Q. 다음 중 데이터베이스 연결(Conneection)과 관련된 설명으로 가장 부적절한 것은?
① 데이터베이스 서버와 클라이언트 간 연결 상태를 유지하면 서버 자원을 낭비하게 되므로 동시 사용자가 많은 OLTP 환경에서는 SQL 수행을 마치자마자 곧바로 연결(Connection)을 닫아주는 것이 바람직하다. ② 연결(Connection) 요청에 대한 부하는 쓰레드(Thread) 기반 아키텍처 보다 프로세스 기반 아키텍처에서 더 심하게 발생한다. ③ 전용 서버(Dedicated Server) 방식으로 오라클 데이터베이스에 접속하면 사용자가 데이터베이스 서버에 연결 요청을 할 때마다 서버 프로세스(또는 쓰레드)가 생성된다. ④ 공유 서버(Shared Server) 방식으로 오라클 데이터베이스에 접속하면 사용자 프로세스는 서버 프로세스와 직접 통신하지 않고 Dispatcher 프로세스를 거친다.
해설 :다중 사용자 환경에서 서버와 모든 클라이언트 간 연결 상태를 지속하면 서버 자원을 낭비하게 된다. 그렇다고 SQL을 수행할 때마다 연결 요청을 반복하면 서버 프로세스(또는 쓰레드)의 생성과 해제도 반복하므로 성능에 좋지 않다. 따라서 OLTP성 애플리케이션에선 Connection Pooling 기법의 활용이 필수적이다.
※클라이언트가 서버 프로세스와 연결하는 Oracle의 예
1) 전용 서버(Dedicated Server) 방식
2) 공유 서버(Shared Server) 방식
문제 2
Q. 다음 중 Oracle이나 SQL Server 같은 데이터베이스의 저장 구조를 설명한 것으로 가장 부적절한 것은?
① 데이터를 읽고 쓰는 단위는 블록(=페이지)이다. ② 데이터 파일에 공간을 할당하는 단위는 익스텐트다. ③ 같은 세그먼트(테이블, 인덱스)에 속한 익스텐트끼리는 데이터 파일 내에서 서로 인접해 있다. ④ SQL Server에서는 한 익스텐트에 속한 페이지들을 여러 오브젝트가 나누어 사용할 수 있다.
※ SQL Server에서 세그먼트는 테이블, 인덱스, Undo 처럼 저장 공간을 필요로 하는 데이터베이스 오브젝트다. 저장 공간을 필요로 한다는 것은 한 개 이상의 익스텐트를 사용함을 뜻한다. SQL Server에서는 세그먼트라는 용어롤 사용하지 않지만, 힙 구조 또는 인덱스 구조의 오브젝트가 여기에 속한다.
문제 3
Q. 데이터 변경 사항을 일단 데이터 버퍼 캐시에만 기록했다가 시간 간격을 두고 데이터 파일을 일괄 반영하려면 반드시 Redo(또는 Transaction) 로그의 도움이 필요하다. 그래야 DBMS에 문제가 발생하더라도 안전하게 복구할 수 있다. 이런 Redo 로그(또는 트랜잭션 로그) 매커니즘의 특징을 설명하는 여러 가지 용어가 있는데, 다음 중 아래와 관련된 것으로 가장 적절한 것은?
"버퍼 캐시 블록을 갱신하기 전에 변경사항을 먼저 로그 버퍼에 기록해야 하며, Dirty 버퍼를 디스크에 기록하기 전에 해당 로그 엔트리를 먼저 로그 파일에 기록해야 한다."
① Write Ahead Logging ② Log Force at Commit ③ Fast Commit ④ Delayed Block Cleanout
- Log Force at Commit : 로그 버퍼를 주기적으로 로그 파일에 기록하되, 늦어도 커밋 시점에는 반드시 기록해야 함.
- Fast Commit : 사용자의 갱신 내용이 메모리상의 버퍼 블록에만 기록된 채 아직 디스크에 기록되지 않았지만 Redo 로그를 믿고 빠르게 커밋을 완료하는 것
- Delayed Block Cleanout : 오라클만의 독특한 매커니즘으로서, 변경된 블록을 커밋 시점에 바로 Cleanout(로우 Lock 정보 해제, 커밋 정보 기록)하지 않고 그대로 두었다가 나중에 해당 블록을 처음 읽는 세션에 의해 정리되도록 하는 것
※ DB 버퍼 캐시에 가해지는 모든 변경 사항을 기록하는 파일을 Oracle은 'Redo 로그' 라고 부르며, SQL Server는 '트랜잭션 로그' 라고 부른다.
문제 4
Q. 다음 중 메모리 구조에 대한 설명으로 가장 부적절한 것은?
① DB 버퍼 캐시는 데이터 파일로부터 읽어 들인 데이터 블록을 담는 캐시 영역이다. ② /*+ append */ 힌트를 사용하면 Insert 시 DB 버퍼 캐시를 거치지 않고 디스크에서 직접 쓴다. ③ 클러스터링 팩터가 좋은 인덱스롤 사용하면 Buffer Pinning 효과로 I/O를 줄일 수 있다. ④ LRU(Least Recently Used) 알고리즘에 따라, Table Full Scan 한 데이터 블록이 Index Range Scan 한 데이터 블록보다 DB 버퍼 캐쉬에 더 오래 머무른다.
해설 :Response Time = Service Time + Wait Time = CPU Time + Queue Time
※ Response Time Analysis 방법론은 Time을 정의하고, CPU Time과 Wait Time을 각각 break down 하면서 서버의 일량과 대기 시간을 분석해 나간다. CPU Time 은 파싱 작업에 소비한 시간인지 아니면 쿼리 본연의 오퍼레이션 수행을 위해 소비한 시간인지를 분석한다. Wait Time 은 각각 발생한 대기 이벤트들을 분석해 가장 시간을 많이 소비한 이벤트 중심으로 해결 방안을 모색한다
문제 6
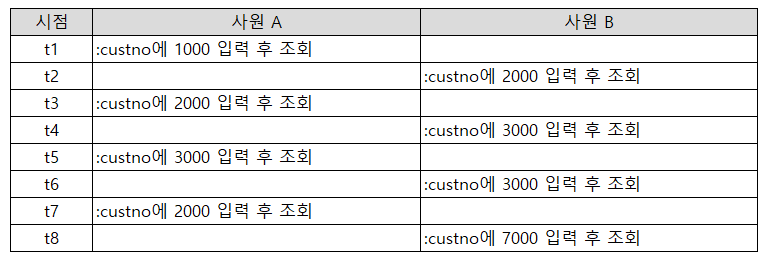
Q. DB 인스턴스를 가동한 직후, 아래 SQL1)을 포함하는 프로그램을 사원 A와 B가 아래와 같이 각각 4회씩 연속적으로 수행하였다. SQL1)에 대한 Hard Parsing은 몇 번 발생하겠는가?
SQL1)
select 고객명, 전화번호, 주소, 최종방문일시
from 고객
where 고객번호 = :custno
해설 :SQL 커서의 공유와 재사용성에 관한 문제이다. 캐싱된 SQL 커서는 반복 재사용할 수 있을 뿐만 아니라 여러 세션 간에 공유될 수 있다.
※ 소프트 파싱(Soft Parsing) : SQL과 실행 계획을 캐시에서 찾아 곧바로 실행 단계로 넘어가는 경우를 말함.
※ 하드 파싱(Hard Parsing) : SQL과 실행 계획을 캐시에서 찾지 못해 최적화 과정을 거치고 나서 실행 단계로 넘어가는 경우를 말함.
문제 7
Q. SQL *Plus나 TOAD 같은 쿼리 툴로 오라클 데이터베이스 ORDER 계정에 접속해서 아래 SQL을 각각 한번씩 순차적으로 실행했다. 다음 중 SQL 파싱에 대한 설명으로 가장 적절한 것은?
(1) select 고객번호, 고객명, 휴대폰번호 from 고객 where 고객명 like '010%';
(2) SELECT 고객번호, 고객명, 휴대폰번호 FROM 고객 WHERE 고객명 LIKE '010%';
(3) SELECT /* 고객조회 */ 고객번호, 고객명, 휴대폰번호 FROM 고객 WHERE 고객명 LIKE '010%';
① 첫 번째 수행될 때 각각 하드 파싱을 일으키고, 다른 캐시 공간을 사용할 것이다. ② 1번과 3번 SQL은 하드 파싱이 일어나지만, 2번은 하드 파싱이 일어나지 않는다. 즉, 1번 SQL과 공유된다. ③ 1번과 2번 SQL은 하드 파싱이 일어나지만, 3번은 하드 파싱이 일어나지 않는다. 즉, 2번 SQL과 공유된다. ④ 실행 계획이 서로 다를 수 있다
해설 :캐시에서 SQL과 실행 계획을 식별하는 식별자는 SQL 문장 그 자체이다. 따라서 옵티마이저는 문자 하나만 달라도 서로 다른 SQL로 인식해 각각 하드 파싱을 일으키고 다른 캐시 공간을 사용한다. 1~3번 SQL은 SQL Text가 서로 다르다. SQL Text가 달라 하드 파싱은 각각 일어나지만, 의미상 전혀 차이가 없으므로 실행 계획은 같다.
문제 8
Q. 공통 기술팀에서 개발 표준 업무를 담당하는 고성능 씨는 개발팀에 SQL 작성을 위한 표준 가이드라인을 제시했다. OLTP 환경의 시스템인 점을 고려해 가급적 바인드 변수를 사용하도록 권고하지만, "Literal 상수 조건을 사용하는 것이 더 낫거나 바인드 변수를 사용하려고 애쓰지 않아도 되는 경우"를 보기와 같이 제시했다. 다음 중 가장 부적절한 것은?
① 수행 빈도가 낮고 한 번 수행할 때 수십 초 이상 수행되는 SQL일 때 ② 조건절 칼럼의 값 종류(Distinct Value)가 소수이고, 값 분포가 균일하지 않을 때 ③ 사용자가 선택적으로 입력할 수 있는 조회 항목이 다양해서 조건절이 동적으로 바뀔 때 ④ 사용자가 입력할 수 있는 조회 항목이 아니어서 해당 조건절이 불변일 때
해설 :사용자의 입력 조건이 다양해서 조건절을 동적으로 구성하더라도 조건절 비교 값만큼은 바인드 변수를 사용하려고 노력해야 한다.
※ 바인드 변수(Bind Variable) : 파라미터 Driven 방식으로 SQL을 작성하는 방법이 제공되는데 SQL과 실행 계획을 여러 개 캐싱하지 않고 하나를 반복 재사용하므로 파싱 소요 시간과 메모리 사용량을 줄여준다.
문제 9
Q. 다음 중 프로그램을 아래와 같이 작성할 때의 문제점과 가장 거리가 먼 것을 2개 고르시오.
create function get_count(p_table varchar2, p_column varchar2, p_value varchar2)
return number
is
l_sql long;
l_count number;
begin
l_sql := 'select count(*) from ' || p_table;
if p_column is not null and p_value is not null then
l_sql := l_sql || 'where ' || p_column || ; = :1';
execute immediate l_sql
into l_count -- 쿼리 결과 값을 저장한다.
using p_value; -- 바인드 변수(:l)에 값을 입력한다.
else
execute immediate l-sql into l_count;
end if;
return l_count;
end get_count;
① 불필요한 하드 파싱을 많이 일으킨다. ② 테이블 통계 정보를 활용하지 못한다. ③ 인덱스 전략 수립이 어렵다. ④ 실행 계획을 제어하기 어렵다.
해설 :Dynamic SQL 방식으로 코딩했지만, 바인드 변수를 사용했으므로 불필요한 하드 파싱을 많이 일으킨다고 말하기는 어렵다. 바인드 변수를 사용했으므로 칼럼 히스토그램은 활용하지 못하지만, 레코드 건수, 칼럼 값의 종류(NDV), Null 값 개수 등을 활용해 실행 계획을 수립한다.
문제 10
Q. 다음 중 SQL 작성 방식에 대한 설명으로 가장 부적절한 것은?
① Static SQL이란, String형 변수에 담지 않고 코드 사이에 직접 기술한 SQL문을 말한다. ② Dynamic SQL이란, String형 변수에 담아서 실행하는 SQL문을 말한다. ③ Static SQL을 지원하는 개발 환경에선 가급적 Static SQL로 작성하는 것이 바람직하다. ④ 루프(Loop) 내에서 반복적으로 수행되는 SQL에 Dynamic SQL을 사용하면, 공유 메모리에 캐싱된 SQL을 공유하지 못해 하드 파싱이 반복적으로 일어난다.
해설 :바인드 변수를 사용하기만 하면 루프 내에서 반복 수행되는 SQL이더라도 캐싱된 SQL을 공유할 수 있다. 조건절을 바꾸지 않고 반복 수행하는 경우도 있으므로 4번 설명은 옳지 않다. Static SQL은 PreCompile 과정을 거치므로 런타임 시 안정적인 프로그램 빌드가 가능하다. 그리고 Dynamic SQL을 사용하면 애플리케이션 커서 캐싱이 작동하지 않는 경우가 있다. 따라서 Static SQL을 지원하는 개발 환경에서는 가급적 이 방식을 사용하는 것이 좋다.
728x90
문제 11
Q. 다음 중 데이터베이스 Call에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
① SELECT 문장을 수행할 땐 Execute, Parse, Fetch 순으로 Call이 발생한다. ② SELECT 문장에선 대부분 I/O가 Fetch Call 단계에서 일어난다. ③ Group By를 포함한 SELECT 문장에서 Group By 결과 집합을 만들기까지의 I/O는 Execute Call 단계에서, 이후 결과 집합을 전송할 때의 I/O는 Fetch Call 단계에서 일어난다. ④ INSERT, UPDATE, DELETE 문장에선 Fetch Call이 전혀 발생하지 않는다.
① SQL 파싱 부하가 최소화 되도록 프로그램을 효과적으로 작성하였다. ② Order By, Group By 등 데이터 정렬이 필요한 연산을 포함하지 않는 SQL 이다. ③ 실행할 때마다 평균적으로 200개 블록을 읽었고, 필요한 블록을 모두 버퍼 캐시에서 찾았다. ④ 매번 실행할 때 마다 비슷한 양의 결과 집합을 반환했다면, Array(=Fetch) Size는 100 정도로 설정한 상태였을 것이다.
해설 :제시된 Call Statistics만으로는 Order By 또는 Group By 연산의 포함 여부를 판단할 수 없다.
문제 13
Q. 다음 중 부분 범위 처리에 대한 설명으로 가장 부적절한 것은?
① 부분 범위 처리가 가능하도록 SQL올 작성하면 출력 대상 레코드가 많을수록 쿼리 웅답 속도도 그만큼 빨라진다. ② 「INSERT INTO … SELECT」 문장에서도 인덱스를 잘 활용하면 부분 범위 처리에 의한 성능 개선 효과를 얻을 수 있다. ③ Array 크기를 중가시키면 데이터베이스 Call 찾수가 감소한다. ④ Array 크기를 중가시키면 블록 I/O 횟수가 감소한다
해설 :모든 데이터 처리가 서버 내에서 이루어지는 프로그램에선 부분 범위 처리에 의한 성능 개선 효과가 나타나지 않는다.
문제 14
Q. 다음 중 사용자 정의 함수(User Defined Function)의 성능 특성에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
① SQL을 포함하는 형태의 사용자 정의 함수라면, 대용량 쿼리에 그것을 사용하는 순간 성능이 크게 저하된다. ② SQL을 포함하지 않는 형태의 사용자 정의 함수라면, 대용량 쿼리에 그것을 사용해도 성능에 큰 영향은 없다. ③ 작은 코드 테이블로부터 코드명을 가져오는 정도의 사용자 정의 함수라면, 코드명을 가져오기 위해 매번 조인하는 것보다 오히려 성능상 유리하다. ④ 성능이 중요하다면, 함수 안에서 또다른 함수를 Recursive하게 호출하는 형태는 지양해야 한다.
해설 :SQL을 포함하지 않는 형태의 사용자 정의 함수라도 문맥전환(Context Switch)에 의한 부하가 발생하므로 성능 저하가 발생한다. 작은 코드 테이블로부터 코드명을 가져오는 경우 사용자 정의 함수보다는 스칼라 서브 쿼리를 사용하여 캐싱 효과를 누리는 것이 성능상 유리하다.
※ 사용자 정의 함수/프로시저는 내장 함수처럼 Native 코드로 완전 컴파일된 형태가 아니어서 가상 머신(Virtual Machine) 같은 별도의 실행 엔진을 통해 실행된다. 실행될 때마다 문맥 교환(Context Switching)이 일어나며, 이 때문에 내장 함수(Built-In)를 호출할 때와 비교해 성능을 상당히 떨어뜨린다.
문제 15
Q. 다음 중 오라클에서 DB 저장형 함수(사용자 정의 함수)를 사용할 때 성능이 저하되는 원인과 거리가 가장 먼 것은?
①함수를 실행할 때마다 컴파일하는 부하 ② 가상머신(VM) 상에서 실행되므로 매번 바이트 코드를 해석하는 부하 ③ 쿼리 문장의 조회 건수만큼 함수를 반복적으로 호출하는 부하 ④함수에 내장된 쿼리가 있다면, 해당 문장을 Recursive하게 반복 수행하는 부하
select 고객명
from 고객
where 가입일자 = to_char(sysdate, 'yyyymmdd')
order by 고객명;
나)
select *
from 고객
where 가입일자 = to_char(sysdate, 'yyyymmdd')
order by 고객명;
① 클라이언트에게 데이터를 전송할 때 발생하는 네트워크 트래픽은 두 SQL 이 똑같다. ② 가입일자만으로 구성된 단일 칼럼 인덱스를 사용한다면, 두 SQL의 소트 공간 사용량은 똑같다. ③ 가입일자만으로 구성된 단일 칼럼 인덱스를 사용한다면, '나' 보다 '가' SQL에 블록 I/O 가 더 많이 발생한다. ④ {가입일자 + 고객명}을 선두로 갖는 인덱스를 사용한다면, '가' 보다 '나' SQL에 블록 I/O가 더 많이 발생한다
해설 : 가입일자, 고개명을 선두로 갖는 인덱스를 사용한다면 '가' SQL은 인덱스만 읽고 처리를 완료하므로 블록 I/O가 더 적게 발생한다. 가입일자만으로 구성된 단일 칼럼 인덱스를 사용한다면 두 SQL 모두 테이블 액세스가 불가피하므로 블록 I/O는 똑같다. '가' SQL은 소트 공간에 고객명만 저장하면 되지만, '나' SQL은 모든 칼럼을 저장해야 하므로 더 많은 소트 공간을 사용한다. '나' SQL을 수행하면 조건절을 만족하는 모든 칼럼을 클라이언트에게 전송해야 하므로 네트워크 트래픽이 더 많이 발생한다.
문제 17
Q. 다음 중 I/O 호율화 튜닝 방안으로 가장 부적절한 것은?
① 필요한 최소 블록만 읽도록 쿼리를 작성한다. ② 전략적인 인덱스 구상은 물론 DBMS가 제공하는 다양한 기능을 활용한다. ③ 옵티마이저 행동에 영향을 미치는 가장 중요한 요소는 통계 정보이므로 변경이 거의 없는 테이블일지라도 통계정보를 매일 수집해 준다. ④ 필요하다면, 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도한다.
① Random I/O는 인덱스를 통해 테이블을 액세스할 때 주로 발생한다. ② Direct Path I/O는 병렬로 인덱스를 통해 테이블을 액세스할 때 주로 발생한다. ③ Single Block I/O는 인덱스를 통해 테이블을 액세스할 때 주로 발생한다. ④ Multiblock I/O는 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 주로 발생한다.
해설 : Direct Path I/O는 일반적으로 병렬 쿼리로 Full Scan을 수행할 때 발생한다.
※ Single Block I/O : 한번의 I/O Call에 하나의 데이터 볼록만 읽어 메모리에 적재하는 방식 ※ MultiBlock I/O : I/O Call이 필요한 시점에 인접한 볼록들을 같이 읽어 메모리에 적재하는 방식
문제 19
Q. 다음 중 데이터베이스 I/O 원리를 설명한 것으로 가장 부적절한 것은?
① 한 쿼리 내에서 같은 블록을 반복적으로 액세스하면 버퍼 캐시 히트율(BCHR)은 높아진다. ② Multiblock I/O는 한번의 I/O Call로 여러 데이터 블록을 읽어 메모리에 적재하는 방식이다. ③ 테이블을 Full Scan할 때, 테이블이 작은 Extent로 구성되어 있을수록 더 많은 I/O Call이 발생한다. ④ 인덱스를 통해 테이블을 액세스할 때, 테이블이 큰 Extent로 구성되어 있으면 더 적은 I/O Call이 발생한다.
해설 :Multiblock I/O 방식으로 읽더라도 Extent 범위를 넘어서까지 읽지는 않는다. 따라서 작은 Extent로 구성된 테이블을 Full Table Scan 하면 I/O Call이 더 많이 발생한다. 반면, 인덱스를 통한 테이블 액세스 시에는 Single Block I/O 방식을 사용하므로 Extent 크기가 I/O Call 횟수에 영향을 미치지 않는다.
※ 버퍼 캐시 히트율(Buffer Cache Hit Ratio)
- 버퍼 캐시 효율을 측정하는 지표
- 전체 읽은 블록 중에서 메모리 버퍼 캐시에서 찾은 비율
- 물리적인 디스크 읽기를 수반하지 않고 곧바로 메모리에서 블록을 찾은 비율
문제 20
Q. 다음 중 데이터베이스 I/O 원리에 대한 설명으로 갖아 부적절한 것은?
① 단 하나의 레코드를 읽더라도 해당 레코드가 속한 블록을 통째로 읽는다. ② I/O를 수행할 때 익스텐트 내에 인접한 블록을 같이 읽어들이는 것을 'Multiblock I/O' 라고 한다. ③ 테이블 블록을 스캔(Scan)할 때는 Sequential I/O 방식을, 인덱스 블록을 스캔(Scan) 할 때는 Random I/O 방식을 사용한다. ④ MPP(Massively Parallel Processing) 방식의 데이터베이스 제품에선 각 프로세스가 독립적인 메모리 공간을 사용하며, 데이터를 저장할 때도 각각의 디스크를 사용한다. 읽을 때도 동시에 각각의 디스크를 액세스하기 때문에 병렬 I/O 효과가 극대화된다.
해설 : Sequential I/O 방식은 테이블이나 인덱스를 스캔할 때 사용한다. Random I/O 방식은 인덱스를 스캔하면서 테이블을 액세스할 때 사용한다. 요즘은 NAS 서버나 SAN가 보편적으로 사용되기 때문에 네트워크 I/O 성능에 큰 영향을 미친다. RAC 같은 클러스터링 데이터베이스 환경에선 메모리도 I/O 성능에 영향을 미친다.