02. 데이터 입·출력 구현
(1) 데이터 전환
데이터 전환
- 운영 중인 기본 정보 시스템에 축적되어 있는 데이터를 추출(Extraction)하여 새로 개발할 정보 시스템에서 운영할 수 있도록 변환(Transformation)한 후, 적재(Loading)하는 일련의 과정
- ETL(Extraction, Transformation, Load), 즉 추출, 변환, 적재 과정이라고 한다.
- 데이터 이행(Data Migration) 또는 데이터 이관이라고도 한다.
데이터 전환 계획서
- 데이터 전환이 필요한 대상을 분석하여 데이터 전환 작업에 필요한 모든 계획을 기록하는 문서
- 주요 항목
- 데이터 전환 개요
- 데이터 전환 대상 및 범위
- 데이터 전환 환경 구성
- 데이터 전환 조직 및 역할
- 데이터 전환 일정
- 데이터 전환 방안
- 데이터 정비 방안
- 비상 계획
- 데이터 복구 대책
(2) 데이터 검증
데이터 검증
- 원천 시스템의 데이터를 목적 시스템의 데이터로 전환하는 과정이 정상적으로 수행되었는지 여부를 확인하는 과정
- 데이터 전환 검증은 검증 방법과 검증 단계에 따라 분류할 수 있다.
검증 방법에 따른 분류
| 검증 방법 | 내용 |
| 로그 검증 | 데이터 전환 과정에서 작성하는 추출, 전환, 적재 로그를 검증함 |
| 기본 항목 검증 | 로그 검증 외에 별도로 요청된 검증 황목에 대해 검증함. |
| 응용 프로그램 검증 | 응용 프로그램을 통한 데이터 전환의 정합성을 검증함. |
| 응용 데이터 검증 | 사전에 정의된 업무 규칙을 기준으로 데이터 전환의 정합성을 검증함. |
| 값 검증 | 숫자 항목의 합계 검증, 코드 데이터의 범위 검증, 속성 변경에 따른 값 검증을 수행함. |
검증 단계에 따른 분류
| 검증 방법 | 목적 | 검증 방법 |
| 추출 | 원천 시스템 데이터에 대한 정합성 확인 | 로그 검증 |
| 전환 | - 매핑 정의서에 정의된 내용이 정확히 반영되었는지 확인 - 매핑 정의서 오류 여부 확인 |
로그 검증 |
| DB 적재 | SAM 파일을 적재하는 과정에서 발생할 수 있는 오류나 데이터 누락 여부 등 확인 | 로그 검증 |
| DB 적재 후 | 적재 완료 후 정합성 확인 | 기본 항목 검증 |
| 전환 완료 후 | 데이터 전환 완료 후 추가 검증 과정을 통해 데이터 전환의 정합성 검증 | 응용 프로그램 검증 응용 데이터 검증 |
(3) 오류 데이터 측정 및 정제
오류 데이터 측정 및 정제
- 고품질의 데이터를 운영 및 관리하기 위해 수행
- 진행 과정
| 진행 과정 | 내용 |
| 데이터 품질 분석 | 오류 데이터를 찾기 위해 원천 및 목적 시스템 데이터의 정합성 여부를 확인하는 작업 |
| 오류 데이터 측정 | 데이터 품질 분석을 기반으로 정상 데이터와 오류 데이터의 수를 측정하여 오류 관리 목록을 작성함. |
| 오류 데이터 정제 | 오류 관리 목록의 각 항목을 분석하여 원천 데이터를 정의하거나 전환 프로그램을 수정함. |
오류 상태
| 상태 | 내용 |
| Open | 오류가 보고만 되고 분석되지 않은 상태 |
| Assigned | 오류의 영향 분석 및 수정을 위해 개발자에게 오류를 전달한 상태 |
| Fixed | 개발자가 오류를 수정한 상태 |
| Closed | 수정된 오류에 대해 테스트를 다시 했을 때 오류가 발견되지 않은 상태 |
| Deferred | 오류 수정을 연기한 상태 |
| Classified | 보고된 오류를 관련자들이 확인했을 때 오류가 아니라고 확인된 상태 |
데이터 정제요청서
- 원천 데이터의 정제와 전환 프로그램의 수정을 위해 요청사항 및 조치사항 등 데이터 정제와 관련된 전반적인 내용을 문서로 작성한 것
- 오류 관리 목록을 기반으로 데이터 정제 요건 목록을 작성하고, 이 목록의 항목별로 데이터 정제요청서를 작성한다.
데이터 정제보고서
- 데이터 정제요청서를 통해 정제된 원천 데이터가 정상적으로 정제되었는지 확인한 결과를 문서로 작성한 것
- 정제 요청 데이터와 정제된 데이터 항목을 눈으로 직접 비교하여 확인한다.
(4) 데이터베이스 개요
데이터저장소
- 데이터들을 논리적인 구조로 조직화하거나, 물리적인 공간에 구축한 것
- 논리 데이터저장소
- 데이터 및 데이터 간의 연관성, 제약 조건을 식별하여 논리적인 구조로 조직화한 것
- 물리 데이터저장소
- 논리 데이터저장소를 소프트웨어가 운용될 환경의 물리적 특성을 고려하여 실제 저장장치에 저장한 것
데이터베이스(Database)
- 여러 사람에 의해 공동으로 사용될 데이터를 중복을 배제하여 통합하고, 쉽게 접근하여 처리할 수 있도록 저장장치에 저장하여 항상 사용할 수 있도록 운영하는 운영 데이터
- 데이터베이스는 다음과 같이 구분하여 정의할 수 있다.
- 통합된 데이터(Integrated Data) : 자료의 중복을 배제한 데이터의 모임
- 저장된 데이터(Stored Data) : 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
- 운영 데이터(Operational Data) : 조직의 고유한 업무를 수행하는 데 반드시 필요한 자료
- 공용 데이터(Shared Data) : 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
DBMS(DataBase Management System; 데이터베이스 관리 시스템)
- 사용자의 요구에 따라 정보를 생성해주고, 데이터베이스를 관리해주는 소프트웨어
- 기존의 파일 시스템이 갖는 데이터의 종속성과 중복성의 문제를 해결하기 위해 제안된 시스템
- 필수 기능 3가지
- 정의(Definition) 기능 : 데이터의 형(Type)과 구조에 대한 정의, 이용 방식, 제약 조건 등을 명시하는 기능
- 조작(Manipulation) 기능 : 데이터 검색, 갱신, 삽입, 삭제 등을 위해 인터페이스 수단을 제공하는 기능
- 제어(Control) 기능 : 데이터의 무결성, 보안, 권한 검사, 병행 제어를 제공하는 기능
데이터의 독립성
- 데이터의 종속성에 대비되는 말로, 논리적 독립성과 물리적 독립성이 있다.
- 논리적 독립성
- 응용 프로그램과 데이터베이스를 독립시킴으로써, 데이터의 논리적 구조를 변경시키더라도 응용 프로그램은 영향을 받지 않음.
- 물리적 독립성
- 응용 프로그램과 보조기억장치 같은 물리적 장치를 독립시킴으로써, 디스크를 추가/변경하더라도 응용 프로그램은 영향을 받지 않음.
- 논리적 독립성
스키마(Schema)
- 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 것
| 종류 | 내용 |
| 외부 스키마 | 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 데이터베이스의 논리적 구조를 정의한 것 |
| 개념 스키마 | - 데이터베이스의 전체적인 논리적 구조 - 모든 응용 프로그램이나 사용자들이 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스로, 하나만 존재함. |
| 내부 스키마 | - 물리적 저장장치의 입장에서 본 데이터베이스 구조 - 실제로 저장될 레코드의 형식, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄. |
(5) 데이터베이스 설계
데이터베이스 설계
- 사용자의 요구를 분석하여 그것들을 컴퓨터에 저장할 수 있는 데이터베이스의 구조에 맞게 변형한 후, DBMS로 데이터베이스를 구현하여 일반 사용자들이 사용하게 하는 것
데이터베이스 설계 시 고려사항
| 항목 | 내용 |
| 무결성 | 삽입, 삭제, 갱신 등의 연산 후에도 데이터베이스에 저장된 데이터가 정해진 제약 조건을 항상 만족해야 함. |
| 일관성 | 데이터베이스에 저장된 데이터들 사이나, 특정 질의에 대한 응답이 처음부터 끝까지 변함없이 일정해야 함. |
| 회복 | 시스템에 장애가 발생했을 때 장애 발생 직전의 상태로 복구할 수 있어야 함. |
| 보안 | 불법적인 데이터의 노출 또는 변경이나 손실로부터 보호할 수 있어야 함. |
| 효율성 | 응답시간의 단축, 시스템의 생산성, 저장 공간의 최적화 등이 가능해야 함. |
| 데이터베이스 확장 | 데이터베이스 운영에 영향을 주지 않으면서 지속적으로 데이터를 추가할 수 있어야 함. |
데이터베이스 설계 순서

요구 조건 분석
- 데이터베이스를 사용할 사람들로부터 필요한 용도를 파악하는 것
- 데이터베이스 사용자에 따른 수행 업무와 필요한 데이터의 종류, 용도, 처리 형태, 흐름, 제약 조건 등을 수집한다.
- 수집된 정보를 바탕으로 요구 조건 명세를 작성한다.
개념적 설계(정보 모델링, 개념화)
- 정보의 구조를 얻기 위하여 현실 세계의 무한성과 계속성을 이해하고, 다른 사람과 통신하기 위하여 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 개념적 설계에서는 개념 스키마 모델링과 트랜잭션 모델링을 병행 수행한다.
- 개념적 설계에서는 요구 분석에서 나온 결과인 요구 조건 명세를 DBMS에 독립적인 E-R 다이어그램으로 작성한다.
- DBMS에 독립적인 개념 스키마를 설계한다.
논리적 설계(데이터 모델링)
- 현실 세계에서 발생하는 자료를 컴퓨터가 이해하고 처리할 수 있는 물리적 저장장치에 저장할 수 있도록 변환하기 위해 특정 DBMS가 지원하는 논리적 자료 구조로 변환(Mapping)시키는 과정
- 개념 세계의 데이터를 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계로 표현되는 논리적 구조의 데이터로 모델화한다.
- 개념적 설계가 개념 스키마를 설계하는 단계라면, 논리적 설계에서는 개념 스키마를 평가 및 정제하고 DBMS에 따라 서로 다른 논리적 스키마를 설계하는 단계이다.
- 트랜잭션의 인터페이스를 설계한다.
물리적 설계(데이터 구조화)
- 논리적 설계에서 논리적 구조로 표현된 데이터를 디스크 등의 물리적 저장장치에 저장할 수 있는 물리적 구조의 데이터로 변환하는 과정
- 물리적 설계에서는 다양한 데이터베이스 응용에 대해 처리 성능을 얻기 위해 데이터베이스 파일의 저장 구조 및 액세스 경로를 결정한다.
- 저장 레코드의 형식, 순서, 접근 경로, 조회 집중 레코드 등의 정보를 사용하여 데이터가 컴퓨터에 저장되는 방법을 묘사한다.
데이터베이스 구현
- 논리적 설계와 물리적 설계에서 도출된 데이터베이스 스키마를 파일로 생성하는 과정
- 사용하려는 특정 DBMS의 DDL(데이터 정의어)을 이용하여 데이터베이스 스키마를 기술한 후, 컴파일하여 빈 데이터베이스 파일을 생성한다.
- 응용 프로그램을 위한 트랜잭션을 작성한다.
- 데이터베이스 접근을 위한 응용 프로그램을 작성한다.
(6) 데이터 모델의 개념
데이터 모델
- 현실 세계의 정보들을 컴퓨터에 표현하기 위해서 단순화, 추상화하여 체계적으로 표현한 개념적 모형
- 데이터, 데이터의 관계, 데이터의 의미 및 일관성, 제약 조건 등을 기술하기 위한 개념적 도구들로 구성되어 있다.
- 데이터베이스 설계 과정에서 데이터의 구조(Schema)를 논리적으로 표현하기 위해 지능적 도구로 사용된다.
- 구성 요소
- 개체
- 속성
- 관계
- 종류
- 개념적 데이터 모델
- 논리적 데이터 모델
- 물리적 데이터 모델
- 표시할 요소
- 구조
- 연산
- 제약 조건
개념적 데이터 모델
- 현실 세계에 대한 인간의 이해를 돕기 위해 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 속성들로 기술된 개체 타입과 이 개체 타입들 간의 관계를 이용하여 현실 세계를 표현한다.
- 현실 세계에 존재하는 개체를 인간이 이해할 수 있는 정보 구조로 표현하기 때문에 정보 모델이라고도 한다.
- 대표적인 모델로 E-R 모델이 있다.
논리적 데이터 모델
- 개념적 모델링 과정에서 얻은 개념적 구조를 컴퓨터가 이해하고 처리할 수 있는 컴퓨터 세계의 환경에 맞도록 변환하는 과정
- 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계를 이용하여 현실 세계를 표현한다.
- 단순히 데이터 모델이라고 하면 논리적 데이터 모델을 의미한다.
- 특정 DBMS는 특정 논리적 데이터 모델 하나만 선정하여 사용한다.
- 데이터 간의 관계를 어떻게 표현하느냐에 따라 관계 모델, 계층 모델, 네트워크 모델로 구분한다.
데이터 모델에 표시할 요소
| 요소 | 내용 |
| 구조(Structure) | 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현 |
| 연산(Operation) | 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 데이터베이스를 조작하는 기본 도구 |
| 제약 조건(Constraint) | 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건 |
(7) 데이터 모델의 구성 요소
개체(Entity)
- 데이터베이스에 표현하려는 것으로, 사람이 생각하는 개념이나 정보 단위 같은 현실 세계의 대상체
- 실세계에 독립적으로 존재하는 유형, 무형의 정보로서 서로 연관된 몇 개의 속성으로 구성된다.
- 독립적으로 존재하나 그 자체로서도 구별이 가능하며, 유일한 식별자(Unique Identifier)에 의해 식별된다.
- 다른 개체와 하나 이상의 관계(Relationship)가 있다.
예제 : 다음은 교수번호, 성명, 전공, 소속으로 구성된 교수 개체이다.
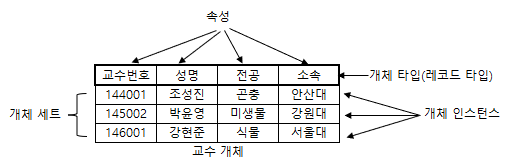
- 해설
- 교수 개체의 구성 요소
- 속성 : 개체가 가지고 있는 특성, 교수번호, 생명, 전공, 소속
- 개체 타입 : 속성으로만 기술된 개체의 정의
- 개체 인스턴스 : 개체를 구성하고 있는 각 속성들이 값을 가져 하나의 개체에 나타내는 것으로, 개체 어커런스(Occurrence)라고도 한다.
- 개체 세트 : 개체 인스턴스의 집합
- 교수 개체의 구성 요소
속성(Attribute)
- 데이터베이스르 구성하는 가장 작은 논리적 단위
- 파일 구조상의 데이터 항목 또는 데이터 필드에 해당한다.
- 개체를 구성하는 항목으로 개체의 특성을 기술한다.
- 속성의 수를 디그리(Degree) 또는 차수라고 한다.
- 속성은 속성의 특성 과 개체 구성 방식 에 따라 분류한다.
속성의 특성에 따른 분류
| 분류 | 내용 |
| 기본 속성 (Basic Attribute) |
- 업무 분석을 통해 정의한 속성 - 속성 중 가장 많고 일반적임. - 업무로부터 분석한 속성이라도 업무상 코드로 정의한 속성은 기본 속성에서 제외됨. |
| 설계 속성 (Designed Attribute) |
- 원래 업무상 존재하지 않고, 설계 과정에서 도출해내는 속성 - 업무에 필요한 데이터 외에 데이터 모델링을 위해 업무를 규칙화하려고 속성을 새로 만들거나 변형하여 정의하는 속성 |
| 파생 속성 (Derived Attribute) |
- 다른 속성으로부터 계산이나 변형 등의 영향을 받아 발생하는 속성 - 되도록 적은 수를 정의하는 것이 좋음. |
*파생 속성은 다른 속성의 영향을 받는 만큼, 프로세스 설계 시 정합성 유지를 위해 유의해야 할 점이 많으므로 되도록 적게 정의하는 것이 좋다.
예제 : 속성의 특성에 따른 분류

- 해설
- 기본 속성인 '자동차명', '제조일', '연비'는 업무 분석을 통해 정의한 가장 일반적인 속성이고, 설계 속성인 '자동차코드'는 판매되는 자동차를 종류별로 구분하기 위해 업무에는 없지만 새롭게 정의한 속성이며, 파생 속성인 '총판매수량'과 '총판매금액'은 특정 기간동안 판매된 자동차의 수량과 금액의 합계 계산을 위해 정의한 속성이다.
속성의 개체 구성 방식에 따른 분류
| 분류 | 내용 |
| 기본키 속성 (Primary Key Attribute) |
개체를 유일하게 식별할 수 있는 속성 |
| 외래키 속성 (Foreign Key Attribute) |
다른 개체와의 관계에서 포함된 속성 |
| 일반 속성 | 개체에 포함되어 있고 기본키, 외래키에 포함되지 않은 속성 |
관계(Relationship)
- 개체와 개체 사이의 논리적인 연결
- 개체 간의 관계와 속성 간의 관계가 있다.
관계의 형태
| 형태 | 내용 |
| 일 대 일(1:1) | 개체 집합 A의 각 원소가 개체 집합 B의 원소 한 개와 대응하는 관계 |
| 일 대 다(1:N) | 개체 집합 A의 각 원소는 개체 집합 B의 원소 여러 개와 대응하고 있지만, 개체 집합 B의 각 원소는 개체 집합 A의 원소 한 개와 대응하는 관계 |
| 다 대 다(N:M) | 개체 집합 A의 각 원소는 개체 집합 B의 원소 여러 개와 대응하고, 개체 집합 B의 각 원소도 개체 집합 A의 원소 여러 개와 대응하는 관계 |
관계의 종류
| 종류 | 내용 |
| 종속 관계 (Dependent Relationship) |
- 두 개체 사이의 주종 관계를 표현한 것 - 식별 관계와 비식별 관계가 있음. |
| 중복 관계 (Redundant Relationship) |
두 개체 사이에 2번 이상의 종속 관계가 발생하는 관계 |
| 재귀 관계 (Recursive Relationship) |
개체가 자기 자신과 관계를 갖는 것으로, 순환 관계(Recursive Relationship)라고도 함. |
| 배타 관계 (Exclusive Relationship) |
- 개체의 속성이나 구분자를 기준으로 개체의 특성을 분할하는 관계 - 배타 AND 관계와 배타 OR 관계로 구분함. |
(8) 식별자(Identifier)
식별자(Identifier)
- 하나의 개체 내에서 각각의 인스턴스를 유일(Unique)하게 구분할 수 있는 구분자
- 모든 개체는 1개 이상의 식별자를 반드시 가져야 한다.
식별자의 분류
| 분류 | 식별자 |
| 대표성 여부 | - 주 식별자(Primary Identifier) : 개체를 대표하는 유일한 식별자 - 보조 식별자(Alternate Identifier) : 주 식별자를 대신하여 개체를 식별할 수 있는 속성 |
| 스스로 생성 여부 | - 내부 식별자(Internal Identifier) : 개체 내에서 스스로 만들어지는 식별자 - 외부 식별자(Foreign Identifier) : 다른 개체와의 관계(Relationship)에 의해 외부 개체의 식별자를 가져와 사용하는 식별자 |
| 단일 속성 여부 | - 단일 식별자(Single Identifier) : 주 식별자가 한 가지 속성으로만 구성된 식별자 - 복합 식별자(Composit Identifier) : 주 식별자가 두 개 이상의 속성으로 구성된 식별자 |
| 대체 여부 | - 원조 식별자(Original Identifier) : 업무에 의해 만들어지는 가공되지 않은 원래의 식별자로, 본질 식별자라고도 함. - 대리 식별자(Surrogate Identifier) : 주 식별자의 속성이 2개 이상인 경우 속성들을 하나의 속성으로 묶어 사용하는 식별자로, 인조 식별자라고도 함. |
후보 식별자
- 개체에서 각 인스턴스를 유일하게 식별할 수 있는 속성 또는 속성 집합
- 하나의 개체에는 한 개 이상의 후보 식별자가 존재할 수 있으며, 이 중 개체의 대표성을 나타내는 식별자를 주 식별자로, 나머지는 보조 식별자로 지정한다.
주 식별자의 특징
- 유일성 : 개체 내의 모든 인스턴스들은 주 식별자에 의해 유일하게 구분되어야 함.
- 최소성 : 유일성을 만족시키기 위해 필요한 최소한의 속성으로만 구성되어야 함.
- 불변성 : 주 식별자가 특정 개체에 한 번 지정되면, 그 식별자는 변하지 않아야 함.
- 존재성 : 주 식별자가 지정되면 식별자 속성에 반드시 데이터 값이 존재해야 함.
주 식별자 특징의 예
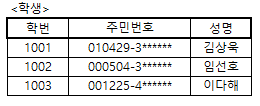
- 위의 <학생> 릴레이션에서 '학번'이나 '주민번호'는 다른 속성과 함께 복합키로 구성되지 않아도 단일 속성만으로(최소성) 다른 레코드들을 유일하게 구별할 수 있으며(유일성), 값이 변경되거나(불변성), 어떤 값도 없이 비어있어서는 안된다(존재성).
(9) E-R(개체-관계) 모델
E-R(Entity-Relationship, 개체-관계) 모델
- 개체와 개체 간의 관계를 기본 요소로 이용하여 현실 세계의 무질서한 데이터를 개념적인 논리 데이터로 표현하기 위한 방법
- 1976년 피터 첸(Peter Chen)에 의해 제안되고 기본적인 구성 요소가 정립되었다.
- 개념적 데이터 모델의 가장 대표적인 것
- 개체 타입(Entity Type)과 이들 간의 관계 타입(Relationship Type)을 이용해 현실 세계를 개념적으로 표현한다.
- 데이터를 개체(Entity), 관계(Relationship), 속성(Attribute)으로 묘사한다.
- E-R 다이어그램으로 표현하며, 1:1, 1:N, N:M 등의 관계 유형을 제한 없이 나타낼 수 있다.
E-R 다이어그램
| 기호 | 기호 이름 | 의미 |
 |
사각형 | 개체(Entity) 타입 |
 |
마름모 | 관계(Relationship) 타입 |
 |
타원 | 속성(Attribute) |
 |
이중 타원 | 다중값 속성(복합 속성) |
 |
밑줄 타원 | 기본키 속성 |
 |
복수 타원 | 복합 속성 예) 성명은 성과 이름으로 구성 |
 |
관계 | 1:1, 1:N, N:M 등의 개체 간 관계에 대한 대응수를 선 위에 기술함. |
 |
선, 링크 | 개체 타입과 속성을 연결 |
(10) 관계형 데이터베이스의 구조 / 관계형 데이터 모델
관계형 데이터베이스
- 2차원적인 표(Table)를 이용해서 데이터 상호 관계를 정의하는 데이터베이스
- 1970년 IBM에 근무하던 코드(E. F. Codd)에 의해 처음 제안되었다.
- 개체(Entity)와 관계(Relationship)를 모두 릴레이션(Relation)이라는 표(Table)로 표현하기 때문에 개체에는 개체 릴레이션과 관계 릴레이션이 존재한다.
- 장점
- 간결하고 보기 편리하다.
- 다른 데이터베이스로의 변환이 용이하다.
- 단점
- 성능이 다소 떨어진다.
관계형 데이터베이스의 릴레이션 구조
- 릴레이션(Relation)은 데이터들을 표(Table)의 형태로 표현한 것으로, 구조를 나타내는 릴레이션 스키마와 실제 값들인 릴레이션 인스턴스로 구성된다.

튜플(Tuple)
- 릴레이션을 구성하는 각각의 행
- 속성의 모임으로 구성된다.
- 파일 구조에서 레코드와 같은 의미이다.
- 튜플의 수를 카디널리티(Cardinality) 또는 기수, 대응수라고 한다.
속성(Attribute)
- 데이터베이스를 구성하는 가장 작은 논리적 단위
- 파일 구조상의 데이터 항목 또는 데이터 필드에 해당된다.
- 속성은 개체의 특성을 기술한다.
- 속성의 수를 디그리(Degree) 또는 차수라고 한다.
도메인(Domain)
- 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자(Atomic)값들의 집합
- 실제 애트리뷰트 값이 나타날 때 그 값의 합법 여부를 시스템이 검사하는데에도 이용된다.
- 예) '성별' 애트리뷰트의 도메인은 "남"과 "여"로, 그 외의 값은 입력될 수 없다.
릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플이 포함될 수 없으므로 릴레이션에 포함된 튜플들은 모두 상이하다.
- 한 릴레이션에 포함된 튜플 사이에는 순서가 없다.
- 튜플들의 삽입, 삭제 등의 작업으로 인해 릴레이션은 시간에 따라 변한다.
- 릴레이션 스키마를 구성하는 속성들 간의 순서는 중요하지 않다.
- 속성의 유일한 식별을 위해 속성의 명칭은 유일해야 하지만, 속성을 구분하는 값은 동일한 값이 있을 수 있다.
- 릴레이션을 구성하는 튜플을 유일하게 식별하기 위해 속성들의 부분집합을 키(Key)로 설정한다.
- 속성의 값은 논리적으로 더 이상 쪼갤 수 없는 원자값만을 저장한다.
관계형 데이터 모델(Relational Data Model)
- 2차원적인 표(Table)를 이용해서 데이터 상호 관계를 정의하는 DB 구조
- 가장 널리 사용되는 데이터 모델
- 파일 구조처럼 구성한 테이블들을 하나의 DB로 묶어서 테이블 내에 있는 속성들 간의 관계(Relationship)를 설정하거나 테이블 간의 관계를 설정하여 이용한다.
- 기본키(Primary Key)와 이를 참조하는 외래키(Foreign Key)로 데이터 간의 관계를 표현한다.
- 계층 모델과 망 모델의 복잡한 구조를 단순화시킨 모델이다.
- 관계형 모델의 대표적인 언어 : SQL
- 1:1, 1:N, N:M 관계를 자유롭게 표현할 수 있다.
(11) 관계형 데이터베이스의 제약 조건 - 키(Key)
키(Key)
- 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 기준이 되는 속성
- 종류
- 후보키(Candidate Key)
- 기본키(Primary Key)
- 대체키(Alternate Key)
- 슈퍼키(Super Key)
- 외래키(Foreign Key)
후보키(Candidate Key)
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용되는 속성들의 부분집합
- 기본키로 사용할 수 있는 속성들
- 유일성(Unique)와 최소성(Minimality)을 모두 만족시켜야 한다.
- 유일성(Unique)
- 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함.
- 최소성(Minimality)
- 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로 구성되어야 함.
- 유일성(Unique)
기본키(Primary Key)
- 후보키 중에서 특별히 선정된 주키(Main Key)
- 중복된 값을 가질 수 없다.
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- NULL 값을 가질 수 없다.
- 튜플에서 기본키로 설정된 속성에는 NULL 값이 있어서는 안 된다.
대체키(Alternate Key)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
- 보조키라고도 한다.
슈퍼키(Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 릴레이션을 구성하는 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 나타나지 않는다.
- 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족하지 못한다.
외래 키(Foreign Key)
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
- 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 때의 속성 A를 외래키라고 한다.
- 외래키로 지정되면 참조 릴레이션의 기본키에 없는 값은 입력할 수 없다.
(12) 관계형 데이터베이스의 제약 조건 - 무결성(Integrity)
무결성(Integrity)
- 데이터베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제값이 일치하는 정확성
- 무결성 제약 조건 : 데이터베이스에 들어 있는 데이터의 정확성을 보장하기 위해 부정확한 자료가 데이터베이스 내에 저장되는 것을 방지하기 위한 제약 조건
무결성의 종류
| 종류 | 내용 |
| 개체 무결성 | 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다는 규정 |
| 참조 무결성 | 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 함. 즉, 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다는 규정 |
| 도메인 무결성 | 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다는 규정 |
| 사용자 정의 무결성 | 속성 값들이 사용자가 정의한 제약조건에 만족되어야 한다는 규정 |
| NULL 무결성 | 릴레이션의 특정 속성 값이 NULL이 될 수 없도록 하는 규정 |
| 고유 무결성 | 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성값들이 서로 달라야 한다는 규정 |
| 키 무결성 | 하나의 릴레이션에는 적어도 하나의 키가 존재해야 한다는 규정 |
| 관계 무결성 | 릴레이션에 어느 한 튜플의 삽입 가능 여부 또는 한 릴레이션과 다른 릴레이션의 튜플들 사이의 관계에 대한 적절성 여부를 지정한 규정 |
데이터 무결성 강화
- 데이터 무결성은 데이터 품질에 직접적인 영향을 미치므로 데이터 특성에 맞는 적절한 무결성을 정의하고 강화해야 한다.
- 데이터 무결성은 애플리케이션, 데이터베이스 트리거, 제약 조건 을 이용하여 강화할 수 있다.
- 애플리케이션
- 데이터 생성, 수정, 삭제 시 무결성 조건을 검증하는 코드를 프로그램 내에 추가함.
- 데이터베이스 트리거
- 트리거 이벤트에 무결성 조건을 실행하는 절차형 SQL을 추가함.
- 제약 조건
- 데이터베이스에 제약 조건을 설정하여 무결성을 유지함.
- 애플리케이션
(13) 관계대수 및 관계해석
관계대수
- 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
- 릴레이션을 처리하기 위해 연산자와 연산 규칙을 제공하며, 피연산자와 연산 결과가 모두 릴레이션이다.
- 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다.
- 관계 데이터베이스에 적용하기 위해 특별히 개발한 순수 관계 연산자와 수학적 집합 이론에서 사용하는 일반 집합 연산자가 있다.
순수 관계 연산자
| 종류 | 특징 | 기호 |
| Select | - 릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산 - 릴레이션의 행에 해당하는 튜플(Tuple)을 구하는 것이므로 수평 연산이라고 함. |
σ (시그마) |
| Project | - 주어진 릴레이션에서 속성 리스트(Attribute List)에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산 - 연산 결과에 중복이 발생하면 중복이 제거됨. - 릴레이션의 열에 해당하는 속성을 추출하는 것이므로 수직 연산자라고 함. |
π (파이) |
| Join | - 공통 속성을 중심으로 2개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 - Join의 결과는 Cartesian Product(교차곱)를 수행한 다음 Select를 수행하는 것과 같음. |
 |
| Division | X ⊃ Y인 2개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산 | ÷ |
일반 집합 연산자
- 수학적 집합 이론에서 사용하는 연산자
- 일반 집합 연산자 중, 합집합(UNION), 교집합(INTERSECTION), 차집합(DIFFERENCE)을 처리하기 위해서는 합병 조건을 만족해야 한다.
- 합병 조건
- 합병하려는 두 릴레이션 간에 속성의 수가 같고, 대응되는 속성별로 도메인이 같아야 한다.
- 예) 릴레이션 R과 S가 합병이 가능하다면, 릴레이션 R의 i번째 속성과 릴레이션 S의 i번째 속성의 도메인이 서로 같아야 한다.
- 그러나 속성의 이름이 같아야 하는 것은 아니다.
- 합병 조건
- 합병 가능한 두 릴레이션 R과 S가 있을 때, 각 연산의 특징을 요약하면 다음과 같다.
| 연산자 | 기능 및 수학적 표현 | 카디널리티 |
| 합집합 UNION ∪ |
- 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플은 제거되는 연산 - R ∪ S = { t | t ∈ R ∨ t ∈ S } (t는 릴레이션 R 또는 S에 존재하는 튜플) |
- |R ∪ S| ≤ |R| + |S| - 합집합의 카디널리티는 두 릴레이션 카디널리티의 합보다 크지 않음. |
| 교집합 INTERSECTION ∩ |
- 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산 - R ∪ S = { t | t ∈ R ∧ t ∈ S } (t는 릴레이션 R 그리고 S에 동시에 존재하는 튜플) |
- |R ∩ S| ≤ MIN{ |R|, |S| } - 교집합의 카디널리티는 두 릴레이션 중 카디널리티가 적은 릴레이션의 카디널리티보다 크지 않음. |
| 차집합 DIFFERENCE - |
- 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산 - R - S = { t | t ∈ R ∧ t ∉ S } (t는 릴레이션 R에는 존재하고 S에 없는 튜플) |
- |R - S| ≤ |R| - 차집합의 카디널리티는 릴레이션 R의 카디널리티 보다 크지 않음. |
| 교차곱 CARTESIAN PRODUCT × |
- 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산 - R × S = { r · s | r ∈ R ∧ s ∈ S } (r은 R에 존재하는 튜플이고, s는 S에 존재하는 튜플) |
- |R × S| = |R| × |S| - 교차곱은 두 릴레이션의 카디널리티를 곱한 것과 같음. |
관계해석(Relational Calculus)
- 관계 데이터의 연산을 표현하는 방법
- 관계 데이터 모델의 제안자인 코드(E. F. Codd)가 수학의 Predicate Calculus(술어 해석)에 기반을 두고 관계 데이터베이스를 위해 제안했다.
- 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특성을 지닌다.
- 원하는 정보를 정의할 때는 계산 수식을 사용한다.
(14) 이상 / 함수적 종속
이상(Anomaly)
- 테이블에서 일부 속성들의 종속으로 인해 데이터의 중복이 발생하고, 이 중복(Redundancy)으로 인해 테이블 조작 시 문제가 발생하는 현상
- 이상의 종류 (테이블 조작 중 발생)
- 삽입 이상(Insertion Anomaly)
- 삭제 이상(Deletion Anomaly)
- 갱신 이상(Update Anomaly)
예제
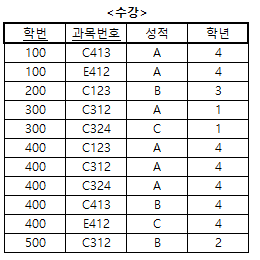
삽입 이상(Insertion Anomaly)
- 테이블에 데이터를 삽입할 때 의도와는 상관없이 원하지 않은 값들로 인해 삽입할 수 없게 되는 현상
- 예) <수강> 테이블에서 학번이 "600"인 학생의 학년이 "2"라는 사실만을 삽입하고자 하는 경우, 삽입 이상이 발생한다.
- <수강> 테이블의 기본키는 학번과 과목번호이기 때문에 삽입할 때 반드시 과목번호가 있어야 한다.
- 즉, 데이터가 발생되는 시점에는 과목번호가 필요 없지만 <수강> 테이블에 기록하고자 할 때 과목번호가 없어 등록할 수 없는 경우가 발생한다.
삭제 이상(Deletion Anomaly)
- 테이블에서 한 튜플을 삭제할 때 의도와는 상관없는 값들도 함께 삭제되는, 즉 연쇄 삭제가 발생하는 현상
- 예) <수강> 테이블에서 학번이 "200"인 학생이 과목번호 "C123"의 등록을 취소하고자 할 경우 삭제 이상이 발생한다.
- 학번이 "200"인 학생의 과목번호가 "C123"인 과목을 취소하고자 그 학생의 튜플을 삭제하면 학년 정보까지 같이 삭제된다.
- 과목만을 취소하고자 했지만 유지되어야 할 학년 정보까지 삭제되기 때문에 정보 손실이 발생한다.
갱신 이상(Update Anomaly)
- 테이블에서 튜플에 있는 속성 값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 불일치성(Inconsistency)이 생기는 현상
- 예) <수강> 테이블에서 학번이 "400"인 학생의 학년을 "4"에서 "3"으로 변경하고자 하는 경우 갱신 이상이 발생할 수 있다.
- 학번이 "400"인 모든 튜플의 학년 값을 갱신해야 하는데 실수로 일부 튜플만 갱신하면, 학번 "400"인 학생의 학년은 "3"과 "4", 즉 2가지 값을 가지게 되어 정보에 불일치성이 생기게 된다.
함수적 종속(Functional Dependency)
- 어떤 테이블 R에서 X와 Y를 각각 R의 속성 집합의 부분 집합이라 하자.
- 속성 X의 값 각각에 대해 시간에 관계없이 항상 속성 Y의 값이 오직 하나만 연관되어 있을 때 Y는 X에 함수적 종속 또는 X가 Y를 함수적으로 결정한다고 하고, X → Y로 표기한다.
- 함수적 종속은 데이터의 의미를 표현하는 것으로, 현실 세계를 표현하는 제약 조건이 되는 동시에 데이터베이스에서 항상 유지되어야 할 조건이다.
예제 1 : <학생> 테이블에서 함수적 종속 살펴보기
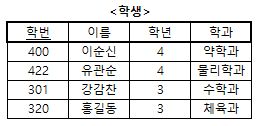

- 해설
- <학생> 테이블에서 이름, 학년, 학과는 각각 학번 속성에 함수적 종속이다.
- X → Y의 관계를 갖는 속성 X와 Y에서 X를 결정자(Determinant)라 하고, Y를 종속자(Dependent)라고 한다.
- 예를 들어, '학번 → 이름'에서는 학번이 결정자이고, 이름이 종속자이다.
예제 2 : <수강> 테이블에서 함수적 종속을 기호로 표시하기
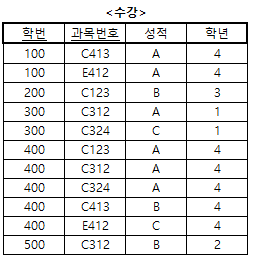

- 해설
- <수강> 테이블의 속성 중 성적은 (학번, 과목번호)에 완전 함수적 종속(Full Functional Dependency)이라고 한다.
- 반면, <수강> 테이블의 속성 중 학년은 (학번, 과목번호)에 완전 함수적 종속이 아니므로 부분 함수적 종속(Partial Functional Dependency)이라고 한다.
완전 함수적 종속
- 어떤 테이블 R에서 속성 Y가 다른 속성 집합 X 전체에 대해 함수적 종속이면서 속성 집합 X의 어떠한 진부분 집합 Z(즉, Z ⊂ X)에도 함수적 종속이 아닐 때 속성 Y는 속성 집합 X에 완전 함수 종속이라고 한다.
부분 함수적 종속
- 어떤 테이블 R에서 속성 Y가 다른 속성 집합 X 전체에 대해 함수적 종속이면서 속성 집합 X의 임의의 진부분 집합에 대해 함수적 종속일 때, 속성 Y는 속성 집합 X에 부분 함수적 종속이라고 한다.
완전/부분 함수적 종속의 이해
- 완전 함수적 종속이라는 말은 어떤 속성이 기본키에 대해 완전히 종속적일 때를 말한다.
- <수강> 테이블은 (학번, 과목번호)가 기본키인데, 성적은 학번과 과목번호가 같을 경우에는 항상 같은 성적이 나오므로(즉, 성적은 학번과 과목번호에 의해서만 결정되므로) 성적은 기본키(학번, 과목번호)에 완전 함수적 종속이 되는 것이다.
- 반면에 학년은 과목번호에 관계없이 학번이 같으면 항상 같은 학년이 나오므로(즉, 기본키의 일부인 학번에 의해서 학년이 결정되므로) 학년은 부분 함수적 종속이라고 한다.
(15) 정규화(Normalization)
정규화(Normalization)
- 테이블의 속성들이 상호 종속적인 관계를 갖는 특성을 이용하여 테이블을 무손실 분해하는 과정
- 무손실 분해
- 테이블 R의 프로젝션(특정 테이블에서 일부 속성들만 추출하여 만든 테이블)인 R1, R2가 NATURAL JOIN을 통해 원래의 테이블 R로 정보 손실 없이 복귀되는 경우, R은 R1과 R2로 무손실 분해되었다고 한다.
-
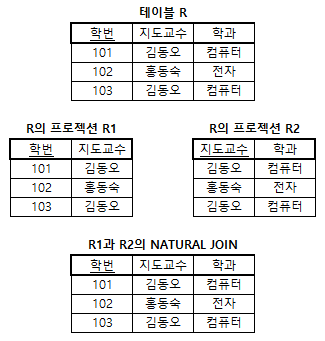
- 무손실 분해
- 정규화의 목적
- 가능한 한 중복을 제거하여 삽입, 삭제, 갱신 이상의 발생 가능성을 줄이는 것
- 정규형에는 다음이 있으며, 순서대로 정규화의 정도가 높아진다.
- 제 1정규형(1NF; First Normal Form)
- 제 2정규형(2NF; Second Normal Form)
- 제 3정규형(3NF; Third Normal Form)
- BCNF(Boyce-Codd Normal Form)
- 제 4정규형(4NF; Fourth Normal Form)
- 제 5정규형(5NF; Fifth Normal Form)
정규화의 과정
제 1정규형
- 테이블 R에 속한 모든 속성의 도메인(Domain)이 원자 값(Atomic Value)만으로 되어 있는 정규형
- 테이블의 모든 속성 값이 원자 값으로만 되어 있는 정규형
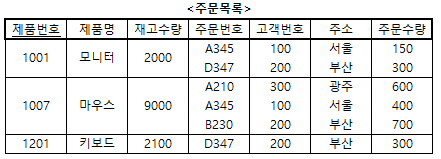
- <주문목록> 테이블에서는 하나의 제품에 대해 여러 개의 주문 관련 정보(주문번호, 고객번호, 주소, 주문수량)가 발생하고 있다.
- 따라서 <주문목록> 테이블은 제 1정규형이 아니다.
예제 1 : <주문목록> 테이블에서 반복되는 주문 관련 정보를 분리하여 제 1정규형으로 만드시오.
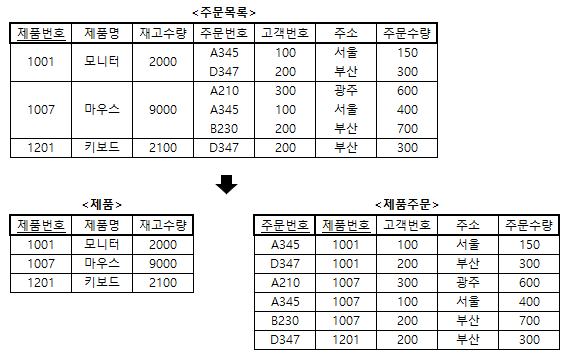
- 해설
- <주문목록> 테이블에서 반복되는 주문 관련 정보인 주문번호, 고객번호, 주소, 주문수량을 분리하면 위와 같이 제 1정규형인 <제품> 테이블과 <제품주문> 테이블이 만들어진다.
- 1차 정규화 과정으로 생성된 <제품주문> 테이블의 기본키는 (주문번호, 제품번호)이고, 다음과 같은 함수적 종속이 존재한다.
-
- 1차 정규화 과정으로 생성된 <제품주문> 테이블의 기본키는 (주문번호, 제품번호)이고, 다음과 같은 함수적 종속이 존재한다.
- <주문목록> 테이블에서 반복되는 주문 관련 정보인 주문번호, 고객번호, 주소, 주문수량을 분리하면 위와 같이 제 1정규형인 <제품> 테이블과 <제품주문> 테이블이 만들어진다.

제 2정규형
- 테이블 R이 제 1정규형이고, 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형
- <주문목록> 테이블이 <제품> 테이블과 <제품주문> 테이블로 무손실 분해되면서 모두 제 1정규형이 되었지만, 그 중 <제품주문> 테이블에는 기본키인 (주문번호, 제품번호)에 완전 함수적 종속이 되지 않는 속성이 존재한다.
- 즉, 주문수량은 기본키에 대해 완전 함수적 종속이지만 고객번호와 주소는 주문번호에 의해서도 결정될 수 있으므로, 기본키에 대해 완전 함수적 종속이 아니다.
- 따라서 <제품주문> 테이블은 제 2정규형이 아니다.
- 즉, 주문수량은 기본키에 대해 완전 함수적 종속이지만 고객번호와 주소는 주문번호에 의해서도 결정될 수 있으므로, 기본키에 대해 완전 함수적 종속이 아니다.
예제 2 : <제품주문> 테이블에서 주문번호에 함수적 종속이 되는 속성들을 분리하여 제 2정규형을 만드시오.
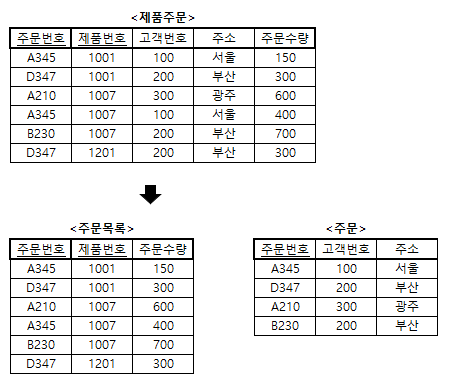
- 해설
- <제품주문> 테이블에서 주문번호에 함수적 종속이 되는 속성인 고객번호와 주소를 분리(즉, 부분 함수적 종속을 제거)해 내면 위와 같이 제 2정규형인 <주문목로> 테이블과 <주문> 테이블로 무손실 분해된다.
- 제 2정규화 과정을 거쳐 생성된 <주문> 테이블의 기본키는 주문번호이다.
- 그리고 <주문> 테이블에는 아직도 다음과 같은 함수적 종속들이 존재한다.
- <제품주문> 테이블에서 주문번호에 함수적 종속이 되는 속성인 고객번호와 주소를 분리(즉, 부분 함수적 종속을 제거)해 내면 위와 같이 제 2정규형인 <주문목로> 테이블과 <주문> 테이블로 무손실 분해된다.

제 3정규형
- 테이블 R이 제 2정규형이고 기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수적 종속(Transitive Functional Dependency)을 만족하지 않는 정규형
- 이행적 함수적 종속 : A → B 이고, B → C 일 때, A → C를 만족하는 관계
- <제품주문> 테이블이 <주문목록> 테이블과 <주문> 테이블로 무손실 분해되면서 모두 제 2정규형이 되었다.
- 그러나 <주문> 테이블에서 고객번호가 주문번호에 함수적 종속이고, 주소가 고객번호에 함수적 종속이므로 주소는 기본키인 주문번호에 대해 이행적 함수적 종속을 만족한다.
- 즉, 주문번호 → 고객번호이고, 고객번호 → 주소이므로 주문번호 → 주소는 이행적 함수적 종속이 된다.
- 따라서 <주문> 테이블은 제 3정규형이 아니다.
- 즉, 주문번호 → 고객번호이고, 고객번호 → 주소이므로 주문번호 → 주소는 이행적 함수적 종속이 된다.
- 그러나 <주문> 테이블에서 고객번호가 주문번호에 함수적 종속이고, 주소가 고객번호에 함수적 종속이므로 주소는 기본키인 주문번호에 대해 이행적 함수적 종속을 만족한다.
예제 3 : <주문> 테이블에서 이행적 함수적 종속을 제거하여 제 3정규형을 만드시오.
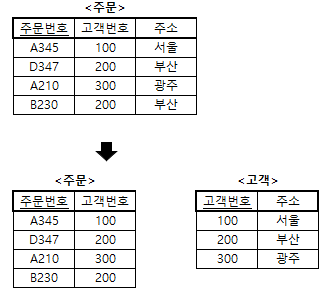
- 해설
- <주문> 테이블에서 이행적 함수적 종속(즉, 주문번호 → 주소)을 제거하여 무손실 분해함으로써 위와 같이 제 3정규형인 <주문> 테이블과 <고객> 테이블이 생성된다.
BCNF
- 테이블 R에서 모든 결정자가 후보키(Candidate Key)인 정규형
- 일반적으로 제 3정규형에 후보키가 여러 개 존재하고, 이러한 후보키들이 서로 중첩되어 나타나는 경우에 적용 가능하다.
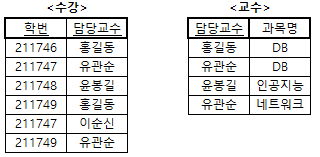
- 아래의 <수강_교수> 테이블(제 3정규형)은 함수적 종속{(학번, 과목명) → 담당교수, (학번, 담당교수) → 과목명, 담당교수 → 과목명}을 만족하고 있다.
- <수강_교수> 테이블의 후보키는 (학번, 과목명)과 (학번, 담당교수)이다.
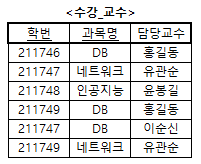
- <수강_교수> 테이블에서 결정자 중 후보키가 아닌 속성이 존재한다.
- 즉, 함수적 종속 담당교수 → 과목명이 존재하는데, 담당교수가 <수강_교수> 테이블에서 후보키가 아니기 때문에 <수강_교수> 테이블은 BCNF가 아니다.
예제 4 : <수강_교수> 테이블에서 결정자가 후보키가 아닌 속성을 분리하여 BCNF를 만드시오.
- 해설
- <수강_교수> 테이블에서 BCNF를 만족하지 못하게 하는 속성(즉, 담당교수 → 과목명)을 분리해내면 위와 같이 BCNF인 <수강> 테이블과 <교수> 테이블로 무손실 분해된다.
제 4정규형
- 테이블 R에 다중 값 종속(MVD; Multi Valued Dependency) A →→ B 가 존재할 경우, R의 모든 속성이 A에 함수적 종속 관계를 만족시키는 정규형
- 다중 값 종속(다치 종속)
- A, B, C 3개의 속성을 가진 테이블 R에서 어떤 복합 속성(A, C)에 대응하는 B 값의 집합이 A 값에만 종속되고 C 값에는 무관하면, B는 A에 다중 값 종속이라 하고 A →→ B로 표기한다.
- 다중 값 종속(다치 종속)
제 5정규형
- 테이블 R의 모든 조인 종속(JD; Join Dependency)이 R의 후보키를 통해서만 성립되는 정규형
- 조인 종속
- 어떤 테이블 R의 속성에 대한 부분 집합 X, Y, ..., Z가 있다고 할 때, 만약 테이블 R이 자신의 프로젝션(Projection) X, Y, ..., Z를 모두 조인한 결과와 동일한 경우 테이블 R은 조인 종속 JD(X, Y, ..., Z)를 만족한다고 한다.
- 조인 종속
정규화 과정 정리
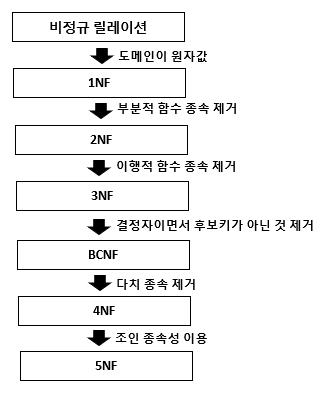
*도부이결다조 (두부이걸다줘?)
- 도메인이 원자값
- 부분적 함수 종속 제거
- 이행적 함수 종속 제거
- 결정자이면서 후보키가 아닌 것 제거
- 다치 종속 제거
- 조인 종속성 이용
(16) 반정규화(Denormalization)
반정규화
- 시스템의 성능을 향상하고 개발 및 운영의 편의성 등을 높이기 위해 정규화된 데이터 모델을 의도적으로 통합, 중복, 분리하여 정규화 원칙을 위배하는 행위
- 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성은 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있다.
- 과도한 반정규화는 오히려 성능을 저하시킬 수 있다.
- 반정규화의 방법
- 테이블 통합
- 테이블 분할
- 중복 테이블 추가
- 중복 속성 추가
테이블 통합
- 2개의 테이블이 조인(Join)되어 사용되는 경우가 많을 경우 성능 향상을 위해 아예 하나의 테이블로 만들어 사용하는것
- 테이블 통합을 고려하는 경우
- 2개의 테이블에서 발생하는 프로세스가 동일하게 자주 처리되는 경우
- 항상 2개의 테이블을 이용해서 조회를 수행하는 경우
- 테이블 통합의 종류
- 1:1 관계 테이블 통합
- 1:N 관계 테이블 통합
- 슈퍼타입/서브타입 테이블 통합
- 슈퍼 타입 : 상위 개체
- 서브 타입 : 하위 개체
테이블 분할
- 테이블을 수직 또는 수평으로 분할하는 것
| 방법 | 내용 |
| 수평 분할 | - 레코드(Record)를 기준으로 테이블을 분할하는 것 - 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할함. |
| 수직 분할 | - 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것 - 종류 : 갱신 위주의 속성 분할, 자주 조회되는 속성 분할, 크기가 큰 속성 분할, 보안을 적용해야 하는 속성 분할 |
중복 테이블 추가
- 작업의 효율성을 향상시키기 위해 테이블을 추가하는 것
- 중복 테이블을 추가하는 경우
- 여러 테이블에서 데이터를 추출해서 사용해야 할 경우
- 다른 서버에 저장된 테이블을 이용해야 하는 경우
- 중복 테이블 추가 방법
| 집계 테이블의 추가 | 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거(Trigger)를 설정하여 사용하는 것 |
| 진행 테이블의 추가 | 이력 관리 등의 목적으로 추가하는 테이블 |
| 특정 부분만을 포함하는 테이블의 추가 | 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성 |
중복 속성 추가
- 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것
- 중복 속성을 추가하면 데이터의 무결성 확보가 어렵고, 디스크 공간이 추가로 필요하다.
- 중복 속성을 추가하는 경우
- 조인이 자주 발생하는 속성인 경우
- 접근 경로가 복잡한 속성인 경우
- 액세스의 조건으로 자주 사용되는 속성의 경우
- 기본키의 형태가 적절하지 않거나 여러 개의 속성으로 구성된 경우
(17) 시스템 카탈로그
시스템 카탈로그(System Catalog)
- 시스템 그 자체에 관련이 있는 다양한 객체에 관한 정보를 포함하는 시스템 데이터베이스
- 시스템 카탈로그 내의 각 테이블은 사용자를 포함하여 DBMS에서 지원하는 모든 데이터 객체에 대한 정의나 명세에 관한 정보를 유지 관리하는 시스템 테이블이다.
- 카탈로그들이 생성되면 데이터 사전(Data Dictionary)에 저장되기 때문에 좁은 의미로는 카탈로그를 데이터 사전이라고도 한다.
메타 데이터(Meta-Data)
- 시스템 카탈로그에 저장된 정보
- 메타 데이터의 유형
- 데이터베이스 객체 정보 : 테이블(Table), 인덱스(Index), 뷰(View) 등의 구조 및 통계 정보
- 사용자 정보 : 아이디, 패스워드, 접근 권한 등
- 테이블의 무결성 제약 조건 정보 : 기본키, 외래키, NULL 값 허용 여부 등
- 함수, 프로시저, 트리거 등에 대한 정보
데이터 디렉터리(Data Directory)
- 데이터 사전에 수록된 데이터에 접근하는 데 필요한 정보를 관리 유지하는 시스템
- 시스템 카탈로그는 사용자와 시스템 모두 접근할 수 있지만, 데이터 디렉터리는 시스템만 접근할 수 있다.
(18) 데이터베이스 저장 공간 설계
데이터베이스 저장 공간 설계
- 데이터베이스에 데이터를 저장하려면 테이블이나 컬럼 등 실제 데이터가 저장되는 공간을 확보해야 한다.
| 객체 | 내용 |
| 테이블(Table) | - 데이터베이스의 가장 기본적인 객체 - 로우(Row, 행)와 컬럼(Column, 열)으로 구성되어 있음. - 데이터베이스의 모든 데이터는 테이블에 저장됨. |
| 컬럼(Column) | - 테이블의 열을 구성하는 요소 - 데이터 타입(Data Type), 길이(Length) 등으로 정의됨. |
| 테이블스페이스(Tablespace) | - 테이블이 저장되는 논리적인 영역 - 한 개의 테이블스페이스에 한 개 이상의 테이블을 저장할 수 있음. |
테이블 종류
| 종류 | 내용 |
| 일반 테이블 | - 대부분의 DBMS에서 표준 테이블로 사용되는 테이블 형태 - 데이터를 정렬하지 않고 가장 적절한 기억 장소에 저장한 후 임의의 방식으로 데이터를 관리하는 힙(Heap) 구조를 사용하므로 힙 구조 테이블(Heap-Organized Table)이라고도 한다. |
| 클러스터드 인덱스 테이블 (Clustered Index Table) |
- 기본키(Primary Key)나 인덱스키의 순서에 따라 데이터가 저장되는 테이블 - 일반적인 인덱스를 사용하는 테이블에 비해 접근 경로가 단축됨. |
| 파티셔닝 테이블 (Partitioning Table) |
대용량의 테이블을 작은 논리적 단위인 파티션(Partition)으로 나눈 테이블 |
| 외부 테이블 (External Table) |
- 데이터베이스에서 일반 테이블처럼 이용할 수 있는 외부 파일 - 데이터베이스 내에 객체로 존재함. |
| 임시 테이블 (Temporary Table) |
- 트랜잭션이나 세션별로 데이터를 저장하고 처리할 수 있는 테이블 - 임시 테이블에 저장된 데이터는 트랜잭션이 종료되면 삭제됨. |
(19) 트랜잭션 분석 / CRUD 분석
트랜잭션(Transaction)
- 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들
- 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용된다.
- 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위로 사용된다.
트랜잭션의 특성
| 특성 | 의미 |
| Atomicity (원자성) |
트랜잭션의 연산은 데이터베이스에 모두 반영되도록 완료(Commit)되든지 아니면 전혀 반영되지 않도록 복구(Rollback) 되어야 함. |
| Consistency (일관성) |
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환됨. |
| Isolation (독립성, 격리성, 순차성) |
둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없음. |
| Durability (영속성, 지속성) |
성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 함. |
CRUD 분석
- 프로세스와 테이블 간에 CRUD 매트릭스를 만들어서 트랜잭션을 분석하는 것
- CRUD 분석을 통해 많은 트랜잭션이 물리는 테이블을 파악할 수 있으므로 디스크 구성 시 유용한 자료로 활용할 수 있다.
- CRUD 매트릭스
- 2차원 형태의 표로서, 행(Row)에는 프로세스를, 열(Column)에는 테이블을, 행과 열이 만나는 위치에는 프로세스가 테이블에 발생시키는 변화를 표시하여 프로세스와 데이터 간의 관계를 분석하는 분석표
- CRUD 매트릭스를 통해 트랜잭션이 테이블에 수행하는 작업을 검증한다.
- CRUD 매트릭스의 각 셀에는 CEATE, READ, UPDATE, DELETE의 앞 글자가 들어가며, 복수의 변화를 줄 때는 기본적으로 'C > D > U > R'의 우선순위를 적용하여 한 가지만 적지만, 활용 목적에 따라 모두 기록할 수 있다.
- 예) '주문 변경' 프로세스를 실행하려면 테이블의 데이터를 읽은(Read) 다음 수정(Update) 해야 하므로 R(Read)과 U(Update)가 필요하지만, CRUD 매트릭스에는 우선순위가 높은 'U'만 표시한다.
- CRUD 매트릭스가 완성되었다면 C, R, U, D 중 어느 것도 적히지 않은 행이나 열, C나 R이 없는 열을 확인하여 불필요하거나 누락된 테이블 또는 프로세스를 찾는다.
예 : 온라인 쇼핑몰의 CRUD 매트릭스 예시
| 프로세스 \ 테이블 | 회원 | 상품 | 주문 | 주문목록 | 제조사 |
| 신규 회원 등록 | C | ||||
| 회원정보 변경 | R, U | ||||
| 주문 요청 | R | R | C | C | |
| 주문 변경 | R | R, U | |||
| 주문 취소 | R, D | R, D | |||
| 상품 등록 | C | C, R | |||
| 상품정보 변경 | R, U | R, U |
트랜잭션 분석
- CRUD 매트릭스를 기반으로 테이블에 발생하는 트랜잭션 양을 분석하여 테이블에 저장되는 데이터의 양을 유추하고 이를 근거로 DB의 용량 산정 및 구조의 최적화를 목적으로 한다.
- 트랜잭션 분석은 업무 개발 담당자가 수행한다.
- 트랜잭션 분석을 통해 프로세스가 과도하게 접근하는 테이블을 확인할 수 있으며, 이러한 집중 접근 테이블을 여러 디스크에 분산 배치함으로써 디스크 입·출력 향상을 통한 성능 향상을 가져올 수 있다.
- 트랜잭션 분석서
- 단위 프로세스와 CRUD 매트릭스를 이용하여 작성한다.
- 구성 요소 : 단위 프로세스, CRUD 연산, 테이블명, 컬럼명, 테이블 참조 횟수, 트랜잭션 수, 발생 주기 등
예 : '주문요청' 프로세스에 대한 트랜잭션 분석서 예시
| 프로세스 | CRUD | 테이블명 | 컬럼명 | 참조횟수 | 트랜잭션 수 | 주기 |
| 주문 요청 | R | 회원 | 회원번호, 회원명, 주소 | 1 | 150 | 일 |
| R | 상품 | 상품번호, 상품명, 재고량 | 1 | 150 | ||
| C | 주문 | 주문번호, 일자, 회원번호 | 3 | 450 | ||
| C | 주문목록 | 주문번호, 상품번호, 수량, 가격 | 5 | 750 |
(20) 인덱스
인덱스(Index)
- 데이터 레코드를 빠르게 접근하기 위해 <키 값, 포인터> 쌍으로 구성되는 데이터 구조
- 레코드가 저장된 물리적 구조에 접근하는 방법을 제공한다.
- 인덱스를 통해서 파일의 레코드에 빠르게 엑세스할 수 있다.
- 레코드의 삽입과 삭제가 수시로 일어나는 경우에는 인덱스의 개수를 최소로 하는 것이 효율적이다.
인덱스의 종류
| 종류 | 내용 |
| 트리 기반 인덱스 | 인덱스를 저장하는 블록들이 트리 구조를 이루고 있는 것 |
| 비트맵 인덱스 | 인덱스 컬럼의 데이터를 Bit 값인 0 또는 1로 변환하여 인덱스 키로 사용하는 방법 |
| 함수 기반 인덱스 | 컬럼의 값 대신 컬럼에 특정 함수(Function)나 수식(Expression)을 적용하여 산출된 값을 사용하는 것 |
| 비트맵 조인 인덱스 | 다수의 조인된 객체로 구성된 인덱스 |
| 도메인 인덱스 | 개발자가 필요한 인덱스를 직접 만들어 사용하는 것 |
클러스터드/넌클러스터드 인덱스
| 종류 | 내용 |
| 클러스터드 인덱스 (Clustered Index) |
- 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식 - 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있음. |
| 넌클러스터드 인덱스 (Non-Clustered Index) |
- 인덱스의 키 값만 정렬되어 있고 실제 데이터는 정렬되지 않는 방식 - 데이터 삽입, 삭제 발생 시 순서를 유지하기 위해 데이터를 재정렬해야 함. |
(21) 뷰 / 클러스터
뷰(View)
- 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블
- 뷰는 저장장치 내에 물리적으로 존재하지 않지만, 사용자에게는 있는 것처럼 간주된다.
- 뷰를 통해서만 데이터에 접근하게 하면 뷰에 나타나지 않는 데이터를 안전하게 보호하는 효율적인 기법으로 사용할 수 있다.
- 뷰가 정의된 기본 테이블이나 뷰를 삭제하면 그 테이블이나 뷰를 기초로 정의된 다른 뷰도 자동으로 삭제된다.
- 뷰를 정의할 때는 CREATE 문, 제거할 때는 DROP 문을 사용한다.
뷰의 장·단점
| 장점 | 단점 |
| - 논리적 데이터 독립성을 제공함. - 동일 데이터에 대해 동시에 여러 사용자의 상이한 응용이나 요구를 지원해 줌. - 사용자의 데이터 관리를 간단하게 해줌. - 접근 제어를 통한 자동 보안이 제공됨. |
- 독립적인 인덱스를 가질 수 없음. - 뷰의 정의를 변경할 수 없음. - 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신 연산에 제약이 따름. |
클러스터(Cluster)
- 데이터 저장 시 데이터 액세스 효율을 향상시키기 위해 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법
- 클러스터링 된 테이블은 데이터 조회 속도를 향상시키지만 입력, 수정, 삭제에 대한 작업 성능을 저하시킨다.
- 클러스터는 데이터의 분포도가 넓을수록 유리하다.
- 분포도, 선택성(Selectivity)
- (조건에 맞는 레코드 수 / 전체 릴레이션 레코드 수) × 100
- 전체 레코드 중 조건에 맞는 레코드의 숫자가 적은 경우 분포도가 좋다고 한다.
- 인덱스는 분포도가 좁은 테이블이 좋지만, 클러스터링은 분포도가 넓은 테이블에 유리하다.
- 분포도, 선택성(Selectivity)
- 데이터 분포도가 넓은 테이블을 클러스터링 하면 저장 공간을 절약할 수 있다.
- 처리 범위가 넓은 경우에는 단일 테이블 클러스터링을, 조인이 많이 발생하는 경우에는 다중 테이블 클러스터링을 사용한다.
- 단일 테이블 클러스터링은 여러 개의 테이블 뿐만 아니라 한 개의 테이블에 대해서도 클러스터링을 수행할 수 있다.
- 특정 컬럼의 동일한 값을 동일 블록이나 연속된 블록에 저장하므로 데이터 조회 성능이 향상된다.
- 단일 테이블 클러스터링은 여러 개의 테이블 뿐만 아니라 한 개의 테이블에 대해서도 클러스터링을 수행할 수 있다.
(22) 파티션
파티션(Partition)
- 데이터베이스에서 파티션은 대용량의 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것을 말한다.
- 대용량 DB의 경우 몇 개의 중요한 테이블에만 집중되어 데이터가 증가되므로, 이런 테이블들을 작은 단위로 나눠 분산시키면 성능 저하를 방지할 뿐만 아니라 데이터 관리도 쉬워진다.
- 데이터 처리는 테이블 단위로 이뤄지고, 데이터 저장은 파티션별로 수행된다.
- 하나의 테이블이 여러 개의 파티션으로 나눠져 있어도, DB에 접근하는 애플리케이션은 테이블 단위로 데이터를 처리하기 때문에 파티션을 인식하지 못한다.
파티션의 장·단점
| 장점 | 단점 |
| - 데이터 접근 시 액세스 범위를 줄여 쿼리 성능이 향상됨. - 파티션별로 데이터가 분산되어 저장되므로 디스크의 성능이 향상됨. - 파티션별로 백업 및 복구를 수행하므로 속도가 빠름. - 시스템 장애 시 데이터 손상 정도를 최소화할 수 있음. - 데이터 가용성이 향상됨. - 파티션 단위로 입출력을 분산시킬 수 있음. |
- 하나의 테이블을 세분화하여 관리하므로 세심한 관리가 요구됨. - 테이블간 조인에 대한 비용이 증가함. - 용량이 작은 테이블에 파티셔닝을 수행하면 오히려 성능이 저하됨. |
파티션의 종류
| 범위 분할 (Range Partitioning) |
- 지정한 열의 값을 기준으로 분할함. - 예) 일별, 월별, 분기별 등 |
| 해시 분할 (Hash Partitioning) |
- 해시 함수를 적용한 결과값에 따라 데이터를 분할함. - 특정 파티션에 데이터가 집중되는 범위 분할의 단점을 보완한 것으로, 데이터를 고르게 분산할 때 유용함. - 특정 데이터가 어디에 있는지 판단할 수 있음. - 고객번호, 주민번호 등과 같이 데이터가 고른 칼럼에 효과적임. |
| 조합 분할 (Composite Partitioning) |
- 범위 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 방식 - 범위 분할한 파티션이 너무 커서 관리가 어려울 때 유용함. |
(23) 분산 데이터베이스 설계
데이터베이스 용량 설계
- 데이터가 저장될 공간을 정의하는 것
- 데이터베이스 용량을 설계할 때는 테이블에 저장될 데이터양과 인덱스, 클러스터 등이 차지하는 공간 등을 예측하여 반영해야 한다.
- 데이터베이스 용량 설계의 목적
- 데이터베이스의 용량을 정확히 산정하여 디스크의 저장 공간을 효과적으로 사용하고 확장성 및 가용성을 높인다.
- 디스크의 특성을 고려하여 설계함으로써 디스크의 입출력 부하를 분산시키고 채널의 병목 현상을 최소화한다.
분산 데이터베이스 설계
- 분산 데이터베이스는 논리적으로는 하나의 시스템에 속하지만, 물리적으로는 네트워크를 통해 연결된 여러 개의 사이트(Site)에 분산된 데이터베이스를 말한다.
- 분산 데이터베이스는 데이터의 처리나 이용이 많은 지역에 데이터베이스를 위치시킴으로써 데이터의 처리가 가능한 해당 지역에서 해결될 수 있도록 한다.
- 분산 데이터베이스 설계는 애플리케이션이나 사용자가 분산되어 저장된 데이터에 접근하게 하는 것을 목적으로 한다.
분산 데이터베이스의 목표
- 위치 투명성(Location Transparency) : 액세스하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있다.
- 중복 투명성(Replication Transparency) : 동일 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행한다.
- 병행 투명성(Concurrency Transparency) : 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 그 트랜잭션의 결과는 영향을 받지 않는다.
- 장애 투명성(Failure Transparency) : 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리한다.
분산 설계 방법
| 방법 | 설명 |
| 테이블 위치 분산 | 데이터베이스의 테이블을 각기 다른 서버에 분산시켜 배치하는 방법 |
| 분할 (Fragmentation) |
- 테이블의 데이터를 분할하여 분산시키는 것 - 분할 규칙 : 완전성(Completeness), 재구성(Reconstruction), 상호 중첩 배제(Disjointness) - 주요 분할 방법 - 수평 분할 : 특정 속성의 값을 기준으로 행(Row) 단위로 분할 - 수직 분할 : 데이터 컬럼(속성) 단위로 분할 |
| 할당 (Allocation) |
- 동일한 분할을 여러 개의 서버에 생성하는 분산 방법 - 중복이 없는 할당과 중복이 있는 할당으로 나뉨. |
(24) 데이터베이스 이중화 / 서버 클러스터링
데이터베이스 이중화(Database Replication)
- 시스템 오류로 인한 데이터베이스 서비스 중단이나 물리적 손상 발생 시 이를 복구하기 위해 동일한 데이터베이스를 복제하여 관리하는 것
- 데이터베이스 이중화를 수행하면 하나 이상의 데이터베이스가 항상 같은 상태를 유지하므로 데이터베이스에 문제가 발생하면 복제된 데이터베이스를 이용하여 즉시 문제를 해결할 수 있다.
- 여러 개의 데이터베이스를 동시에 관리하므로 사용자가 수행하는 작업은 데이터베이스 이중화 시스템에 연결된 다른 데이터베이스에도 동일하게 적용된다.
- 애플리케이션을 여러 개의 데이터베이스에서 분산 처리하므로 데이터베이스의 부하를 줄일 수 있다.
- 데이터베이스 이중화를 이용하면 손쉽게 백업 서버를 운영할 수 있다.
데이터베이스 이중화의 분류
| Eager 기법 | 트랜잭션 수행 중 데이터 변경이 발생하면 이중화된 모든 데이터베이스에 즉시 전달하여 변경 내용이 즉시 적용되도록 하는 기법 |
| Lazy 기법 | - 트랜잭션의 수행이 종료되면 변경 사실을 새로운 트랜잭션에 작성하여 각 데이터베이스에 전달되는 기법 - 데이터베이스마다 새로운 트랜잭션이 수행되는 것으로 간주됨. |
데이터베이스 이중화 구성 방법
| 활동-대기(Active-Standby) 방법 | - 한 DB가 활성 상태로 서비스하고 있으면 다른 DB는 대기하고 있다가 활성 DB에 장애가 발생하면 대기 상태에 있던 DB가 자동으로 모든 서비스를 대신 수행함. - 구성 방법과 관리가 쉬워 많은 기업에서 이용됨. |
| 활동-활동(Active-Active) 방법 | - 두 개의 DB가 서로 다른 서비스를 제공하다가 둘 중 한쪽 DB에 문제가 발생하면 나머지 다른 DB가 서비스를 제공함. - 두 DB가 모두 처리를 하기 때문에 처리율이 높지만 구성 방법 및 설정이 복잡함. |
클러스터링(Clustering)
- 두 대 이상의 서버를 하나의 서버처럼 운영하는 기술
- 서버 이중화 및 공유 스토리지를 사용하여 서버의 고가용성을 제공한다.
- 공유 스토리지(NAS; Network Attached Storage) : 데이터 저장소를 네트워크로 연결하여 파일 및 데이터를 공유하는 것으로, 다수의 사용자 또는 서버가 데이터를 안전하고 편리하게 공유할 수 있다.
- 고가용성(HA, High Availability) : 시스템을 오랜 시간동안 계속해서 정상적으로 운영이 가능한 성질
- 클러스터링 종류
| 고가용성 클러스터링 | - 하나의 서버에 장애가 발생하면 다른 노드(서버)가 받아 처리하여 서비스 중단을 방지하는 방식 - 일반적으로 언급되는 클러스터링이 고가용성 클러스터링임. |
| 병렬 처리 클러스터링 | 전체 처리율을 높이기 위해 하나의 작업을 여러 개의 서버에서 분산하여 처리하는 방식 |
RTO/PRO
| RTO (Recovery Time Objective, 목표 복구 시간) |
- 비상사태 또는 업무 중단 시점으로부터 복구되어 가동될 때까지의 소요 시간 - 예) 장애 발생 후 6시간 내 복구 가능 |
| RPO (Recovery Point Objective, 목표 복구 시점) |
- 비상사태 또는 업무 중단 시점으로부터 데이터를 복구할 수 있는 기준점 - 예) 장애 발생 전인 지난 주 금요일에 백업시켜 둔 복원 시점으로 복구 가능 |
(25) 데이터베이스 보안
데이터베이스 보안
- 데이터베이스의 일부 또는 전체에 대해서 권한이 없는 사용자가 액세스하는 것을 금지하기 위해 사용되는 기술
- 보안을 위한 데이터 단위는 테이블 전체로부터 특정 테이블의 특정 행과 열에 있는 데이터 값에 이르기까지 다양하다.
암호화(Encryption)
- 데이터를 보낼 때 송신자가 지정한 수신자 이외에는 그 내용을 알 수 없도록 평문을 암호문으로 변환하는 것
- 암호화(Encryption) 과정 : 암호화되지 않은 평문을 암호문으로 바꾸는 과정
- 복호화(Decryption) 과정 : 암호문을 원래의 평문으로 바꾸는 과정
- 암호화 기법
- 개인키 암호화 방식(Private Key Encryption)
- 공개키 암호화 방식(Public Key Encryption)
접근 통제
- 데이터가 저장된 객체와 이를 사용하는 주체 사이의 정보 흐름을 제한하는 것
- 접근통제 3요소
- 접근통제 정책
- 접근통제 매커니즘
- 접근통제 보안모델
- 접근통제 기술
| 정책 | 특징 |
| 임의 접근통제 (DAC, Discretionary Access Control) |
- 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식 - 데이터 소유자가 접근통제 권한을 지정하고 제어함. - 객체를 생성한 사용자가 생성된 객체에 대한 모든 권한을 부여받고, 부여된 권한을 다른 사용자에게 허가할 수도 있음. |
| 강제 접근통제 (MAC, Mandatory Access Control) |
- 주체와 객체의 등급을 비교하여 접근 권한을 부여하는 방식 - 시스템이 접근통제 권한을 지정함. - 데이터베이스 객체별로 보안 등급을 부여할 수 있음. - 사용자별로 인가 등급을 부여할 수 있음. |
| 역할기반 접근통제 (RBAC, Role Based Access Control) |
- 사용자의 역할에 따라 접근 권한을 부여하는 방식 - 중앙관리자가 접근통제 권한을 지정함. - 임의 접근통제와 강제 접근통제의 단점을 보완하였음. - 다중 프로그래밍 환경에 최적화된 방식 |
접근통제 정책
- 어떤 주체가(Who) 언제(When), 어디서(Where), 어떤 객체(What)에게, 어떤 행위(How)에 대한 허용 여부를 정의하는 것
- 접근통제 정책의 종류
| 종류 | 특징 |
| 신분 기반 정책 | - 주체나 그룹의 신분에 근거하여 객체의 접근을 제한하는 방법으로, IBP와 GBP가 있음. - IBP(Individual-Based Policy) : 최소 권한 정책으로, 단일 주체에게 하나의 객체에 대한 허가를 부여함. - GBP(Group-Based Policy) : 복수 주체에 하나의 객체에 대한 허가를 부여함. |
| 규칙 기반 정책 | - 주체가 갖는 권한에 근거하여 객체의 접근을 제한하는 방법으로, MLP와 CBP가 있음. - MLP(Multi-Level Policy) : 사용자나 객체별로 지정된 기밀 분류에 따른 정책 - CBP(Compartment-Based Policy) : 집단별로 지정된 기밀 허가에 따른 정책 |
| 역할 기반 정책 | GBP의 변형된 정책으로, 주체의 신분이 아니라 주체가 맡은 역할에 근거하여 객체의 접근을 제한하는 방법 |
접근통제 매커니즘
- 정의된 접근통제 정책을 구현하는 기술적인 방법
- 접근통제 매커니즘에는 접근통제 목록, 능력 리스트, 보안 등급, 패스워드, 암호화 등이 있다.
- 접근통제 목록(Access Control List) : 객체를 기준으로 특정 객체에 대해 어떤 주체가 어떤 행위를 할 수 있는지를 기록한 목록
- 능력 리스트(Capability List) : 주체를 기준으로 주체에게 허가된 자원 및 권한을 기록한 목록
접근통제 보안 모델
- 보안 정책을 위한 정형화된 모델
- 접근통제 보안 모델의 종류
| 종류 | 특징 |
| 기밀성 모델 | - 군사적인 목적으로 개발된 최초의 수학적 모델 - 기밀성 보장이 최우선임. - 군대 시스템 등 특수 환경에 주로 사용됨. |
| 무결성 모델 | 기밀성 모델에서 발생하는 불법적인 정보 변경을 방지하기 위해 무결성을 기반으로 개발된 모델 |
| 접근통제 모델 | - 접근통제 메커니즘을 보안 모델로 발전시킨 것 - 대표적으로 접근통제 행렬(Access Control Matrix)이 있음. - 접근통제 행렬 : 임의적인 접근통제를 관리하기 위한 보안 모델로, 행은 주체, 열은 객체 즉, 행과 열로 주체와 객체의 권한 유형을 나타냄. |
접근통제 조건
- 접근통제 메커니즘의 취약점을 보완하기 위해 접근통제 정책에 부가하여 적용할 수 있는 조건
| 조건 | 특징 |
| 값 종속 통제 (Value-Dependent Control) |
일반적으로는 객체에 저장된 값에 상관없이 접근통제를 동일하게 허용하지만, 값 종속 통제는 객체에 저장된 값에 따라 다르게 접근통제를 허용해야 하는 경우에 사용한다. |
| 다중 사용자 통제 (Multi-User Control) |
지정된 객체에 다수의 사용자가 동시에 접근을 요구하는 경우에 사용된다. |
| 컨텍스트 기반 통제 (Context-Based Control) |
- 특정 시간, 네트워크 주소, 접근 경로, 인증 수준 등에 근거하여 접근을 제어하는 방법이다. - 다른 보안 정책과 결합하여 보안 시스템의 취약점을 보완할 때 사용한다. |
감사 추적
- 사용자나 애플리케이션이 데이터베이스에 접근하여 수행한 모든 활동을 기록하는 기능
- 오류가 발생한 데이터베이스를 복구하거나, 부적절한 데이터 조작을 파악하기 위해 사용된다.
(26) 데이터베이스 백업
데이터베이스 백업
- 전산 장비의 장애에 대비하여 데이터베이스에 저장된 데이터를 보호하고 복구하기 위한 작업
- 치명적인 데이터 손실을 막기 위해서는 데이터베이스를 정기적으로 백업해야 한다.
로그 파일
- 데이터베이스의 처리 내용이나 이용 상황 등 상태 변화를 시간의 흐름에 따라 모두 기록한 파일
- 데이터베이스의 복구를 위해 필요한 가장 기본적인 자료
- 로그 파일을 기반으로 데이터베이스를 과거 상태로 복귀(UNDO)시키거나 현재 상태로 재생(REDO)시켜 데이터베이스 상태를 일관성 있게 유지할 수 있다.
- 로그 파일은 트랜잭션 시작 시점, Rollback 시점, 데이터 입력, 수정 삭제 시점 등에서 기록된다.
데이터베이스 복구 알고리즘
| NO-UNDO / REDO | - 데이터베이스 버퍼의 내용을 비동기적으로 갱신한 경우의 복구 알고리즘 - NO-UNDO : 트랜잭션 완료 전에는 변경 내용이 데이터베이스에 기록되지 않으므로 취소할 필요가 없음. - REDO : 트랜잭션 완료 후 데이터베이스 버퍼에는 기록되어 있고, 저장매체에는 기록되지 않았으므로 트랜잭션 내용을 다시 실행해야 함. |
| UNDO / NO-REDO | - 데이터베이스 버퍼의 내용을 동기적으로 갱신한 경우의 복구 알고리즘 - UNDO : 트랜잭션 완료 전에 시스템이 파손되었다면 변경된 내용을 취소함. - NO-REDO : 트랜잭션 완료 전에 데이터베이스 버퍼 내용을 이미 저장 매체에 기록했으므로 트랜잭션 내용을 다시 실행할 필요가 없음. |
| UNDO / REDO | - 데이터베이스 버퍼의 내용을 동기/비동기적으로 갱신한 경우의 복구 알고리즘 - 데이터베이스 기록 전에 트랜잭션이 완료될 수 있으므로, 완료된 트랜잭션이 데이터베이스에 기록되지 못했다면 다시 실행해야 함. |
| NO-UNDO / NO-REDO | - 데이터베이스 버퍼의 내용을 동기적으로 저장 매체에 기록하지만, 데이터베이스와는 다른 영역에 기록한 경우의 복구 알고리즘 - NO-UNDO : 변경 내용은 데이터베이스와 다른 영역에 기록되어 있으므로 취소할 필요가 없음. - NO-REDO : 다른 영역에 이미 기록되어 있으므로 트랜잭션을 다시 실행할 필요가 없음. |
백업 종류
- 복구 수준에 따라서 운영체제를 이용하는 물리 백업과 DBMS 유틸리티를 이용하는 논리 백업으로 나뉜다.
| 물리 백업 | - 데이터베이스 파일을 백업하는 방법 - 백업 속도가 빠르고 작업이 단순하지만, 문제 발생 시 원인 파악 및 문제 해결이 어렵다. |
| 논리 백업 | - DB 내의 논리적 객체들을 백업하는 방법 - 복원 시 데이터 손상을 막고 문제 발생 시 원인 파악 및 해결이 수월하지만, 백업/복원 시 시간이 많이 소요된다. |
(27) 스토리지
스토리지(Storage)
- 단일 디스크로 처리할 수 없는 대용량의 데이터를 저장하기 위해 서버와 저장장치를 연결하는 기술
- 스토리지의 종류에는 DAS, NAS, SAN 이 있다.
DAS(Direct Attached Storage)
- 서버와 저장장치를 전용 케이블로 직접 연결하는 방식
- 일반 가정에서 컴퓨터에 외장하드를 연결하는 것이 여기에 해당된다.
- 저장장치를 직접 연결하므로 속도가 빠르고 설치 및 운영이 쉽다.
- 초기 구축 비용 및 유지보수 비용이 저렴하다.
- 직접 연결 방식이므로 다른 서버에서 접근할 수 없고, 파일을 공유할 수 없다.
- 확장성 및 유연성이 떨어진다.
NAS(Network Attached Storage)
- 서버와 저장장치를 네트워크를 통해 연결하는 방식
- 별도의 파일 관리 기능이 있는 NAS Storage가 내장된 저장장치를 직접 관리한다.
- Ethernet 스위치를 통해 다른 서버에서도 스토리지에 접근할 수 있어 파일 공유가 가능하다.
- 장소에 구애받지 않고 저장장치에 쉽게 접근할 수 있다.
- DAS에 비해 확장성 및 유연성이 우수하다.
SAN(Storage Area Network)
- DAS의 빠른 처리와 NAS의 파일 공유 장점을 혼합한 방식으로, 서버와 저장장치를 연결하는 전용 네트워크를 별도로 구성하는 방식
- 파이버 채널(FC) 스위치를 이용하여 네트워크를 구성한다.
- 파이버 채널 스위치는 서버와 저장장치를 광케이블로 연결하므로 처리 속도가 빠르다.
- 서버들이 저장장치 및 파일을 공유할 수 있다.
- 확장성, 유연성, 가용성이 뛰어나다.
(28) 논리 데이터 모델의 변환
엔티티(Entity)를 테이블로 변환
- 논리 데이터 모델에서 정의된 엔티티를 물리 데이터 모델의 테이블로 변환하는 것
- 변환 규칙
| 논리적 설계(데이터 모델링) | 물리적 설계 |
| 엔티티(Entity) | 테이블(Table) |
| 속성(Attribute) | 칼럼(Column) |
| 주 식별자(Primary Identifier) | 기본키(Primary Key) |
| 외부 식별자(Foreign Identifier) | 외래키(Foreign Key) |
| 관계(Relationship) | 관계(Relationship) |
슈퍼타입/서브타입을 테이블로 변환
- 슈퍼타입/서브타입은 논리 데이터 모델에서 이용되는 형태이므로 물리 데이터 모델을 설계할 때는 슈퍼타입/서브타입을 테이블로 변환해야 한다.
- 슈퍼타입/서브타입 모델을 테이블로 변환하는 방법
- 슈퍼타입 기준 테이블 변환
- 서브타입 기준 테이블 변환
- 개별타입 기준 테이블 변환
슈퍼타입 기준 테이블 변환
- 서브타입을 슈퍼타입에 통합하여 하나의 테이블로 만드는 것
- 서브타입에 속성이나 관계가 적을 경우에 적용하는 방법
- 하나로 통합된 테이블에는 서브타입의 모든 속성이 포함되어야 한다.
예
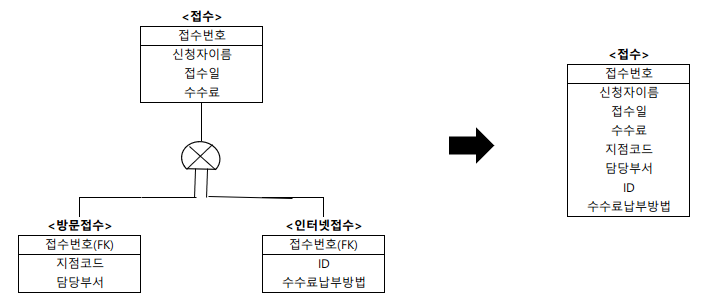
서브타입의 <방문접수> 개체에 있는 '지점코드', '담당부서'와 <인터넷접수> 개체에 있는 'ID', '수수료납부방법'이 슈퍼타입인 <접수> 개체에 통합되어 <접수> 테이블로 변환된다.
서브타입 기준 테이블 변환
- 슈퍼타입 속성들을 각각의 서브타입에 추가하여 서브타입들을 개별적인 테이블로 만드는 것
- 서브타입에 속성이나 관계가 많이 포함된 경우 적용한다.
예
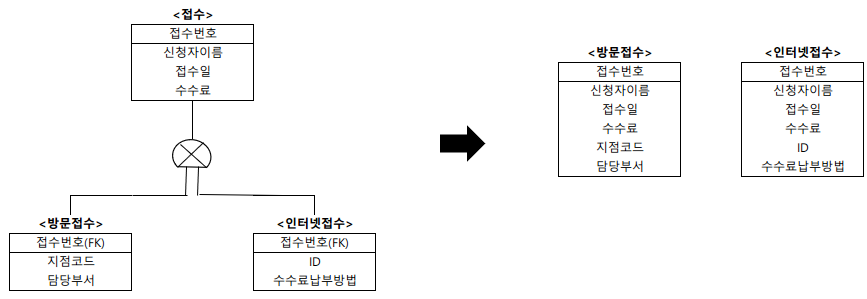
슈퍼타입인 <접수> 개체에 있는 '신청자이름', '접수일', '수수료'가 서브타입인 <방문접수> 개체와 <인터넷접수> 개체에 각각 추가되어 <방문접수>와 <인터넷접수> 테이블로 변환된다.
개별타입 기준 테이블 변환
- 슈퍼타입과 서브타입들을 각각의 개별적인 테이블로 변환하는 것
- 슈퍼타입과 서브타입 테이블들 사이에는 각각 1:1 관계가 형성된다.
예
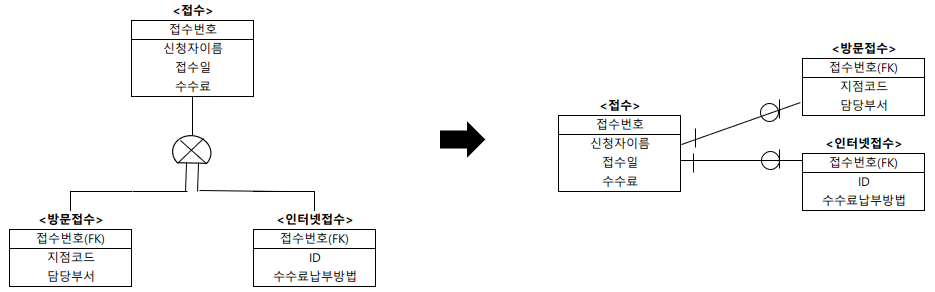
슈퍼타입의 <접수> 개체와 서브타입의 <방문접수>, <인터넷접수> 개체가 각각 <접수>, <방문접수>, <인터넷접수> 테이블로 변환된다.
속성을 칼럼으로 변환
- 논리 데이터 모델에서 정의한 속성을 물리 데이터 모델의 컬럼으로 변환한다.
| 일반 속성 변환 | 속성과 컬럼은 명칭이 반드시 일치할 필요는 없으나, 개발자와 사용자 간 의사소통을 위하여 가능한 한 표준화된 약어를 사용하여 일치시키는 것이 좋음. |
| Primary UID를 기본키로 변환 | 논리 데이터 모델에서의 Primary UID는 물리 데이터 모델의 기본키로 만듦. |
| Primary UID(관계의 UID Bar)를 기본키로 변환 | 다른 엔티티와의 관계로 인해 생성된 Primary UID는 물리 데이터 모델의 기본키로 만듦. |
| Secondary(Alternate) UID를 유니크키로 변환 | 논리 모델링에서 정의된 Secondary UID 및 Alternate Key는 물리 모델에서 유니크키로 만듦. |
예 : 일반 속성 변환
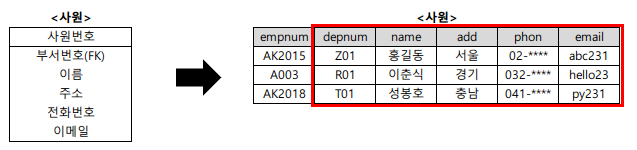
<사원> 엔티티의 '부서번호', '이름', '주소', '전화번호', '이메일' 속성이 <사원> 테이블의 각각의 컬럼으로 변환되었으며, 예시를 위한 데이터가 들어있다.
관계를 외래키로 변환
- 논리 데이터 모델에서 정의된 관계는 기본키와 이를 참조하는 외래키로 변환한다.
(29) 물리 데이터 모델 품질 검토
물리 데이터 모델 품질 검토
- 물리 데이터 모델을 설계하고 데이터베이스 객체를 생성한 후, 개발 단계로 넘어가기 전에 모델러와 이해관계자들이 모여 수행한다.
- 물리 데이터 모델 품질 검토의 목적은 데이터베이스의 성능 향상과 오류 예방이다.
- 물리 데이터 모델을 검토하려면 모든 이해관계자가 동의하는 검토 기준이 필요하다.
물리 데이터 모델 품질 기준
| 정확성 | 데이터 모델이 요구사항이나 업무 규칙, 표기법에 따라 정확하게 표현되었음. |
| 완전성 | 데이터 모델이 데이터 모델의 구성 요소를 누락 없이 정의하고 요구사항이나 업무 영역을 누락 없이 반영하였음. |
| 준거성 | 데이터 모델이 데이터 표준, 표준화 규칙, 법적 요건 등을 정확하게 준수하였음. |
| 최신성 | 데이터 모델이 최근의 이슈나 현행 시스템을 반영하고 있음. |
| 일관성 | 데이터 모델의 표현상의 일관성을 유지하고 있음. |
| 활용성 | 작성된 모델과 설명을 사용자가 충분히 이해할 수 있고, 업무 변화에 따른 데이터 구조의 변경이 최소화될 수 있도록 설계되었음. |
물리 데이터 모델 품질 검토 항목
- 물리 데이터 모델의 특성을 반영한 품질 기준을 작성한 후, 이를 기반으로 작성한다.
- 물리 데이터 모델에 정의된 테이블, 컬럼, 무결성 제약 조건 등 물리 데이터 모델의 주요 구성 요소와 반정규화, 인덱스, 스토리지 등 물리 데이터 모델의 전반적인 것을 검토 항목으로 작성한다.
(30) 자료 구조
자료 구조
- 자료를 기억장치의 공간 내에 저장하는 방법과 자료 간의 관계, 처리 방법 등을 연구 분석하는 것
- 저장 공간의 효율성과 실행시간의 단축을 위해 사용한다.
- 자료 구조의 분류
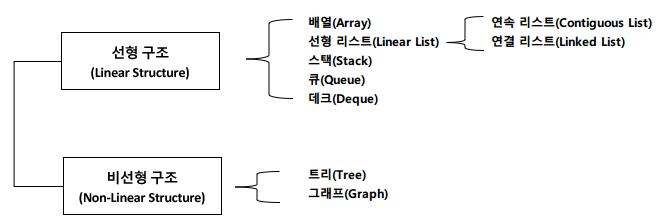
배열(Array)
- 크기와 형(Type)이 동일한 자료들이 순서대로 나열된 자료의 집합
- 반복적인 데이터 처리 작업에 적합한 구조이다.
- 정적인 자료 구조로, 기억장소의 추가가 어렵다.
- 데이터 삭제 시 기억장소가 빈 공간으로 남아 있어 메모리의 낭비가 발생한다.
연속 리스트(Contiguous List)
- 배열과 같이 연속되는 기억장소에 저장되는 자료 구조
- 중간에 데이터를 삽입하기 위해서는 연속된 빈 공간이 있어야 한다.f
- 삽입·삭제 시 자료의 이동이 필요하다.
연결 리스트(Linked List)
- 자료들을 임의의 기억공간에 기억시키되, 자료 항목의 순서에 따라 노드의 포인터 부분을 이용하여 서로 연결시킨 자료 구조
- 연결을 위한 링크(포인터) 부분이 필요하기 때문에 기억 공간의 이용 효율이 좋지 않다.
- 접근 속도가 느리고, 연결이 끊어지면 다음 노드를 찾기 어렵다.
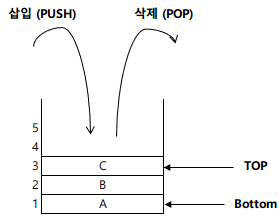
스택(Stack)
- 리스트의 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료 구조
- 후입선출(LIFO; Last In First Out) 방식으로 자료를 처리한다.
- 저장할 기억 공간이 없는 상태에서 데이터가 삽입되면 오버플로(Overflow)가 발생한다.
- 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더플로(Underflow)가 발생한다.
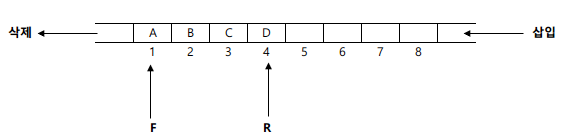
큐(Queue)
- 리스트의 한쪽에는 삽입 작업이 이루어지고, 다른 한쪽에서는 삭제 작업이 이루어지는 자료 구조
- 선입선출(FIFO; First In First out) 방식으로 처리한다.
- 시작을 표시하는 프런트(Front) 포인터와 끝을 표시하는 리어(Rear) 포인터가 있다.
그래프(Graph)
- 정점(Vertex)과 간선(Edge)의 두 집합으로 이루어지는 자료 구조
- 사이클이 없는 그래프(Graph)를 트리(Tree)라 한다.
- 간선의 방향성 유무에 따라 방향 그래프와 무방향 그래프로 구분된다.
방향/무방향 그래프의 최대 간선 수
- 방향 그래프의 최대 간선 수 : n(n-1)
- 무방향 그래프에서 최대 간선 수 : n(n-1)/2
※ n : 정점의 개수
예 : 정점이 4개인 경우, 무방향 그래프와 방향 그래프의 최대 간선 수를 구하시오.
- 무방향 그래프의 최대 간선 수 : 4(4-1)/2 = 6
- 방향 그래프의 최대 간선 수 : 4(4-1) = 12
(31) 트리(Tree)
트리
- 정점(Node, 노드)과 선분(Branch, 가지)를 이용하여 사이클을 이루지 않도록 구성한 그래프(Graph)의 특수한 형태
- 트리는 하나의 기억 공간을 노드(Node)라고 하며, 노드와 노드를 연결하는 선을 링크(Link)라고 한다.
트리 관련 용어
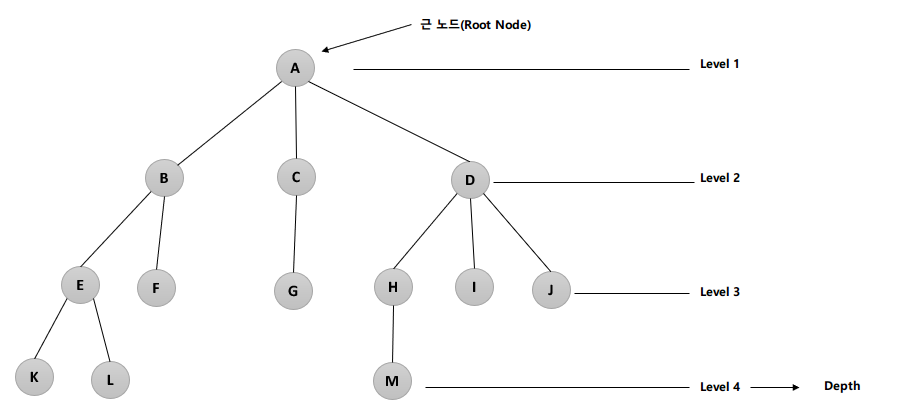
- 노드(Node) : 트리의 기본 요소로서 자료 항목과 다른 항목에 대한 가지(Branch)를 합친 것
- 예) A, B, C, D, E, F, G, H, I, J, K, L, M
- 근 노드(Root Node) : 트리의 맨 위에 있는 노드
- 예) A
- 디그리(Degree, 차수) : 각 노드에서 뻗어나온 가지 수
- 예) A=3, B=2, C=1, D=3
- 단말 노드(Terminal Node) = 잎 노드(Leaf Node) : 자식이 하나도 없는 노드, 즉 Degree가 0인 노드
- 예) K, L, F, G, M, I, J
- 비단말 노드(Non-Terminal Node) : 자식이 하나라도 있는 노드, 즉 Degree가 0이 아닌 노드
- 예) A, B, C, D, E, H
- 조상 노드(Ancestors Node) : 임의의 노드에서 근 노드에 이르는 경로상에 있는 노드들
- 예) M의 조상 노드는 H, D, A
- 자식 노드(Son Node) : 어떤 노드에 연결된 다음 레벨의 노드들
- 예) D의 자식 노드 : H, I, J
- 부모 노드(Parent Node) : 어떤 노드에 연결된 이전 레벨의 노드들
- 예) E, F의 부모 노드는 B
- 형제 노드(Brother Node, Sibling) : 동일한 부모를 갖는 노드들
- 예) H의 형제 노드는 I, J
- Level : 근 노드의 Level을 1로 가정한 후, 어떤 Level이 L이면 자식 노드는 L+1
- 예) H의 레벨은 3
- 깊이(Depth, Height) : 트리에서 노드가 가질 수 있는 최대의 레벨
- 예) 위 트리의 깊이는 4
- 숲(Forest) : 여러 개의 트리가 모여 있는 것
- 예) 위 트리에서 근 노드 A를 제거하면 B, C, D를 근 노드로 하는 3개의 트리가 있는 숲이 생긴다.
- 트리의 디그리 : 노드들의 디그리 중에서 가장 많은 수
- 예) 노드 A나 D가 3개의 디그리를 가지므로 위 트리의 디그리는 3이다.
(32) 이진 트리(Tree)
이진 트리
- 차수(Degree)가 2 이하인 노드들로 구성된 트리, 즉 자식이 둘 이하인 노드들로만 구성된 트리
- 이진 트리의 레벨 $i$에서 최대 노드의 수는 $2^{i - 1}$ 이다.
- 이진 트리에서 단말 노드 수가 $n_{0}$ , 차수가 2인 노드 수가 $n_{2}$ 라 할 때, $n_{0} = n_{2} + 1$ 이 된다.
예
 |
- 레벨3에서 최대 노드의 수는 $2^{3-1} = 4$ 이다. - 단말 노드의 개수가 4개이고, 차수가 2인 노드가 3개이므로 $4 = 3 + 1$에 의해 $n_{0} = n_{2} + 1$ 가 성립된다. |
트리의 운행법
- 트리를 구성하는 각 노드들을 찾아가는 방법을 운행법(Traversal)이라 한다.
- 이진 트리를 운행하는 방법은 산술식의 표기법과 연관성을 갖는다.
- 이진 트리의 운행법은 다음 3가지가 있다.
- 이진 트리 운행법의 이름은 Root의 위치가 어디 있느냐에 따라 정해진 것이다.
- Root가 앞(Pre)에 있으면 Preorder, 안(In)에 있으면 Inorder, 뒤(Post)에 있으면 Postorder
- 이진 트리 운행법의 이름은 Root의 위치가 어디 있느냐에 따라 정해진 것이다.
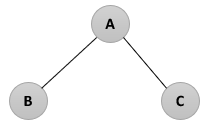 |
- Preorder 운형 : Root → Left → Right 순으로 운행한다. (A, B, C) - Inorder 운행 : Left → Root → Right 순으로 운행한다. (B, A, C) - Postorder 운행 : Left → Right → Root 순으로 운행한다. (B, C, A) |
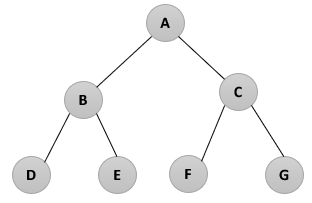
Preorder 운행법
- 이진 트리를 Root → Left → Right 순으로 운행하며 노드들을 찾아가는 방법
예
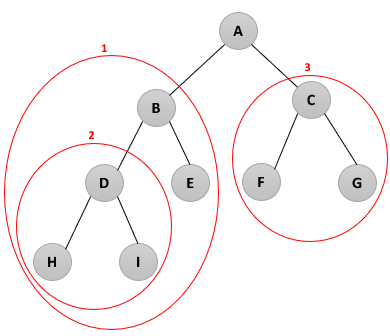 |
- 방문 순서 : ABDHIECFG |
Inorder 운행법
- 이진 트리를 Left → Root → Right 순으로 운행하며 노드들을 찾아가는 방법
예
|
- 방문 순서 : HDIBEAFCG |
Postorder 운행법
- 이진 트리를 Left → Right → Root 순으로 운행하며 노드들을 찾아가는 방법
예
|
- 방문 순서 : HIDEBFGCA |
수식의 표기법
- 이진 트리로 만들어진 수식을 인오더, 프리오더, 포스트오더로 운행하면 각각 중위(Infix), 전위(Prefix), 후위(Postfix) 표기법이 된다.
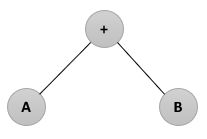 |
- 전위 표기법(PreFix) : 연산자→ Left→ Right 순으로 운행한다. (+AB) - 중위 표기법(InFix) : Left → 연산자→ Right 순으로 운행한다. (A+B) - 후위 표기법(PostFix) : Left → Right → 연산자 순으로 운행한다. (AB+) |
InfIx 표기를 Postfix나 Prefix로 바꾸기
- Postfix나 Prefix는 스택을 이용하여 처리하므로, Infix는 Postfix나 Prefix로 바꾸어 처리한다.
예제 1 : 다음과 같이 Infix로 표기된 수식을 Prefix와 Postfix로 변환하시오.
| X = A / B * (C + D) + E |
- Prefix로 변환하기
- ① 연산자 우선순위에 따라 괄호로 묶는다.
- ( X = ( ( (A / B) * (C + D) ) + E ) )
- ② 연산자를 해당 괄호의 앞(왼쪽)으로 옮긴다.
- = ( X + ( * ( / (AB) + (CD) ) E) )
- ③ 필요없는 괄호를 제거한다.
- = X + * / A B + C D E
- ① 연산자 우선순위에 따라 괄호로 묶는다.
- Postfix로 변환하기
- ① 연산자 우선순위에 따라 괄호로 묶는다.
- ( X = ( ( (A / B) * (C + D) ) + E ) )
- ② 연산자를 해당 괄호의 뒤(오른쪽)으로 옮긴다.
- ( X ( ( (A B) / (C D) + ) * E ) + ) =
- ③ 필요없는 괄호를 제거한다.
- X A B / C D + * E + =
- ① 연산자 우선순위에 따라 괄호로 묶는다.
Postfix나 Prefix로 표기된 수식을 Infix로 바꾸기
예제 2 : 다음과 같이 Postfix로 표기된 수식을 Infix로 변환하시오.
| A B C - / D E F + * + |
- Postfix는 Infix 표기법에서 연산자를 해당 피연산자 2개의 뒤로 이동한 것이므로, 연산자를 다시 해당 피연산자 2개의 가운데로 옮기면 된다.
- ① 먼저 인접한 피연산자 2개와 오른쪽의 연산자를 괄호로 묶는다.
- ( (A (B C -) /) (D (E F +) *) + )
- ② 연산자를 해당 연산자의 가운데로 이동시킨다.
- ((A / (B - C)) + (D * (E + F)))
- ③ 필요 없는 괄호를 제거한다.
- A / (B - C) + D * (E + F)
- ① 먼저 인접한 피연산자 2개와 오른쪽의 연산자를 괄호로 묶는다.
예제 3 : 다음과 같이 Prefix로 표기된 수식을 Infix로 변환하시오.
| + / A - B C * D + E F |
- Prefix는 Infix 표기법에서 연산자를 해당 피연산자 2개의 앞으로 이동한 것이므로, 연산자를 다시 해당 피연산자 2개의 가운데로 옮기면 된다.
- ① 먼저 인접한 피연산자 2개와 왼쪽의 연산자를 괄호로 묶는다.
- (+ (/ A(- B C) ) (* D (+ E F) ) )
- ② 연산자를 해당 피연산자 사이로 이동시킨다.
- ((A / (B - C)) + (D * (E + F)))
- ③ 필요 없는 괄호를 제거한다.
- A / (B - C) + D * (E + F)
- ① 먼저 인접한 피연산자 2개와 왼쪽의 연산자를 괄호로 묶는다.
(33) 정렬(Sort)
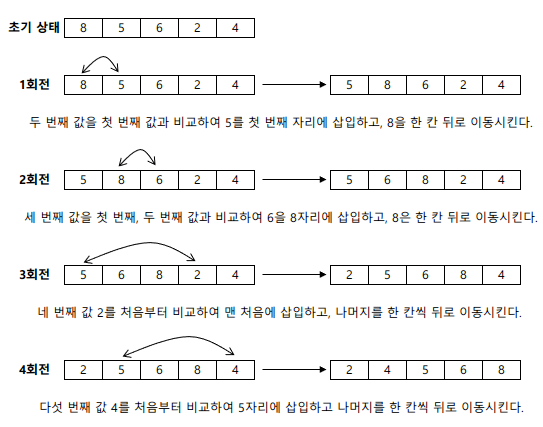
삽입 정렬(Insertion Sort)
- 가장 간단한 정렬 방식으로, 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방식
- 평균과 최악 모두 수행 시간 복잡도는 $O(n^{2})$ 이다.
예제 : 8, 5, 6, 2, 4 를 삽입 정렬로 정렬하시오.
선택 정렬(Selection Sort)
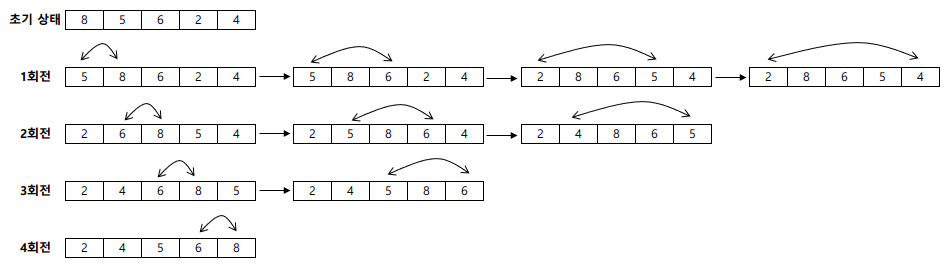
- n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식
- 평균과 최악 모두 수행 시간 복잡도는 $O(n^{2})$ 이다.
예제 : 8, 5, 6, 2, 4 를 선택 정렬로 정렬하시오.
버블 정렬(Bubble Sort)
- 주어진 파일에서 인접한 2개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식
- 평균과 최악 모두 수행 시간 복잡도는 $O(n^{2})$ 이다.
예제 : 8, 5, 6, 2, 4 를 버블 정렬로 정렬하시오.
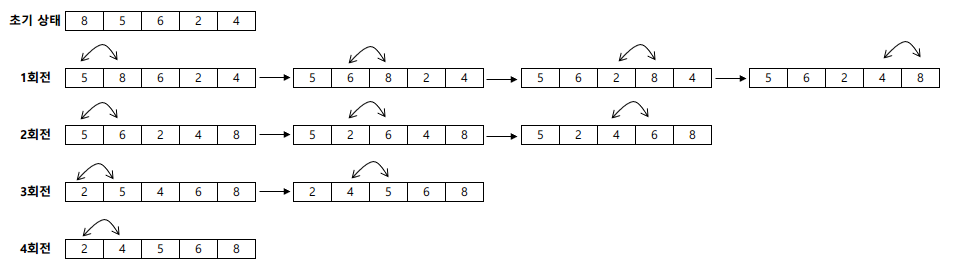
쉘 정렬(Shell Sort)
- 입력 파일을 어떤 매개변수의 값으로 서브 파일을 구성하고, 각 서브 파일을 삽입(Insertion) 정렬 방식으로 순서 배열하는 과정을 반복하는 정렬 방식
- 삽입 정렬(Insertion Sort)을 확장한 개념
- 평균 수행 시간 복잡도는 $O(n^{1.5})$ 이고, 최악의 수행 시간 복잡도는 $O(n^{2})$ 이다.
퀵 정렬(Quick Sort)
- 키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해시키는 과정을 반복하는 정렬 방식
- 코드의 많은 자료 이동을 없애고, 하나의 파일을 부분적으로 나누어 가면서 정렬한다.
- 평균 수행 시간 복잡도는 $O(nlog_{2}n)$ 이고, 최악의 수행 시간 복잡도는 $O(n^{2})$ 이다.
힙 정렬(Heap Sort)
- 전이진 트리를 이용한 정렬 방식
- 구성된 전이진 트리(Complete Binary Tree)를 힙 트리(Heap Tree)로 변환하여 정렬한다.
- 평균과 최악 모두 수행 시간 복잡도는 $O(nlog_{2}n)$ 이다.
2-Way 합병 정렬(Merge Sort)
- 이미 정렬되어 있는 2개의 파일을 1개의 파일로 합병하는 정렬 방식
- 평균과 최악 모두 수행 시간 복잡도는 $O(nlog_{2}n)$ 이다.
기수 정렬(Radix Sort) = 버킷 정렬(Bucket Sort)
- 큐(Queue)를 이용하여 자릿수(Digit)별로 정렬하는 방식
- 레코드의 키 값을 분석하여 같은 수 또는 같은 문자끼리 그 순서에 맞는 버킷에 분배하였다가 버킷의 순서대로 레코드를 꺼내어 정렬한다.
- 평균과 최악 모두 수행 시간 복잡도는 $O(dn)$ 이다.
'Certificate > DPE' 카테고리의 다른 글
| [정보처리기사 실기] 06. 화면 설계 (0) | 2022.02.28 |
|---|---|
| [정보처리기사 실기] 05. 인터페이스 구현 (0) | 2022.02.27 |
| [정보처리기사 실기] 04. 서버 프로그램 구현 (0) | 2022.02.27 |
| [정보처리기사 실기] 03. 통합 구현 (0) | 2022.02.26 |
| [정보처리기사 실기] 01. 요구사항 확인 (5) | 2022.01.23 |
| [정보처리기사 실기] 시험 개요 (1) | 2022.01.11 |
| 소프트웨어 개발방법론 (0) | 2021.09.15 |
| 기억 클래스(Storage Class) (0) | 2021.07.29 |

