728x90
데이터 분석 : R 기초와 데이터 마트
R 설치
- 주의 사항
- 컴퓨터의 이름을 한글로 하지 않고 영어로 지정
- 사용자 이름도 한글로 하지 않고 영어로 지정
- 폴더 이름도 한글로 하지 않고 영어로 지정 (특수문자, 공백도 사용하지 않음.)
- R Project 홈페이지에서 R 프로그램 다운로드
- R Studio 설치
R: The R Project for Statistical Computing
www.r-project.org
RStudio | Open source & professional software for data science teams
RStudio provides open source and enterprise-ready professional software for data science.
www.rstudio.com
- '관리자 권한'으로 실행
- 메뉴에서 [Tools] - [Global Options] 를 선택하면 다양한 옵션 변경이 가능함.
프로젝트에 파일 추가
- 메뉴에서 [File] - [New File] - [R Script] 를 선택하거나 단축키 [Ctrl] + [Shift] + [N] 을 사용함.
R의 특징
- 오픈 소스, 다양한 운영체제에서 사용할 수 있음.
- 우수한 데이터 핸들링 : 텍스트, CSV, 엑셀, SAS, SPSS, DB 등 지원
- 인터프리터
- 우수한 그래픽 기능 : 2D, 3D, 동적 그래프 지원
- 다양한 형태의 데이터 구조를 지원하므로 분석 대응력이 좋음.
- 열 우선 배열
- Index 번호는 1부터 시작
- 1:5 는 1부터 5까지의 수를 의미함.
R의 명령 실행
- 대화형 모드 (Console)
- 실시간으로 입력하고 결과 확인
- 실행 : [Enter]
- 배치 모드 (File)
- 작업 내용을 파일로 작성, 실행
- 다양한 실행 방법이 존재함.
- 실행
- 실행 내용 선택 또는 커서 위치
- [Ctrl]+[R], [Ctrl]+[Enter], 아이콘 / Code 메뉴 사용
- 주석
- # 기호 뒤로 주석 내용
- 도움말
- ?함수명 또는 help(함수명)
R의 연산자 우선 순위
| 연산자 우선순위 | 의미 | 예 |
| ^, ** | 지수 | 2^4 |
| +, - | 양수, 음수 부호 | +4, -2 |
| : | 수열 생성 | 1:5 |
| %any% | 특수 연산자 | %/% : 몫, %% : 나머지, %*% : 행렬곱 |
| *, / | 곱셈, 나눗셈 | 2*4, 10/3 |
| +, - | 덧셈, 뺄셈 | 4+2, 5-2 |
| == | 같음 비교 | 3 == 5 # FALSE |
| != | 다름 비교 | 3 != 5 # TRUE |
| >=, <=, <, > | 이상, 이하, 작다, 크다 | 3>=5, 3<=5 # FALSE, TRUE |
| ! | 논리 부정 | !(3==5) |
| &, && | 논리 AND | - & : 논리 연산 데이터가 하나 이상인 경우 사용 - && : 논리 연산 데이터가 하나인 경우 사용 |
| |, || | 논리 OR | 논리 AND과 같은 규칙 |
| ~ | 식(formula) | 종속변수1+종속변수2 … ~ 독립변수1 + 독립변수2 … |
| ->, ->> | 왼쪽 값을 오른쪽으로 대입 | 3 -> a, 3->> a |
| = | 오른쪽 값을 왼쪽으로 대입 | a = 3 |
| <-, <<- | a <- 3, a <<- 3 |
R의 산술 연산자
| 연산자 | 설명 |
| + | 덧셈 |
| - | 뺄셈 |
| * | 곱셈 |
| / | 나눗셈 |
| %/% | 몫 |
| %% | 나머지 |
| ^, ** | 승수 |
| sqrt() | 제곱근 |
R의 논리 연산자
| 연산자 | 설명 |
| > | 크다 |
| < | 작다 |
| >= | 이상 |
| <= | 이하 |
| == | 같다 |
| != | 다르다 |
| & | AND |
| | | OR |
| ! | NOT |
R의 데이터 형(타입)
- R의 데이터 형은 기본형, 구조형, 복합형으로 나눌 수 있으며, Special Values 가 존재함.

기본형
| 자료형 | 설명 |
| numeric | 정수, 실수, 복소수, 수학적 연산 및 통계적 계산 |
| character | 문자, 단어로 구성, “ ” 또는 ‘ ’ 내에 표현됨 |
| logical | logical TRUE, FALSE, 산술 연산 시 1, 0으로 사용됨 |
구조형, 복합형
| 자료형 | 차원 | 원소 | 원소의 타입 |
| scalar | 단일 | 수치 / 문자 / 논리 | 단일 |
| factor | 1D | 수치 / 문자 | 단일, 범주형 |
| vector | 1D | 수치 / 문자 / 논리 | 단일 |
| matrix | 2D | 단일 | |
| data.frame | 2D | 복합 가능 | |
| array | 2D 이상 | 단일 | |
| list | 2D 이상 | 복합 가능 |
Special Values
| 자료형 | 설명 |
| NULL | 변수 값이 초기화 되지 않음. |
| NA | Not Available, 데이터 값 없음. (결측치) |
| NaN | Not Available Number, 계산 불가능 |
| INF | Infinite, 무한대 |
변수 정의 및 사용
- 반복되어 사용되는 값 또는 변하는 값에 대해 이름(변수)을 부여하여 사용함.
- rm(list=ls()) : 모든 변수 삭제
- rm(변수명) : 특정 변수명 삭제
- ls() : 사용 중인 변수 목록 확인
- 변수에 값 지정 방법
- 변수명 <- 값
- 변수명 = 값
- cat() : 괄호 속 내용을 하나로 연결해 화면에 출력
- ‘\n’ : 줄바꿈
- print() : 괄호 속 한 개 값을 화면에 출력 후 줄바꿈
> rm(list=ls()) # 모든 변수 삭제
> ls() # 사용 중인 변수 목록 확인
character(0)
> a <- 10 # 변수에 값 지정 (1) : 변수명
> b = 20 # 변수에 값 지정 (2) : 변수명 = 값
> hap <- a + b
> cat(hap, "\n") # 괄호 속 내용을 하나로 연결해 화면에 출력, "\n" : 줄바꿈
30
> ls()
[1] "a" "b" "hap"
> rm(hap) # 특정 변수명 삭제
> ls()
[1] "a" "b"
변수 이름 규칙
- R의 변수이름(객체이름)은 알파벳, 숫자, _ , . 가능
- _, . 이외의 특수 문자 사용 못함.
- 첫 글자는 숫자일 수 없음.
R의 데이터 구조 : vector
vector(벡터)
- 하나 이상의 스칼라(=길이가 1인 벡터) 원소들을 갖는 단순한 형태의 집합
- 숫자, 문자, 논리형 데이터를 원소(Element)로 사용할 수 있음.
- 동일한 자료형을 갖는 값들의 집합으로 하나의 열(Column)로 구성됨.
- 서로 다른 타입을 연결할 경우, 문자열 취급되어 연결됨.
- 벡터 생성 함수
- c(value1, value2, …)
- seq(from, to, by)
- rep(x, times, each)
① c 함수로 생성
- c(value1, value2, …)

② seq 함수로 생성
- seq(from=1, to=1, by, length)
- from 부터 to 까지 by 씩 건너띄는 수로 구성된 벡터 생성
- length를 사용하는 경우 from 부터 to 까지의 수 중 length 개 만큼의 수를 원소로 하며, 원소들 간 균등 간격을 갖음.
> rm(list=ls())
> v1 = seq(1, 5)
> v2 = seq(1, 10, 2)
> v3 = seq(1, 10, length=4)
> v4 = seq(1, 3, length=5)
③ rep 함수로 생성
- rep(x, time, each)
- x : 스칼라 또는 벡터 등을 사용할 수 있음.
- time : x가 벡터일 경우 처음부터 끝 까지를 time에 지정된 수 만큼 반복
- each : x가 벡터일 경우 각 원소를 each에 지정된 수 만큼 반복
> rm(list=ls())
> v1 = rep(1, 5)
> v2 = rep(1, time=5)
> v3 = rep(3:5, time=3)
> v4 = rep(3:5, each=2)
> v5 = rep(seq(1, 5, 2), 2)
vector의 연산
vector의 연산
| 연산자 | 설명 |
| + | 덧셈 |
| - | 뺄셈 |
| * | 곱셈 |
| / | 나눗셈 |
| %/% | 몫 |
| %% | 나머지 |
| ^, ** | 승수 |
| t(x) | 전치행렬 |
| 행%*%열 | 행렬곱 |
> rm(list=ls())
> v1 <- seq(2, 10, 2)
> v2 <- rep(2, 5)
> v3 <- v1 + v2
> v4 <- v1 %/% v2
> v5 <- v1 ** v2
> x <- c(1, 4, 8)
> y <- c(2, 3)
> z = t(y)
> m = x %*% z
vector의 길이가 동일하지 않은 경우
- 원소의 개수가 적은 쪽의 벡터를 원소가 많은 쪽의 벡터와 동일하게 원소의 개수를 맞춤. (배수 관계)
> rm(list=ls())
> v1 <- rep(3, 6)
> v2 <- c(1, 2, 3)
> v3 <- v1 + v2
> v4 <- v2 + 3
| v3 <- v1 + v2 | ||||
| 3 | + | 1 | = | 4 |
| 3 | + | 2 | = | 5 |
| 3 | + | 3 | = | 6 |
| 3 | + | 1 | = | 4 |
| 3 | + | 2 | = | 5 |
| 3 | + | 3 | = | 6 |
| v4 <- v2 + 3 | ||||
| 1 | + | 3 | = | 4 |
| 2 | + | 3 | = | 5 |
| 3 | + | 3 | = | 6 |
vector의 인덱싱
- 대괄호를 사용하며, 위치 index를 사용하거나 조건문, 순열 등을 사용할 수 있음.
| 방법 | 설명 |
| v[n] | vector 의 n 번째 원소 반환, n=1부터 시작 |
| v[-n] | vector 에서 n 번째 원소를 제외한 나머지 원소들 반환 |
| v[조건] | 조건을 만족하는 원소들 반환, 조건의 결과는 TRUE/FALSE 로 구성 |
| v[start:end] | start 번째 원소부터 end 번째 원소까지 반환 |
> rm(list=ls())
> v1 <- c(1:5)
> r1 = v1[3]
> r2 = v1[-3]
> r3 = v1[2:4]
> r4 = v1[v1%%2 == 0]
> names(v1) <- c('A', 'B', 'C', 'D', 'E') # 각 원소에 이름 지정
> r5 = v1['B'] # 이름으로 인덱싱 가능
R의 데이터 구조 : matrix
matrix(행렬)
- 데이터의 형태가 2차원으로 행(row)과 열(column)로 구성
- 하나의 데이터 유형만 가능
- 역행렬은 solve()로 구함.
행렬 생성 함수
- matrix(data=NA, nrow=1, ncol=1, byrow=FALSE, dimnames=NULL)
- byrow=FALSE : 값의 입력 방향이 '열'이며, TRUE로 지정 시 '행' 방향으로 변경됨.
- dimnames=NULL : 각 차원의 이름
- rbind(vectors or matrices)
- cbind(vectors or matrices)

matrix 관련 함수(인덱싱)
- matrix는 2차원이므로 인덱싱에서 행, 열에 대한 구분이 필요함.
| 함수 | 설명 |
| dim(x), dim(x) <- | 행렬 차원 확인, 부여 |
| nrow(x), ncol(x) | 행의 수, 열의 수 |
| m[nrow, ncol] | 위치의 원소 추출 |
| m[nrow,], m[-nrow,] | 특정 행 접근 |
| m[, ncol], m[, -ncol] | 특정 열 접근 |
| dimnames(m), dimnames(m) <- | 각 차원의 이름 확인, 부여 |
| rownames(m), rownames(m) <- | 각 행의 이름 확인, 부여 |
| colnames(m), colnames(m) <- | 각 열의 이름 확인, 부여 |
| t(m) | 전치행렬 반환 |
| diag(m) | 대각원소 반환 |
matrix의 인덱싱

R의 데이터 구조 : array
array(배열)
- 행렬은 2차원 데이터 구조이고, 배열(array)은 다차원 구조임.
- 생성 함수 : array(data, dim=(행,열, …))
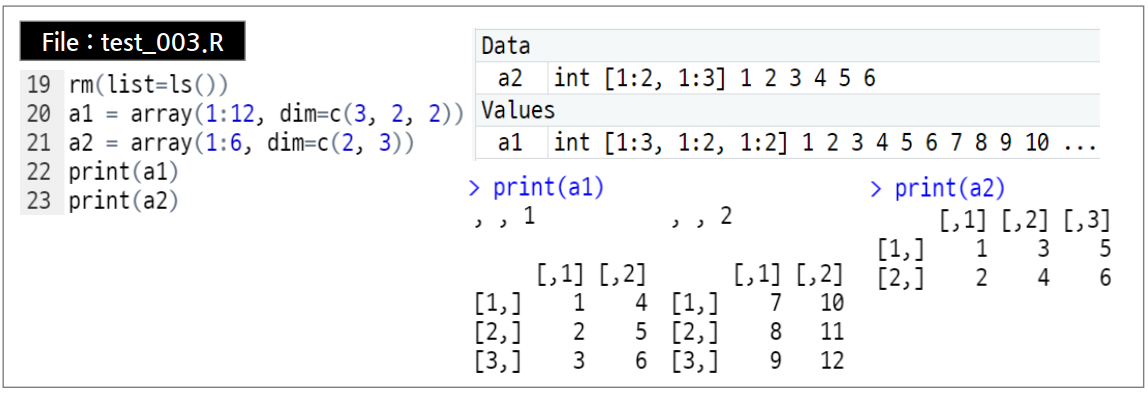
R의 데이터 구조 : data.frame
data.frame(데이터 프레임)
- 엑셀의 워크시트(WorkSheet)와 같은 구조의 2차원 데이터
- ‘여러 가지 데이터 유형’을 가질 수 있음.
- 벡터 별로 다른 데이터 유형 가능
- 벡터가 모여 데이터 프레임을 구성함.

data.frame 생성 함수
- data.frame(vectors or matrices, stringsAsFactors)
- # 벡터의 길이는 모두 같아야 함.
- data.frame(변수명=벡터, … , stringsAsFactors)
- # stringsAsFactors를 TRUE로 지정하면 문자열을 factor형으로 저장함.

data.frame 인덱싱
| 함수 | 설명 |
| df[nrow, ncol] | - 특정 행, 열의 원소 추출 - nrow, ncol --> Scalar |
| df[nrow,] | - 특정 행 추출 - data.frame 반환 |
| df[, ncol] | - 특정 열 추출 - vector 반환 |
| df[ncol] | - 특정 열 추출 - data.frame 반환 |
| df[[ncol]] | - 특정 열 추출 - vector 반환 |
| df[vector, vector] df[vector, ] df[, vector] |
- 해당 vector 목록에 해당하는 data.frame 반환 - vector : 2개 이상의 원소를 갖는 vector |
| df$name | - 특정 열 추출 - vector 반환 |
| df[-ncol] | - 특정 열 제외하고 반환 - data.frame 반환 |

R의 데이터 구조 : list
list(리스트)
- 서로 다른 데이터 타입을 담을 수 있음.
- 리스트에 저장된 데이터를 index 또는 key 를 사용해 접근함
- 생성 함수 : list(key=value, key=value …)

외부 데이터 사용
작업 환경 설정
- 작업 환경 설정
- csv 파일 불러오기, 저장하기
 |
csv 파일 불러오기, 저장하기
- read.csv(‘파일이름’, fileEncoding=‘UTF-8-BOM’)
- write.csv(‘파일이름’, row.names=FALSE)

txt 파일 불러오기
- read.table(‘파일이름’, sep=구분자, col.names=컬럼이름목록)
- 기본값 : header=FALSE, sep=‘

R의 객체 저장/ 불러오기
사용하는 객체를 저장하고 불러오기
- save(객체, file=“파일이름.Rdata”)
- load(“파일이름.Rdata”)

data.frame 핸들링
| 핸들링 | 방법 |
| 새로운 변수 만들기 | 데이터프레임$변수명 또는 데이터프레임[‘변수명’] <- 추가할 데이터 벡터 |
| 조건으로 선택 | subset(x, subset=(조건)) # subset= 생략가능 |
| 목록으로 선택 | subset(x, subset=(조건), select=열/열 목록) |
| 열, 열 목록 제거 | subset(x, subset=(조건), select=-열/-열 목록) |
| 열 이름 바꾸기 | colnames(x) <-, colnames(x)[index] <- |

R의 데이터셋 사용
R의 데이터셋 사용
- x : 데이터셋 이름
- v : 데이터
- n : 숫자
| 함수 | 설명 |
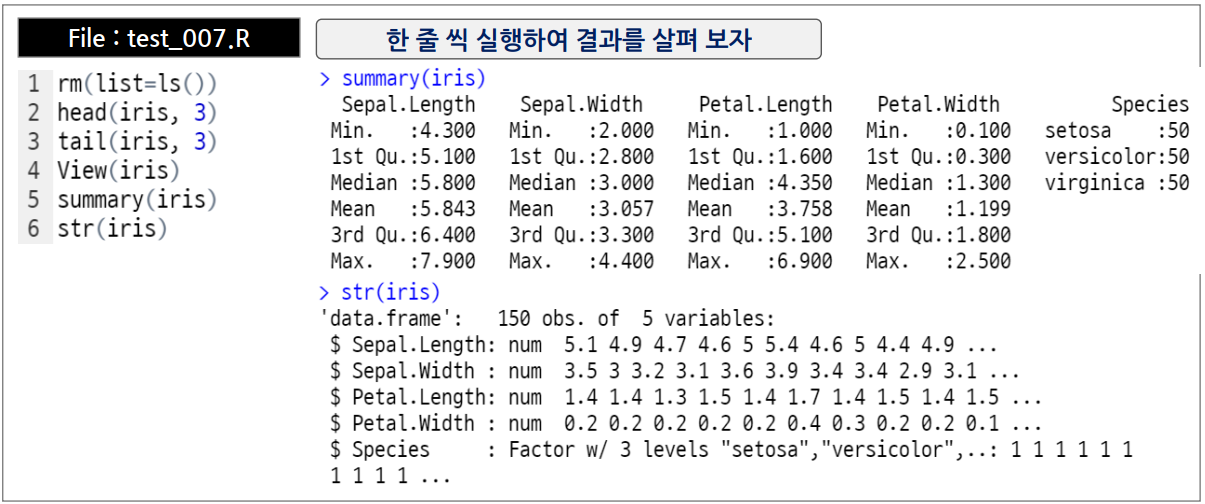
| head(x, n) | - 데이터 셋 처음 여섯 개 반환 - n 지정 시 해당 개수 만큼 반환 |
| tail(x, n) | - 데이터 셋 마지막 여섯 개 반환 - n 지정 시 해당 개수 만큼 반환 |
| View(x) | 창을 열고 엑셀과 유사한 형태로 데이터 셋을 보여줌. |
| summary(x) | 데이터 셋을 구성하는 항목의 기초 통계량을 보여줌. (최솟값, 1사분위수, 중간값, 평균, 3사분위수, 최댓값) |
| str(x) | 데이터의 구성을 표시함 |
| attach(x) | - 데이터셋을 고정으로 사용하겠다고 선언함. - detach 할 때까지 유효 - 변수명만으로 바로 데이터에 접근 가능 (iris$Sepal.Width→Sepal.Width) |
| detach(x) | 고정된 데이터셋 사용을 해제 선언함. |
- head, tail, summary, str : vector, matrix 등의 다양한 객체에 적용 가능
- View : matrix, data.frame, list 등 Data 구조에 적용 가능
R이 기본으로 가지고 있는 데이터셋 사용
그래프 종류
- 그래프의 결과가 통계학적인 유의미를 갖는 것은 아님.
| 그래프 | 함수 | 설명 | 형태 |
| 산점도 | plot(x, y) | 2개 수치형 변수의 상관 관계 알아보기 |  |
| 산점도 행렬 | pairs() | 여러 개의 변수 관계 알아보기 |  |
| 상자 그림 | boxplot() | - 이상치 존재 확인 - IQR 길이, 최소, 최대, 1사분위, 3사분위, 중위값 확인 - NA 제거하고 그려짐. |
 |
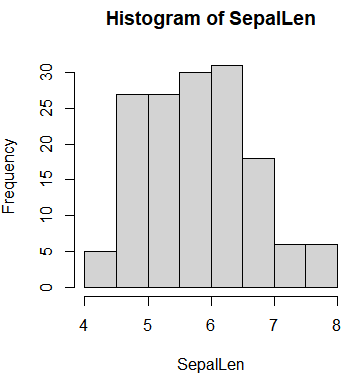
| 히스토그램 | hist() | - 연속형 수치에 적합 - 히스토그램의 사각형 |
 |
| 막대 그래프 | barplot() | - 명목형 변수의 빈도에 활용 - 막대 사이가 끊겨 있는 모양 |
 |
그래프 종류 : Boxplot
- 데이터의 분포를 파악하는 도구

그래프 종류 : Histogram
- 도수 분포표의 각 계급을 가로축에 나타내고, 해당 계급에 속하는 측정값의 도수를 세로축에 표시하여 직사각형 모양으로 그림
왼쪽으로 치우친 모양이라면 데이터가 전체 범위에서 수치가 낮은 쪽에 몰려 있음을 의미하며, 오른쪽에 치우쳐 있다면 높은 쪽에 몰려 있음을 의미함. - 한 쪽으로 치우치는 것 없이 비슷한 높이로 그려진다면 균일한 분포
- 막대 높이는 빈도를 나타내며, 폭은 의미가 없음.
- 가로, 세로축 모두 연속적임.
- 범주형에는 막대그래프를 사용함.
- 많은 데이터를 가지고 있는 경우 보다 정확한 관계 파악을 할 수 있음.
 |
 |
형 변환

apply 계열 함수
- 데이터 조작에 편리한 기능 제공
- apply 함수가 가장 많이 사용됨.
- for문 없이 멀티 코어(Multi-Core) 사용으로 빠르게 연산 가능
- split → apply → combine 기능 제공 (데이터 분할 → 함수 적용 → 재결합)
| 함수 | 설명 |
| apply | - apply(input:array, output:array) - array에 행 또는 열 별로 함수를 적용한 다음 그 결과를 vector 또는 array로 반환 |
| lapply | - lapply(input : vector/list, output : list) - vector, list에 함수를 원소별 적용하여 결과를 list 로 반환 - vector로 변환을 위해 unlist 사용 |
| sapply | - sapply(input : list or vector, output : vector or array) - lapply와 유사하지만 결과를 vector, matrix 또는 array로 반환 |
| tapply | - tapply(input : list or vector and factor, output : vector or array) - 입력 데이터를 특정 기준으로 묶은 다음 각 그룹마다 주어진 함수를 적용하고 그 결과를 반환 |
- 입력에서 list 가능은 data.frame 가능을 포함하고, array 가능은 matrix 가능을 포함.
apply()
- 배열 또는 행렬에 주어진 함수를 적용한 다음 그 결과를 벡터, 배열 또는 리스트로 반환함.
- apply(x, MARGIN, FUN) # x : array/matrix, MARGIN : 1–rows, 2-columns, FUN : function

lapply(), sapply(), tapply()
- lapply(input : vector/list, output : list)
- sapply(input : list or vector, output : vector or array)
- tapply(input : list or vector and factor, output : vector or array)

패키지 설치, 대표적인 패키지
패키지 설치
install.packages('패키지이름') # 패키지 이름은 문자열로
패키지 로딩
ibrary('패키지이름'), library(패키지이름) # 패키지 이름은 문자열 / 이름 자체
주요 패키지
| 패키지 | 설명 |
| reshape | - melt(data, id=...) : id에 정한 변수를 기준(=고정)으로 데이터 구조를 변경함. - cast(data, formula=..., [func=...]) : 데이터를 formula에 있는 형태로 변환하고 func 적용 - formula=행변수(고정)~열변수(변경), 여러 개 변수는 + 로 묶음 |
| reshape2 | cast 대신 acast, dcast 사용 |
| sqldf | sqldf(‘sql 문자열’) |
| plyr | ??ply, adply(), ddply() ... |
reshape 패키지



- r1 : 행을 day, 열을 month로 각 변수들을 새롭게 배치 (3차원 구조, variable은 면의 역할)
- r2 : (행-month, 열-variable) 각 변수들의 month 평균
- r3 : (행-month, 열-variable) 각 변수들의 month 평균을 구하고, 행과 열에 대한 소계 산출
- r4 : 행을 day, 열을 month로 평균을 구함, subset기능을 사용해 ozone 변수만 처리하도록 함.
- r5 : (행-month, 열-variable) 각 변수들의 month rangerange는 min은 ‘_X1’, max는 ‘_X2’ 라는 변수명을 끝에 붙여줌.
sqldf 패키지

- r1: iris의 모든 것을 추출해서 가져옴.
- r2 : iris에서 처음 5개 행을 가져옴, head(iris, 5) 와 동일
- r3: iris에서 species가 ‘ve’로 시작하는 것에 대한 개수를 가져옴.
plyr 패키지
plyr 패키지의 함수들
- (입력데이터)(출력데이터)ply 5글자의 함수명으로 이름이 지어짐.
| 데이터 타입 (입력\출력) | array | data frame | list | nothing |
| array | aaply | adply | alply | a_ply |
| data frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
| function arguments | maply | mdply | mlply | m_ply |
- apply 함수처럼 split – apply – combine 처리하는 함수가 제공됨.
- adply(데이터, 적용방향, 적용할 함수)
- 적용방향 : 1(행), 2(열)
- 2차원 데이터 셋(배열, 행렬, 데이터프레임)을 입력으로 받아 행/열 별로 함수를 적용하고 데이터 프레임을 출력하는 함수
- ddply(데이터, .(그룹 지을 변수명), ddply 내부함수, 적용할 함수)
- ddply 내부함수 : summaries , transform, mutate, subset
- 데이터 프레임을 분할하고 함수에 적용 후 결과를 데이터 프레임으로 반환

유용한 함수들
| 함수 | 이름 |
| paste() | - 입력 받은 객체들의 같은 위치 요소를 하나의 문자열로 붙임. - number <- 1:5 - alphabet <- c(‘a’, ‘b’, ‘c’) - paste(number, alphabet) # "1 a" "2 b" "3 c" "4 a" "5 b" |
| substr() | - 주어진 문자열에서 특정 문자열 추출 - substr(대상, 시작위치, 끝위치) - fruit <- c(“apple”, “banana”, “orange”) - substr(fruit, 1, 2) # "ap" "ba" "or" |
| split() | - 데이터를 분리할 때 사용 - split(데이터, 분리조건) - split(iris, iris$Species) # 3개 data.frame을 갖는 List로 생성됨 |
| subset() | - 특정 부분만 추출하는 용도 - subset(iris, Species==‘setosa’ & Sepal.Length > 5.0) |
| select() | - subset에 select 인자를 지정하면 특정 열을 선택하거나 제외 용도로 사용 - subset(iris, select = c(Sepal.Length, Species)) |
객체의 속성 관련 함수
| 함수 | 설명 |
| is.numeric(x) | - 객체 유형이 numeric 인지 판단 - TRUE/FALSE 반환 |
| is.logical(x) | - 객체 유형이 logical 인지 판단 - TRUE/FALSE 반환 |
| is.character(x) | - 객체 유형이 character 인지 판단 - TRUE/FALSE 반환 |
| is.integer(x) | - 객체 유형이 정수인지 판단 - TRUE/FALSE 반환 |
| is.double(x) | - 객체 유형이 실수인지 판단 - TRUE/FALSE 반환 |
| is.factor(x) | - 객체 유형이 factor 인지 판단 - TRUE/FALSE 반환 |
| is.null(x), is.na(x) | - 객체가 NULL/NA 인지 판단 - TRUE/FALSE 반환 |
| length(x) | - 객체 원소의 개수 반환 - matrix의 경우 행*열의 수 |
| nrow(x) | - 행의 개수 반환 - 벡터, 스칼라 등 에서 사용 못함. |
| NROW(v) | - 벡터의 행의 개수 반환 - 스칼라에서도 사용 가능 |
if, for, while, function

결측치 대치법
단순 대치법(Single Imputation)
| 종류 | 설명 |
| 완전히 응답한 개체 분석 | - Completes case analysis, 불완전 자료는 모두 무시 - 부분적으로 관측된 자료를 무시하므로 생기는 효율성 상실, 통계적 추론의 타당성 문제 존재 |
| 평균대치법 | - 관측 또는 실험을 통해 얻어진 데이터의 평균으로 결측값 대치 - 비조건부 평균 대치법 : 관측 데이터의 평균값으로 대치 - 조건부 평균 대치법 : 회귀분석을 활용한 대치법 |
| 단순확률 대치법 | - 평균대치법에서 추정한 표준 오차의 과소 추정 문제를 보완하고자 고안됨. - Hot-deck, nearest neighbor 방법 등이 있음. |
다중 대치법(Multiple Imputation)
- 단순 대치법을 한 번이 아닌 m번 수행하여 m개의 가상적 완전 자료를 만듦.
- 추정량 표준오차의 과소 추정 또는 계산의 난해성 문제를 가지고 있음.
결측치 인식, 선택, 삭제
| 종류 | 설명 |
| is.na(x) | - x의 포함된 값이 NA인지 아닌지 각각에 대해 TRUE, FALSE 값을 반환함. - logical을 산술 연산이 가능하기 때문에 is.na 함수 적용 후, sum 함수를 사용해 결측치 개수를 파악할 수 있음 sum(is.na(x)) |
| complete.cases(x) | - x가 결측치를 가지고 있지 않은 완전한 데이터인지 확인하는 함수 - 행 별로 결측치가 없으면 TRUE, 있으면 FALSE를 반환함 |
| x[!complete.cases(x), ] | indexing을 사용하여 결측치(NA) 행만 추출 |
| x[complete.cases(x), ] | indexing을 사용하여 결측치(NA)를 포함하지 않은 행 추출 |
| na.omit(x) | 결측치(NA)가 있는 행 전체 삭제 |
728x90
'Certificate > ADsP' 카테고리의 다른 글
| [ADsP] 데이터 분석 : 통계 분석 - 시계열 예측 (0) | 2022.07.02 |
|---|---|
| [ADsP] 데이터 분석 : 통계 분석 - 기초 통계 분석 (0) | 2022.07.02 |
| [ADsP] 데이터 분석 : 통계 분석 - 상관 관계를 이용하는 다변량 분석 (0) | 2022.07.02 |
| [ADsP] 데이터 분석 : 통계 분석 - 통계학 개론 (0) | 2022.07.01 |
| [ADsP] 데이터 분석 기획 : 분석 마스터 플랜 (0) | 2022.06.25 |
| [ADsP] 데이터 분석 기획 : 데이터 분석 기획의 이해 (0) | 2022.06.25 |
| [ADsP] 데이터 이해 : 가치 창조를 위한 데이터 사이언스와 전략 인사이트 (0) | 2022.06.24 |
| [ADsP] 데이터 이해 : 데이터의 가치와 미래 (0) | 2022.06.24 |

