728x90
넘파이 배열
넘파이 모듈 임포트
import numpy as np
넘파이 배열 생성
- 넘파이에서는 벡터(Vector)와 매트릭스(Matrics)를 배열(Array)이라고 한다.
- 벡터(Vector)의 의미
- 수학, 물리학
- 크기와 방향을 가지는 기하학적 양 또는 객체
- 넘파이
- 1차원 배열
- 2차원 이상의 배열을 매트릭스라고 한다.
- 수학, 물리학
- 벡터(Vector)의 의미
배열을 생성하는 방법
- 리스트(List), 튜플(Tuple) 등 다른 파이썬 자료 구조에서 변환
- arange(), ones(), zeros(), linspace() 등 넘파이 고유의 배열 생성 함수 사용
- 저장 디스크에서 배열을 읽어들임.
- 문자열이나 버퍼를 통한 바이트 스트림 데이터인 Raw Bytes 에서 배열 생성
- random() 함수와 같은 특수한 라이브러리 함수 사용
넘파이에서의 배열
- 넘파이에서 제공되는 새로운 데이터 타입인 배열은 리스트와 유사하다.
- 그러나 리스트가 같은 타입의 요소만 가질 수 있는 반면, 배열은 다른 타입이나 객체도 요소로 가질 수 있다.
- 이런 점에서 배열은 요소를 연산하고 저장하기에 더 효율적이다.
- 논리적이고 통계적인 연산과 푸리에 변환 같은 연산을 매우 효율적으로 처리할 수 있다.
- 파이썬의 리스트보다 많은 데이터를 처리할 수 있다.
- 리스트에서 사용할 수 없는 기능이나 방법들을 다양한 라이브러리를 이용해 처리할 수 있다.
- 머신러닝에서 사용되는 주요 데이터 구조이다.
파이썬 유사 배열 객체를 넘파이 배열로 변환
- 파이썬
- 배열 데이터 구조가 없으며, 리스트를 이용해 유사 배열(Array-Like)을 만든다.
- 넘파이
- numpy.array() 함수를 이용해 리스트로 배열을 생성하고, 효율적으로 연산할 수 있다.
- numpy.array() 함수에서 매개 변수로 입력되는 리스트 배열을 유사 배열이라고 한다.
- 유사 배열인 리스트 데이터를 입력해 처리한 결과가 넘파이 배열이 되며, 이 배열은 ndarray 객체이다.
- 파이썬의 데이터 타입인 리스트 데이터를 입력하여 넘파이 배열을 생성하는 형태
- 유사 배열인 리스트 데이터를 입력해 처리한 결과가 넘파이 배열이 되며, 이 배열은 ndarray 객체이다.
arr = numpy.array([유사 배열])
1차원 배열 생성
리스트(List) 형태로 출력하기
arr1 = np.array([0, 2, 5.5, 7])
print(arr1) # List 형태로 출력더보기
[0. 2. 5.5 7. ]- print() 함수를 사용하여 넘파이 배열을 출력할 경우, 리스트(List) 형태로 출력이 된다.
배열(Array) 형태로 출력하기
arr1 = np.array([0, 2, 5.5, 7])
arr1 # Array 형태로 출력더보기
array([0. , 2. , 5.5, 7. ])- 넘파이 배열을 직접 출력할 경우, 배열(Array) 형태로 출력이 된다.
2차원 배열 생성
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
arr2더보기
array([[1, 2, 3],
[4, 5, 6]])
- 넘파이 배열은 같은 타입의 값들을 포함하는 그리드(Grid) 형태를 띄며, 타입은 ndarray 객체이다.
- N Dimensional Array
- ndarray의 특성은 메모리 주소, 데이터 타입, shape 및 strides 의 조합이다.
넘파이 고유의 배열 생성 함수
- 넘파이는 배열을 생성하는 고유한 내장 함수들을 포함한다.
① numpy.zeros()
- 값이 0으로 채워지는 배열을 생성
arr = np.zeros(5)
arr더보기
array([0., 0., 0., 0., 0.])- 요소가 0이면서 5개인 배열 객체가 생성된다.
type(arr) # 타입 출력더보기
numpy.ndarray- 생성된 배열 객체가 ndarray 타입의 객체임을 확인할 수 있다.
arr.shape # 차원 출력더보기
(5,)- 1차원 배열로, 요소가 5개라는 의미
- (1, 5) 와 같은 의미
- 참고
# 2차원 배열
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15]])
arr.shape(5, 3)
# 3차원 배열
arr = np.array([[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]],
[[13, 14, 15], [16, 17, 18]]
])
arr.shape(3, 2, 3)
arr = np.zeros(shape=(6, 2)) # 6행 2열의 배열 생성
for i in range(6):
arr[i] = (i, i)
arr더보기
array([[0., 0.],
[1., 1.],
[2., 2.],
[3., 3.],
[4., 4.],
[5., 5.]])- 매개변수 shape 에는 튜플형인 정수를 입력할 수 있다.
② numpy.ones()
- 값이 1로 채워지는 배열을 생성
- 매개변수 shape 에는 튜플형인 정수를 입력할 수 있다.
np.ones(5) # 요소값이 1이고, 5개인 1차원 배열 생성더보기
array([1., 1., 1., 1., 1.])- 요소가 1이면서 5개인 1차원 배열 객체가 생성된다.
np.ones((5,), dtype=int)더보기
array([1, 1, 1, 1, 1])- 요소가 1이면서 5개인 1차원 배열 객체가 생성된다.
- 각 요소의 자료형은 정수형(int)이다.
np.ones((3, 4)) # 요소값이 1이고, 3행 4열인 2차원 배열 생성더보기
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
arr.dtype # 배열의 자료형 출력더보기
dtype('float64')
③ numpy.empty()
- 초기화되지 않은 임의의 값들로 배열을 생성
- 초기화 함수 중 가장 빠르게 처리된다.
np.empty((2, 2))더보기
array([[1.33042158e-311, 1.33040420e-311 ],
[0.00000000e+000, 1.06099790e-314]])
np.empty((2, 2), dtype=int)더보기
array([[ 7929940, 6619248],
[-130307808, 626]])
④ numpy.eye()
- 대각선에는 값 1, 그 밖의 위치에 값 0을 가지는 n × n 배열을 생성하는 함수
- 정방 행렬(단위 행렬)을 출력해주는 함수
- $\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}$
- 실행 결과는 2차원 배열이다.
- n(정수)를 입력값으로 가지며. n열 n행인 배열 객체를 생성한다.
np.eye(3, dtype=int)더보기
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]])
np.eye(3, k=1)더보기
array([[0., 1., 0.],
[0., 0., 1.],
[0., 0., 0.]])- 대각선을 기준으로, 1단계 위로 1이 배치된다.
- k에 -2를 입력하면 대각선 기준 2단계 아래로 1이 배치된다는 의미이다.
⑤ numpy.linspace()
- 명시된 간격으로 균등하게 분할된 값을 반환하는 함수
np.linspace(2.0, 3.0, num=5)더보기
array([2. , 2.25, 2.5 , 2.75, 3. ])- 2.0과 3.0 사이에 5개의 수들을 균등하게 생성
np.linspace(2.0, 3.0, num=5, endpoint=False)더보기
array([2. , 2.2, 2.4, 2.6, 2.8])- 2.0과 3.0 사이에 5개의 수들을 균등하게 생성, 하지만 끝점은 포함하지 않음.
배열 생성 함수 numpy.arange()
- 배열을 생성하는 arange() 함수에는 [시작, 끝) 인 범위값을 입력한다.
- 시작값은 포함하고, 끝값은 포함하지 않는다.
numpy.arange(시작값, 끝값, [증분값])
arr = np.arange(5)
arr더보기
array([0, 1, 2, 3, 4])
np.arange(3, 7)더보기
array([3, 4, 5, 6])
arr.shape더보기
(5,)
np.arange(3, 9, 2) # 증분 : 2더보기
array([3, 5, 7])
arr[2] = 10
arr더보기
array([ 0, 1, 10, 3, 4])- 넘파이 배열 값을 변경할 때는 먼저 값을 초기화한 후 변경해야 한다.
arr[3] = 'jin'더보기
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_22576/2453786679.py in <module>
----> 1 arr[3] = 'jin'
ValueError: invalid literal for int() with base 10: 'jin'- 넘파이 배열은 동종 배열(Homogeneous Array)이기 때문에 자료형이 다른 요소들을 한 배열에 넣을 수 없다.
- arange() 함수를 사용하면 1차원 배열만 생성하지만, reshape() 함수를 함께 사용하면 2차원 배열을 생성할 수 있다.
- reshape() 함수는 데이터를 변경하지 않고, 배열을 새로운 shape 로 변형시킨다.
arr = np.arange(12).reshape(3, 4)
arr더보기
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])- arange() 함수로 12개의 요소를 1차원으로 생성한 배열을 reshape() 함수로 3행, 4열인 2차원 배열로 변경한다.
- 생성된 배열 arr의 타입은 ndarray 객체이다.
arr.shape더보기
(3, 4)- 배열 arr이 (3, 4) shape 인 튜플형임을 확인할 수 있다.
- reshape() 함수의 매개 변수에 -1을 입력할 경우, 다차원 배열을 1차원 배열로 변경하여 반환한다.
- ravel() 함수와 같다.
- 다차원 배열을 1차원 배열로 정렬하는 함수
- numpy.ndarray.ravel 과 numpy.ravel 2종류의 객체가 있다.
- ravel() 함수와 같다.
arr.reshape(-1)
더보기
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
- ravel() 함수를 사용한 것과 결과값이 같다.
arr.ravel()
arr.reshape(-1, 1)더보기
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10],
[11]])- -1은 행, 1은 열을 의미한다.
- arr 배열인 12개 값으로 행은 -1로 알 수 없고, 1열인 배열을 생성하라는 의미이다.
arr.reshape(3, -1)더보기
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])- 3은 행, -1은 열을 의미한다.
- arr 배열인 12개 값으로 열은 -1로 알 수 없고, 3행인 배열을 생성하라는 의미이다.
arr.reshape(-1, -1)더보기
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: can only specify one unknown dimension- (-1, -1)을 입력하면 오류가 발생한다.
- 3차원 배열을 생성하기 위해서는 reshape() 함수에 매개 변수 3개가 필요하다.
arr = np.arange(24).reshape(2, 3, 4)
arr더보기
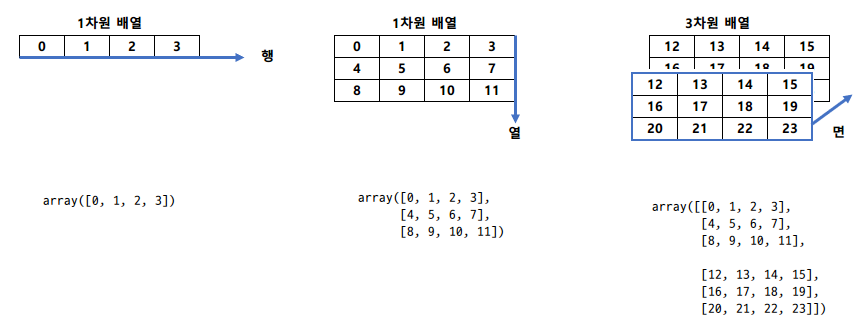
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])- 2는 면(Depth), 3은 행, 4는 열을 의미한다.
- 2 × 3 × 4 = 24
디스크에서 읽어서 배열 생성
- 커다란 배열을 생성하는 일반적인 방법
- 디스크에 있는 데이터 타입에 크게 의존한다.
- HDF5, FITS, CSV 파일 등을 라이브러리를 이용하여 읽어들일 수 있다.
넘파이 ndarray 클래스
- 넘파이는 2개의 주요 객체인 다차원 배열 객체 ndarray와 유니버셜 함수 객체인 ufunc를 지원한다.
- 그리고 이 두 객체를 중심으로 관련된 다른 객체들로 구성된다.
- 배열 타입인 ndarray는 같은 타입의 요소들을 모아 놓은 다차원 객체이다.
- 정수 인덱스를 통해 ndarray 안에 있는 요소들에 접근할 수 있다.
arr = np.array([[0, 1, 2],
[3, 4, 5]])
type(arr)더보기
<class 'numpy.ndarray'>
arr.shape더보기
(2, 3)
arr.dtype더보기
dtype('int32')
ndarray 객체 구조
- ndarray 클래스는 같은 타입과 크기인 요소를 담고 있는 다차원 컨테이너이다.
- 배열의 shape와 배열이 구성되는 요소 타입(dtype)으로 ndarray 객체를 정의한다.
- shape
- 각 차원에서 N 정수의 튜플형
- 인덱스가 얼마나 변하는지에 대한 정보 제공
- 요소의 타입
- 데이터 타입 객체인 dtype 속성으로 확인할 수 있다.
- shape
- ndarray 클래스는 같은 데이터 타입의 요소를 모아 놓은 곳이므로, 모든 요소는 같은 크기의 메모리 블록을 가지며 인터프리터가 배열의 메모리 블록을 동일한 방법으로 처리한다.

- dtype은 array, scalar 타입 객체를 가리키고, 데이터 타입 객체와 ndarray의 관련 요소를 사용한 배열 스칼라가 반환된다.

- ndarray는 인접하는 블록의 C(행) 우선 또는 F(열) 우선 형태로 부호화되어 저장된다.
- 이러한 데이터 처리 방식은 C 언어와 포트란(Fortran) 데이터 실행 방식에서 유래한 것이다.
- C 우선 : C 언어
- F 우선 : 포트란
- 이러한 데이터 처리 방식은 C 언어와 포트란(Fortran) 데이터 실행 방식에서 유래한 것이다.
arr = np.array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
arr더보기
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
arr.ndim # 차원 확인더보기
3- 대괄호([ ])가 3겹으로 쌓여 있으므로 3차원이라고 생각할 수 있다.
arr.size # 전체 요소의 개수 반환더보기
24- 4 × 6 = 24
arr.shape더보기
(2, 3, 4)
arr.dtype더보기
dtype('int32')
arr.itemsize더보기
4- arr 배열의 크기는 4바이트이다.
- 1바이트는 8비트이므로, arr 배열 요소의 크기는 32비트(4×8), 즉 int32 이다.
arr.strides # 배열의 요소 크기와 배치 확인더보기
(48, 16, 4)- 열에서 다음 열로 이동하려면 4바이트, 행에서 다음 행으로 이동하려면 16(4×4)바이트, 그리고 면에서 다음 면으로 이동하려면 48(16×3)바이트가 필요함을 알 수 있다.
넘파이 배열의 데이터 타입
- 넘파이 배열은 데이터 타입 객체로 생성하는 모든 요소를 포함하며, 이때 요소의 데이터 타입은 동일하다.
numpy.dtype 적용
- numpy.dtype 클래스의 인스턴스인 데이터 타입 객체는 고정 크기인 메모리 블록에서 바이트가 어떻게 해석되는지에 따라 다음과 같은 사항들을 나타낸다.
- 데이터 타입(정수, 실수, 파이썬 객체 등) 및 크기
- 메모리에 저장된 데이터의 바이트 순서
- LSB(Least Significant Bit)
- Little-Endian 이라고 불림.
- 가장 낮은 위치인 가장 오른쪽에 위치하는 비트
- MSB(Most Significant Bit)
- Big-Endian 이라고 불림.
- 가장 높은 위치인 가장 왼쪽에 위치하는 비트
-
MSB LSB
- LSB(Least Significant Bit)
- 아래를 포함하는 구조화된 데이터라면 배열 요소의 데이터 타입에 대해 다음 사항을 입력
- 구조화된 데이터의 필드 이름(이 이름으로 필드에 접근)
- 각 필드의 데이터 타입
- 각 필드가 위치하는 메모리 블록의 어느 부분
- 데이터 타입이 서브 배열인 경우, 그 shape와 데이터 타입
- numpy.dtype 클래스는 스칼라인 배열 요소를 반환한다.
- 이러한 배열 스칼라는 파이썬 스칼라와 다르지만, 대부분 서로 호환하여 사용할 수 있다.
- 배열 스칼라는 ndarrays 객체와 같은 속성과 메서드를 갖지만, 요소를 변경할 수 없는(immutable) 특징이 있어 어떤 속성도 설정할 수 없다.
- 넘파이는 스칼라 데이터의 타입을 설명하기 위해 다양한 정밀도의 정수, 실수 등이 내장된 몇몇 스칼라형을 제공한다.
| 넘파이의 배열 스칼라형 | 파이썬의 관련된 타입 |
| Int_ | IntType (파이썬2) |
| float_ | FloatType |
| complex_ | ComplexType |
| bytes_ | BytesType |
| unicode_ | UnicodeType |
- numpy.dtypes 클래스는 np.float32, np.int_, np.uint16, np.bool_ 등의 타입으로 이루어진다.
- 이 데이터 타입은 수치를 배열 스칼라로 변환하는 함수로써 사용할 수 있고, dtype 키워드의 인수로 사용할 수도 있다.
>>> a = np.float32(5.0)
>>> a
5.0
>>> type(a)
<class 'numpy.float32'>
>>> b = np.int_([1, 2, 3])
>>> b
array([1, 2, 3])
>>> type(b)
<class 'numpy.ndarray'>
>>> c = np.arange(5, dtype=np.uint16)
>>> c
array([0, 1, 2, 3, 4], dtype=uint16)
>>> type(c)
<class 'numpy.ndarray'>
- 배열 데이터 타입 객체의 체계

- 배열 데이터 타입 분류
| 타입 구분 | 문자 코드 | 주요 내용 | |
| 불리언 | bool_ | '?' | 파이썬 bool과 호환 |
| bool8 | 8비트 | ||
| 정수 | byte | 'b' | C 언어 char와 호환 |
| short | 'h' | C 언어 short와 호환 | |
| intc | 'i' | C 언어 int와 호환 | |
| Int_ | 'l' | 파이썬 int와 호환 | |
| longlong | 'q' | C 언어 long long과 호환 | |
| intp | 'p' | signed 타입의 포인터와 같은 크기의 정수형 | |
| int8 | 8비트, $-2^{7} \sim (2^{7}-1)$ | ||
| int16 | 16비트, $-2^{15} \sim (2^{15}-1)$ | ||
| int32 | 32비트, $-2^{31} \sim (2^{31}-1)$ | ||
| int64 | 64비트, $-2^{63} \sim (2^{63}-1)$ | ||
| Unsigned Integers | ubyte | 'B' | C 언어 unsigned char와 호환 |
| ushort | 'H' | C 언어 unsigned short와 호환 | |
| uintc | 'I' | C 언어 unsigned int와 호환 | |
| uint | 'L' | 파이썬 int와 호환 | |
| ulonglong | 'Q' | C 언어 long long과 호환 | |
| uintp | 'P' | unsigned 타입의 포인터와 같은 크기의 정수형 | |
| uint8 | 8비트, $0 \sim (2^{8}-1)$ | ||
| uint16 | 16비트, $0 \sim (2^{16}-1)$ | ||
| uint32 | 32비트, $0 \sim (2^{32}-1)$ | ||
| uint64 | 64비트, $0 \sim (2^{64}-1)$ | ||
| 실수 | half | 'e' | - |
| single | 'f' | C 언어 float와 호환 | |
| double | C 언어 double과 호환 | ||
| float_ | 'd' | 파이썬 float와 호환 | |
| longfloat | 'g' | C 언어 long float와 호환 | |
| float16 | 16비트 | ||
| float32 | 32비트 | ||
| float64 | 64비트 | ||
| float96 | 96비트, 운용 체계 및 언어에 따라 호환되지 않을 수 있음. | ||
| float128 | 128비트, 운용 체계 및 언어에 따라 호환되지 않을 수 있음. | ||
| 복소수 | csingle | 'F' | - |
| complex_ | 'D' | 파이썬 complex와 호환 | |
| clongfloat | 'G' | - | |
| complex64 | 2개의 32비트 실수 | ||
| complex128 | 2개의 64비트 실수 | ||
| complex192 | 2개의 96비트 실수 | ||
| complex256 | 2개의 128비트 실수, 언어에 따라 호환되지 않을 수 있음. | ||
| 파이썬 객체 | object_ | 'O' | 데이터는 파이썬 객체를 참조 |
| 기타 | bytes_ | 'S#' | 파이썬 bytes와 호환 |
| unicode_ | 'U#' | 파이썬 unicode/str과 호환 | |
| void | 'V#' | - | |
- 인덱싱으로 추출한 배열의 요소는 배열 데이터 타입과 관련된 파이썬 객체인 스칼라형이다.
- 어떤 데이터 타입을 생성하면 구조화된 데이터 타입이 형성된다.
- 이때 생성된 데이터 타입의 필드는 다른 데이터 타입을 포함하여 계층 구조를 형성한다.
- 각 필드는 이름을 가지고 있으며, 이 이름을 이용해 필드에 접근할 수 있다.
- 부모 격 데이터 타입은 계흥화된 모든 필드를 포함할 정도로 충부한 크기여야 한다.
- 또한, 부모 격 데이터의 기본 타입은 임의의 배열 요소 크기를 허용하는 void 타입이다.
- 구조화된 데이터 타입의 필드 안에는 구조화된 서브배열 데이터 타입들도 포함될 수 있다.
- 이때 생성된 데이터 타입의 필드는 다른 데이터 타입을 포함하여 계층 구조를 형성한다.
- Big-Endian의 32비트의 정수를 가지는 데이터 타입
>>> dt = np.dtype('>i4')
>>> dt.byteorder
'>'
>>> dt.name
'int32'
>>> dt.itemsize
4
>>> dt.type is np.int32
True
- 16문자 string을 포함하는 구조화 데이터 타입과 2개의 64비트 서브 배열(sub_array)
- 데이터 순서를 LSB인 최소 유효 바이트로 처리했다는 뜻이다.
>>> dt = np.dtype([('name', np.unicode_, 16), ('grades', np.float64, (2,))])
>>> dt['name']
dtype('<U16')
>>> dt['grades']
dtype(('<f8', (2,)))
728x90
'In-depth Study > NumPy' 카테고리의 다른 글
| [NumPy] 넘파이 적용 (0) | 2022.04.14 |
|---|---|
| [NumPy] 배열 객체 관리와 연산 (0) | 2022.04.13 |
| [NumPy] 구조화된 배열 (0) | 2022.04.13 |
| [NumPy] 넘파이(NumPy) 개요 (0) | 2022.04.13 |

