 즉 공부시간 평균에 대한 표준편차의 비율이 CV임. - 관측되는 자료가 모두 양수일 때 사용
통계 기본 용어
용어
설명
표본점 (Sample Point)
- 어떤 행위를 했을 때 나올 수 있는 값 - 주사위 굴리는 행위를 했다면 1, 2, 3, 4, 5, 6 중 하나
표본공간 (Sample Space)
- 모든 표본점의 집합 - 주사위 굴리는 행위에 대한 표본공간 `S = {1,2,3,4,5,6}`
사건 (Event)
- 표본점의 특정한 집합 - 주사위를 한 번 굴렸을 때 홀수가 나오는 사건을 A라고 하면 `A = {1, 3, 5}`
확률 (Probability)
- 사건이 일어날 수 있는 가능성을 수로 나타낸 것 - 어떤 사건을 A라고 했을 때, A가 발생할 확률은 `P(A)`와 같이 표기함. - 확률 = 사건 / 표본공간 - 확률 값 : `0 ≤ P(A) ≤ 1`
사건의 종류
사건
설명
독립 사건 (Independent Event)
- `A` 의 발생이 `B` 가 발생할 확률을 바꾸지 않는 사건 - 두 사건 `A, B` 가 독립이면 `P(B|A)=P(B), P(A|B) = P(A), P(A∩B) = P(A)·P(B)` 성립 - 예) 주사위 던져서 나오는 눈의 값과 동전을 던져 나오는 앞/뒤 사건 - 예) 서로 다른 사람이 총을 쏘아 과녁에 명중할 사건
배반 사건 (Exclusive Event)
- 교집합이 공집합인 사건 - 한쪽이 일어나면 다른 쪽이 일어나지 않을 때의 두 사건 - `P(A∩B) = 0, P(AUB) = P(A) + P(B)` - 예) 동전 하나를 던져 앞면 나오는 사건, 뒷면 나오는 사건
종속 사건 (Dependent Event)
- 두 사건 `A` 와 `B` 에서 한 사건의 결과가 다른 사건에 영향을 주는 사건 - 예) 음주와 사고 사건 - `P(A∩B) = P(A|B) · P(B)`
조건부 확률(Conditional Probability)
사건 `B` 가 발생했다는 조건 아래서 사건 `A` 가 발생할 조건부 확률
`P(A|B) = P(A∩B) / P(B)`, 단 `P(B) > 0`
두 사건 `A, B` 가 독립 사건인 경우 : `P(B|A) = P(B), P(A|B) = P(A), P(A∩B) = P(A)P(B)`
확률 계산 문제
Q. 동전 3개를 동시에 던져서 앞면이 한번 나올 확률은?
전체 경우의 수 8개에서 앞면이 한 번 나오는 경우는 ‘앞뒤뒤, 뒤앞뒤, 뒤뒤앞’ 이므로 `3/8` 이 정답이다.
Q. 햄버거집에서는 고객들의 취향을 조사한 결과 75%는 겨자를 사용하고, 80%는 케찹을 사용하며, 65%는 이들 두 가지를 사용한다는 사실을 발견했다. 겨자 사용자가 케찹을 사용할 확률은? (사건A : 고객은 겨자를 사용한다, 사건B : 고객은 케찹을 사용한다)
`P(B|A) = {P(B∩A)} / {P(A)} =` (둘 다 사용하는 사용자) / (겨자 사용자) `= 0.65 / 0.75 = 0.87`
Q. `P(A)=0.3, P(B)=0.4` 이며 서로 독립일 때 `P(B|A)` ?
`A, B` 가 독립사건일 때, `P(B|A) = P(B)` 이다, 따라서 `0.4` 이 정답이다.
확률 분포(Probability Distribution)
용어
설명
분포 (Distribution)
일정한 범위 안에 흩어져 퍼져 있는 정도
확률 변수 (Probability Variance)
- Random Variable - 확률 현상에 기인해 결과값이 확률적으로 정해지는 변수 - 확률 현상 : 어떤 결과들이 나올지 알지만, 가능한 결과들 중 어떤 결과가 나올지 모르는 현상
확률 분포 (Probability Distribution)
어떤 확률 변수가 취할 수 있는 모든 값들과 그 값을 취할 확률의 대응 관계로 표시하는 것
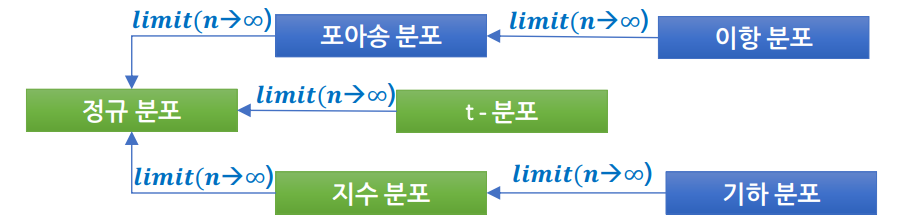
이산형 확률 분포 (Discrete Probability Distribution)
- Discrete(별개의) - 확률 변수가 몇 개의 한정된 가능한 값을 가지는 분포 - 각 사건은 서로 독립이어야 함. - 예) 이항 분포, 베르누이 분포, 기하 분포, 포아송 분포 등
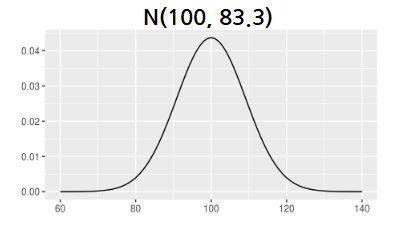
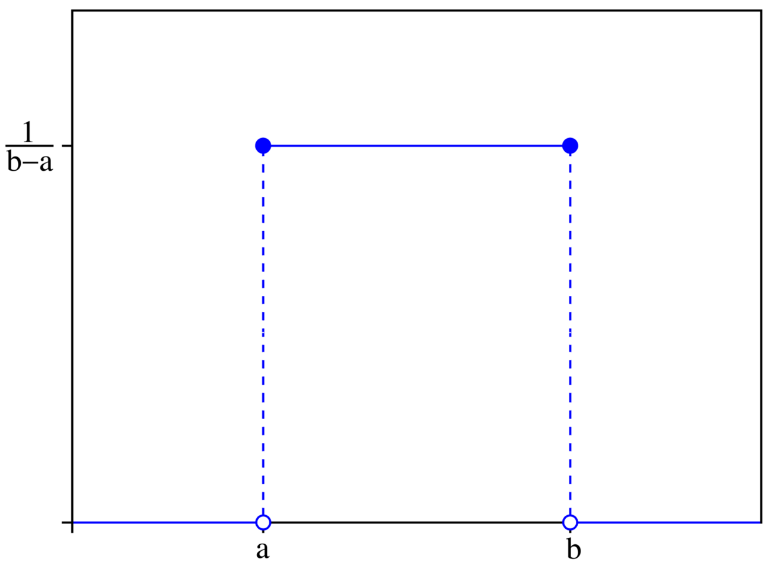
연속형 확률 분포 (Continuous Probability Distribution)
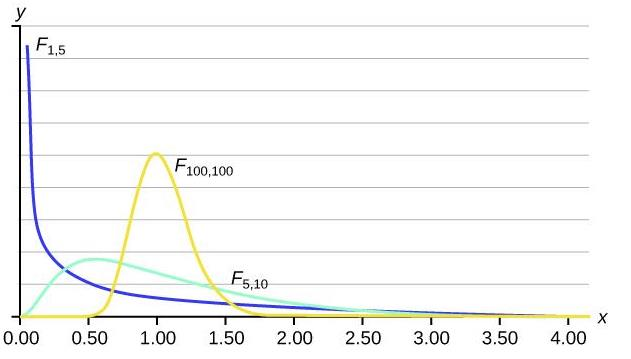
- Continuous - 확률 변수의 가능한 값이 무한 개이며 사실상 셀 수 없을 때 - 예) 정규 분포, 지수 분포, 연속 균일 분포, 카이 제곱 분포, F 분포 등
확률변수와 확률분포의 예
확률변수 : 동전을 2개 던질 때 앞면이 나온 횟수
확률 분포 (이산형 확률 분포)
앞면 횟수
0
1
2
합
확률
`1/4`
`1/2`
`1/4`
`1`
이산형 확률 분포
① 베르누이 분포
실험 결과 두 가지 중의 하나로 나오는 시행의 결과를 `0` 또는 `1` 값으로 대응시키는 확률변수 `X` 에 대해 아래 식을 만족하는 확률변수 `X`가 따르는 확률분포
모수가 하나이며 서로 반복되는 사건이 일어나는 실험의 반복적 실행을 확률 분포로 나타낸 것
A 야구선수의 홈런 칠 확률이 5% 일 때, 이 선수가 `x` 번째 타석에서 홈런 칠 확률 분포?
x
1
2
3
4
5
6
...
확률
0.0500
0.0475
0.0451
0.0428
0.0407
0.0387
...
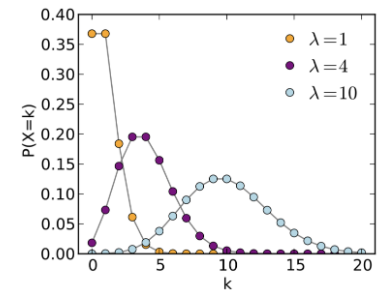
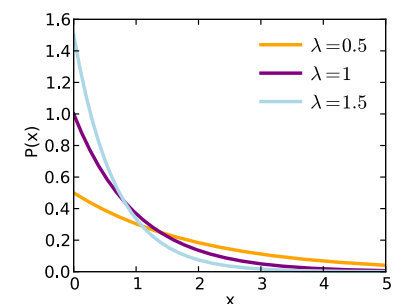
④ 포아송 분포(Poisson Distribution)
단위 시간이나 단위 공간에서 어떤 사건이 몇 번 발생할 것인지를 표현하는 분포
특정 기간 동안 사건(Events) 발생의 확률을 구할 때 쓰임.
`X~Pois(np)`
`λ` : 정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기댓값, `P(X = x) = \frac{e^{-λ}λ^{x}}{x!}`
포아송 분포의 예
- 어느 AS센터에 1시간당 평균 120건의 전화가 온다. 이때 1분 동안 걸려오는 전화 요청이 4건 이하일 확률은? - 어느 가게에 1시간당 평균 8명의 손님이 온다. 이때, 1시간 동안 손님이 10명 올 확률은? - 확률은 `x = λ`에서 최대이며, `x`가 커질수록 0에 접근함.
- 추정량의 분산이 될 수 있는 대로 작아야 함. (최소 분산 추정량) - MSE(Mean Square Error)가 작아야 함.
통계적 추정
점 추정(Point Estimation)
통계량 하나를 구하고 그것을 가지고 모수를 추정하는 방법
‘모수가 특정한 값일 것’이라고 추정하는 것
예) A과목 수강 전체 학생 중 50명을 뽑아 조사한 결과 기말 점수가 80점 이었다면, 50명 뿐 아니라 나머지 A과목을 수강한 학생들의 점수도 80점 정도로 추정하는 것
점 추정량 구하는 방법
적률법 : 표본의 기댓값을 통해 모수를 추정하는 방법
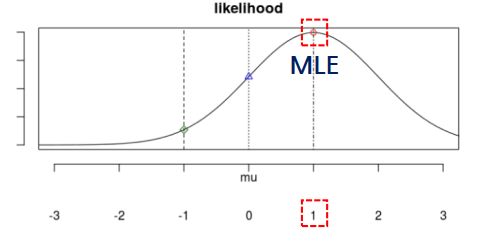
최대 가능도 추정법(최대우도법) : 함수를 미분해서 기울기가 0인 위치에 존재하는 MLE(Maximum Likelihood Estimator)를 찾는 방법
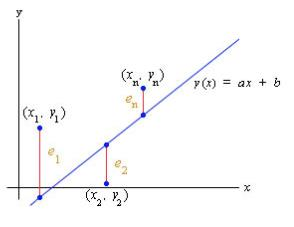
최소 제곱법 : 함수값과 측정값의 차이인 오차를 제곱한 합이 최소가 되는 함수를 구하는 방법
구간 추정(Interval Estimation)
점추정의 정확성을 보완하는 방법
통계량을 제시하는 것은 같지만 신뢰구간을 만들어서 추정하는 것
신뢰 구간
모수가 포함되리라고 기대되는 '범위'
신뢰 수준
모수값이 정해져 있을 때, 다수 신뢰 구간 중 모수값을 포함하는 신뢰 구간이 존재할 확률
신뢰수준 95% 의미 : n번 반복 추출하여 산정하는 신뢰 구간들 중에서 평균적으로 95%는 모수 값을 포함하고 있을 것이라는 의미
예)
신뢰수준 95%에서 투표자의 35%~45%가 A후보를 지지하고 있다.
95%는 신뢰 수준, 35%~45%는 신뢰 구간이다.
정치인 지지율 조사에서 A후보는 40%, B후보는 25%의 지지율을 얻었다. 신뢰 수준 95%에서 표본 오차는 3.1%포인트이다.
동일한 형태의 여론조사를 100번 실시했을 경우에 95번은 A후보가 40%에서 ±3.1% 인 36.9% ~ 43.1%, B후보는 25%에서 ±3.1% 인 21.9% ~ 28.1% 사이의 지지율을 얻을 것으로 기대된다.
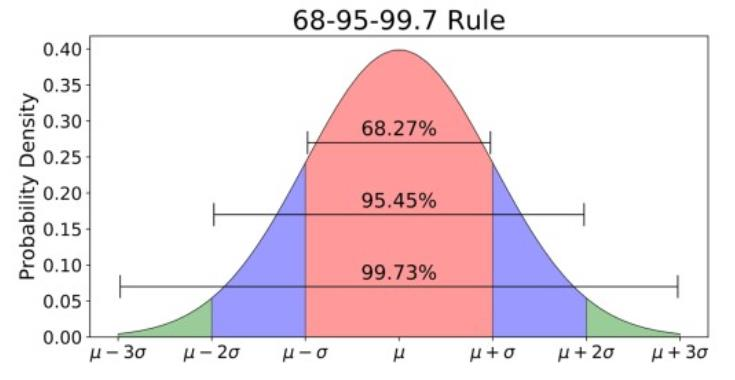
신뢰 구간
99% 신뢰 수준에 대한 신뢰 구간이 95% 신뢰 수준에 대한 신뢰 구간보다 긺.
표본의 크기가 커지면 신뢰 구간의 길이는 줄어듦.
신뢰 구간의 길이
신뢰도 95% 신뢰 구간의 길이
`l = 2 \times 1.96 \times \frac{σ}{\sqrt{n}}`
`1.96 \times \frac{σ}{\sqrt{n}}` : 표본 오차
신뢰도 99% 신뢰 구간의 길이
`l = 2 \times 2.58 \times \frac{σ}{\sqrt{n}}`
`2.58 \times \frac{σ}{\sqrt{n}}` : 표본 오차
표본의 크기 `n` 이 클 경우 `σ` 대신 `s` 사용 가능
가설 검정(Statistical Hypothesis Testing)
모집단에 대한 어떤 가설을 설정한 뒤에 표본 관찰을 통해 그 가설의 채택 여부를 결정하는 통계적 추론 방법
귀무 가설(`H_{0}`) (Null Hypothesis)
가설 검정의 대상이 되는 가설
연구자가 부정하고자 하는 가설
설정한 가설이 진실할 확률이 극히 적어 처음부터 버릴 것(기각)이 예상되는 가설
대립 가설(`H_{1}`) (Anti Hypothesis)
귀무 가설이 기각될 때 받아들여지는 가설
연구자가 연구를 통해 입증 또는 증명되기를 기대하는 예상이나 주장
예1) 범죄 사건에서 용의자가 있을 때 형사의 가설 - 귀무 가설 : 용의자는 무죄이다. - 대립 가설 : 용의자가 범죄를 저질렀다.
예2) 성적 관련 선생님의 가설 - 귀무 가설 : 남학생과 여학생의 평균은 같다. - 대립 가설 : 남학생과 여학생의 평균은 다르다
기각역(Critical Region)
검정 통계량(t-value)의 분포에서 유의 수준의 크기에 해당하는 영역
계산한 검정 통계량의 유의성(귀무 가설의 기각)을 판정하는 기준
제 1종 오류(α Error)
귀무 가설이 참인데 기각하게 되는 오류
제 2종 오류(β Error)
귀무 가설이거짓인데 채택하게 되는 오류
두 가지 오류가 작을수록 바람직함.
두 가지를 동시에 줄일 수 없기 때문에 제 1종 오류를 범할 확률의 최대 허용치를 미리 어떤 특정값(유의 수준)으로 지정해 놓고 제 2종 오류의 확률을 가장 작게 해주는 검정 방법을 사용함.
유의 수준(α) (Significance Level)
제 1종 오류의 최대 허용 한계
유의 수준 0.05(5%) : 100번 실험에서 1종 오류 범하는 최대 허용 한계가 5번
유의 확률(=p-Value) (Probability Value)
0 ≤ p-value ≤ 1
1종 오류를 범할 확률
귀무 가설을 지지하는 정도
귀무 가설이 사실일 때, 기각하는 1종 오류 시 우리가 내린 판정이 잘못되었을 확률
검정 통계량들은 거의 대부분이 귀무 가설을 가정하고 얻게 되는 값
검정 통계량에 관한 확률로, 극단적인 표본 값이 나올 확률
p-value가 작을 수록 그 정도가 약하다고 보며, p-value < α 귀무 가설을 기각, 대립 가설을 채택함.
p-value가 0.05(5%) : 귀무 가설을 기각했을 때 기각 결정이 잘못될 확률이 5%임.
귀무 가설을 이용한 가설 검증 프로세스
모수적, 비모수적 추론(Inference)
모수적 추론
모집단에 특정 분포를 가정하고 분포의 특성을 결정하는 모수에 대해 추론하는 방법
모수로는 평균, 분산 등을 사용
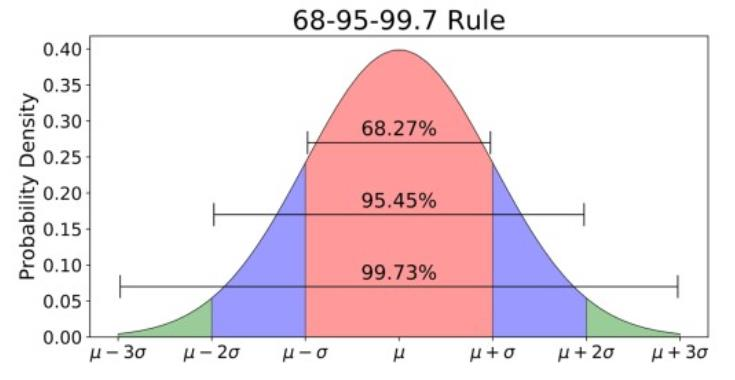
자료가 정규분포, 등간척도, 비율척도 인 경우 (온도, 물가지수, 몸무게, 자녀수 …)
모수적 검정
검정하고자 하는 모집단의 분포에 대해 가정을 하고, 그 가정하에서 검정 통계량과 검정 통계량의 분포를 유도해 검정을 실시함.
1) 가정된 분포의 모수에 대해 가설 설정 2) 관측된 자료를 이용해 구한 표본 평균, 표본 분산 등을 이용해 검정 실시
모수적 통계의 전제 조건
표본의 모집단이정규 분포를 이루어야 하며, 집단 내의분산은 같아야 함.
변인(=변수)은등간척도나 비율척도로 측정되어야 함. (아니면비모수 통계사용)
모수 검정 방법
T-Test
Paired T Test
ANOVA Test
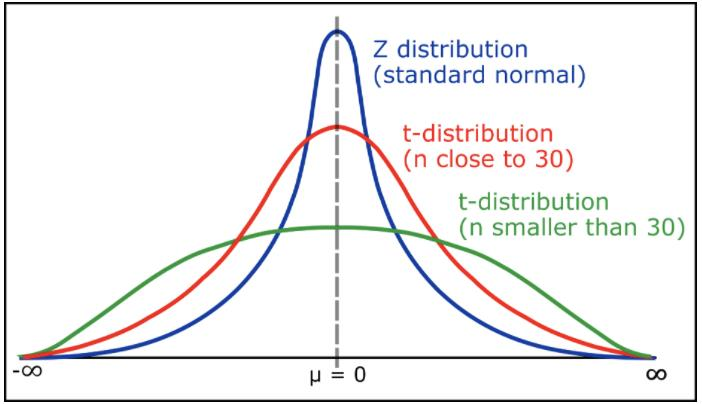
z분포, t분포, F분포, 카이스퀘어 분포
모수 검정 방법 사용 예
모평균과 표본 평균과의 차이 : z 분포, t 분포
표본 평균 간의 차이: z 분포, t 분포
모분산과 표본 분산과의 차이: F 분포, 카이제곱(=카이스퀘어)분포
표본 분산 간의 차이: F 분포, 카이제곱분포
T-검정(T-Test)
평균값이 올바른지, 두 집단의 평균 차이가 있는지를 검증하는 방법으로 t값을 사용함.
t값이 커질수록 p-value는 작아지며, 집단간 유의한 차이를 보일 가능성이 높아짐.
T-검정 방법
설명
One Sample T-Test
- 단일 표본의 평균 검정을 위한 방법 - 예) S사 USB의 평균 수명은 20000 시간이다
Paired T-Test (대응표본 T-검정)
- 동일 개체에 어떤 처리를 하기 전, 후의 자료를 얻을 때 차이 값에 대한 평균 검정을 위한 방법 - 예) 매일 1시간 한달 걸으면 2Kg이 빠진다. (걷기 수행 전/수행 후) - 가능한 동일한 특성을 갖는 두 개체에 서로 다른 처리를 하여 그 처리의 효과를 비교하는 방법(Matching) - 예) X질병 환자들을 두 집단으로 나누어 A, B 약을 투약해 약의 효과 비교
Two Sample T-Test (독립표본 T-검정)
- 서로 다른 두 그룹의 평균을 비교하여 두 표본의 차이가 있는지 검정하는 방법 - 귀무 가설 - 두 집단의 평균 차이 값이 0이다 - 예) 2학년과 3학년의 결석률은 같다
자유도(Degree of Freedom)
통계적 추정에서 표본자료 중 모집단에 대한 정보를 주는 독립적인 자료의 수
`n` 개 데이터를 이용해 어떤 통계량 `A` 를 계산하고자 할 때 필요한 다른 통계량 `B` 가 있다면, `B` 는 `A` 를 계산하기 전에 고정된 값을 가져야 하고 이것이 자유도에서 제외됨.
다른 통계량을 한 개 사용한 크기가 `n` 인 표본의 자유도 : `n - 1`, 관측값(`x_{1}, x_{2}, ..., x_{n}`)
표본 평균의 자유도 : `n`
표본 분산에서 자유도 : `n - 1`
- `\bar{x}` : 산술 평균은 통계량! 하나의 자료값이 이미 정해져 있는 것과 같은 효과를 가져옴.
- 𝟏 𝟑 𝟓 𝟕 𝟗 데이터는 합계가 25이고, 평균이 5이다. - 이때, 숫자 하나를 모르더라도 평균을 알면 그 숫자를 찾아낼 수 있다. - 즉, 표본 평균 값을 알 고 있으면 전체 자료 중 자유롭게 값을 취할 수 있는 관찰치의 개수는 4개이다. `df = n - 1`
One Sample Test
예 : 임금의 평균이 100이다.
df = 2999 : n = df + 1, 데이터의 수 3000개
유의수준 5%에서 평균 wage=100 이라는 귀무 가설은 기각됨
95% 신뢰구간 : 110.2098 ~ 113.1974
귀무 가설에서 설정한 평균이 신뢰 구간내에 존재하지 않음.
Paired T-Test (대응 표본 T-검정)
예 : 수면 유도제 데이터를 통한 '두 집단의 평균이 같다'는 가설에 대한 Paired T-Test
paired=TRUE : Paired T-Test, 짝을 이루는 데이터인 경우 분석 전 등분산성 검정 필요 없음.
df = 9 : 그룹별 데이터의 수 10개 → 분석 전 정규성 검정 실시
p-value 가 0.002833 으로 두 집단의 평균이 같다는 귀무 가설을 기각할 수 있음.
신뢰 구간에 0이 포함되지 않음.
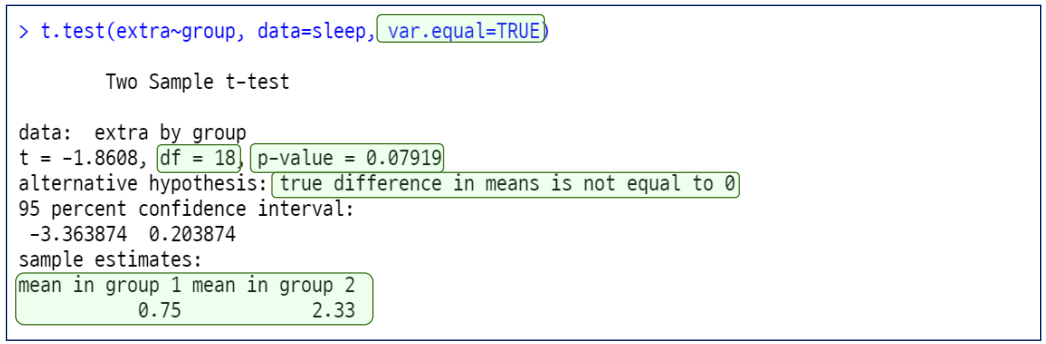
Two Sample T-Test (독립 표본 T-검정)
예 : 수면 유도제 데이터를 통한 '집단 간 평균이 같다'는 가설에 대한 T-Test
var.equal=TRUE : 두 집단의 모분산이 같다는 등분산성 만족 → 분석 전 등분산성 검정 실시
df = 18: 그룹이 2개이므로 데이터의 수 20개 → 분석 전 정규성 검정 실시
p-value 가 0.07919 로 두 집단의 평균이 같다는 귀무가설을 기각할 수 없음.
신뢰 구간에 0이 포함되므로 두 집단 간 평균에 차이가 없다고 해석할 수 있음.
데이터의 정규성 검정
종류
설명
Q-Q Plot
- 그래프를 그려서 정규성 가정이 만족되는지 시각적으로 확인하는 방법 - 대각선 참조선을 따라 값들이 분포하게 되면 정규성을 만족한다고 할 수 있음.
Histogram
구간별 돗수를 그래프로 표시하여 시각적으로 정규 분포를 확인하는 방법
Shapiro-Wilk Test
- 오차항이 정규분포를 따르는지 알아보는 검정 - 귀무 가설은 정규 분포를 따른다로 p-value가 0.05보다 크면 정규성을 가정하게 됨. - 회귀 분석에서 모든 독립변수에 대해 종속변수가 정규분포를 따르는지 알아보는 방법
Kolmogorov-Smirnov Test (K-S Test)
- 두 모집단의 분포가 같은 지 검정하는 것 - p-value가 0.05보다 크면 정규성을 가정하게 됨.
비모수적 추론
모집단에 대해 특정 분포 가정을 하지 않음.
모수 자체보다분포 형태에 관한 검정을 실시함.
표본 수가 적고, 명목척도, 서열척도인 경우 (성별, 혈액형, 만족도, 메달)
비모수적 검정
모집단의 분포에 대해 제약을 가하지 않고 검정을 실시하는 검정 방법
모수 자체보다 분포 형태에 관한 검정을 실시함.
가설을 “분포의 형태가 동일하다”, “분포의 형태가 동일하지 않다”와 같이 분포 형태에 대해 설정함.
관측 값들의 순위나 두 관측 값 사이의 부호 등을 이용해 검정
모집단의 특성을 몇 개의 모수로 결정하기 어려우며 수 많은 모수가 필요할 수 있음.
모수적 방법보다 훨씬 단순함.
민감성을 잃을 수 있음.
비모수적 검정의 종류
명목 척도 기준
카이스퀘어 검정(Chi-square Test)
McNemar Test
Cochran Test
서열 척도 기준
Kolmogorov-Smirnov Test
Sign Test
Wilcoxon Signed Rank Test
Friedman Test
Mann-Whitney U Test
Kruskal-Wallis H Test
모수/비모수적 추론 방법
비교 대상 집단수
관계
비모수 - 명목 척도
비모수 - 서열 척도
모수
1
카이스퀘어 검정
Kolmogorov-Smirnov Test
One Sample T Test
2
독립
Crosstab
Mann-Whitney U Test
Two Sample T Test
대응 자료
McNemar Test
Wilcoxon Signed-Rank Test Sign Test
Paired T Test
k (다변량)
독립
Kruskal-Wallis H Test
ANOVA Test (분산 분석)
대응 자료
Cochran Test
Friedman Test
카이스퀘어 검정
한 개 범주형 변수와 각 그룹 별 비율과 특정 상수비가 같은지 검정하는 적합도 검정
각 집단이 서로 유사한 성향을 갖는지 분석하는 동질성 검정
두 개 범주형 변수가 서로 독립인지 검정하는 독립성 검정
카이스퀘어 검정 가설 예
- 적합도 검정 (한 개 범주형 변수, 알려진 사실) : 교배 실험으로 얻은 완두콩 비율이 멘델의 법칙 9:3:3:1을 따르는 지 검정으로, 기존에 알려진 기준이 존재 - 동질성 검정 (부모집단, 범주형 변수) : 부모집단(Subpopulation)에 대해 열 변수의 분포가 동질한지 검정, 성별에 따라 음료 선호가 동질한지에 대한 검정 - 독립성 검정 (두 개 범주형 변수) : 도로형태(국도, 특별광역시도, 고속도로)와 교통사고 피해정도(사망, 중상, 경상)의 관련성 검정
부호 검정(Sign Test)
표본들이 서로 관련되어 있는 경우, 짝지어진 두 개의 관찰치들의 크고 작음을 +와 –로 표시하여 그 개수를 가지고 두 그룹의 분포 차이가 있는가에 대한 가설을 검증하는 방법
부호 검정 가설 예
- 귀무 가설 : 두 생산 라인의 일별 생산량 중 불량품 수의 분포는 동일하다. - 대립 가설 : 두 생산 라인의 일별 생산량 중 불량품 수의 분포는 동일하지 않다.
R의 기초 통계 연산
기초 통계
함수
비고
평균
중심값
mean(x)
분산
var(x)
중앙값
median(x)
평균보다 이상치에 덜 민감
합
sum(x)
변동 계수(CV)
흩어짐 정도
표준편차/평균
- 측정단위가 서로 다른 데이터 비교시 사용 - 변동 계수 크다 == 편차가 크다
IQR
IQR(x)
3사분위수 - 1사분위수
범위
range(x)
최소, 최댓값 출력
왜도
skewness(x)
첨도
kurtosis(x)
사분위수
중심 위치
quantile(x)
자연로그 값
log(x)
공분산
cov(x, y)
상관 계수
cor(x, y)
※ na.rm=T 옵션은 mean, range, sd등수치형 자료에 NA 값이 있으면 반드시사용해야 함.